Python网络爬虫-爬取微博热搜
微博热搜的爬取较为简单,我只是用了lxml和requests两个库
url=https://s.weibo.com/top/summary?Refer=top_hot&topnav=1&wvr=6
1.分析网页的源代码:右键--查看网页源代码.
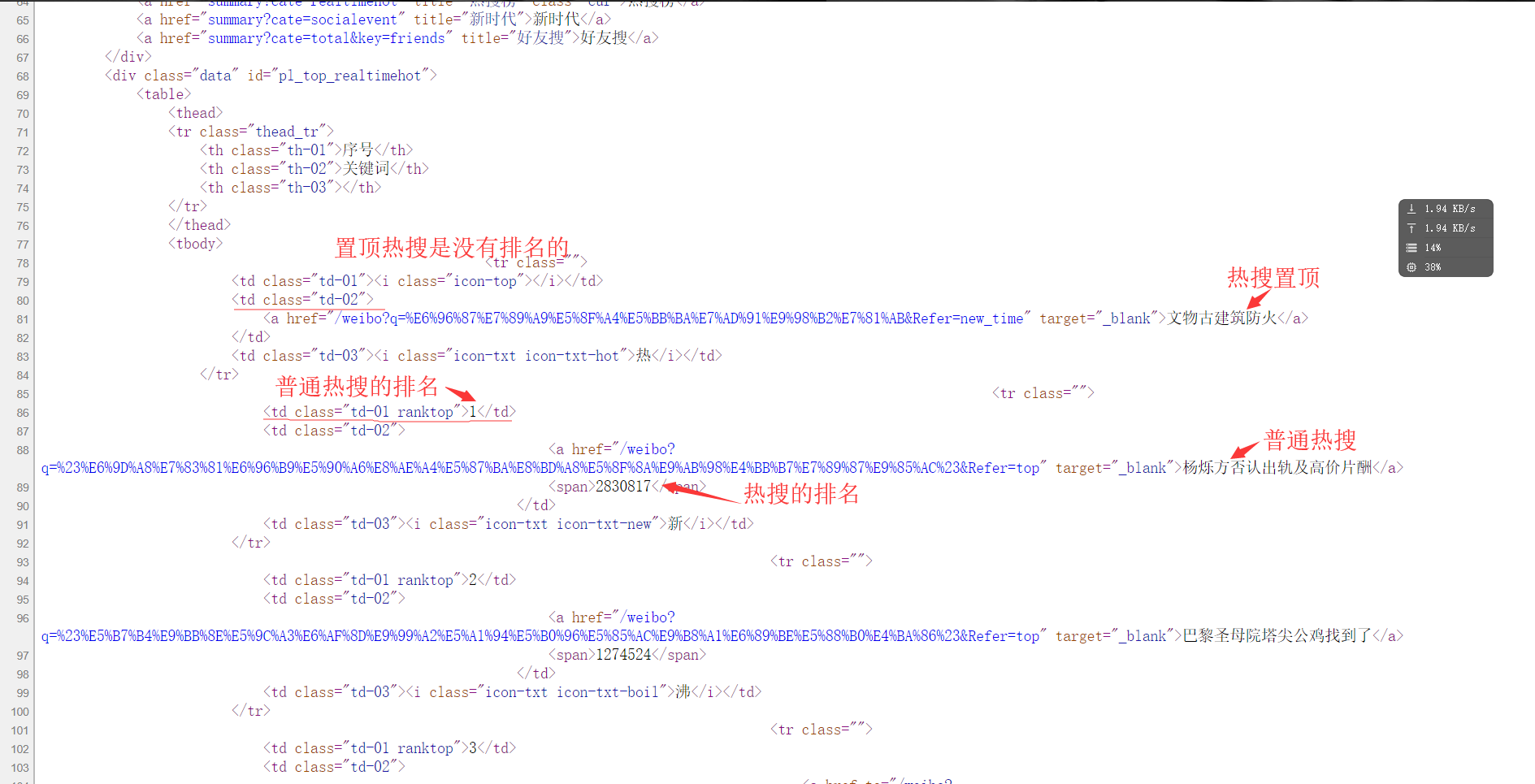
从网页代码中可以获取到信息
(1)热搜的名字都在<td class="td-02">的子节点<a>里
(2)热搜的排名都在<td class=td-01 ranktop>的里(注意置顶微博是没有排名的!)
(3)热搜的访问量都在<td class="td-02">的子节点<span>里
2.requests获取网页
(1)先设置url地址,然后模拟浏览器(这一步可以不用)防止被认出是爬虫程序。
###网址
url="https://s.weibo.com/top/summary?Refer=top_hot&topnav=1&wvr=6"
###模拟浏览器,这个请求头windows下都能用
header={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36'}
(2)利用requests库的get()和lxml的etree()来获取网页代码
###获取html页面
html=etree.HTML(requests.get(url,headers=header).text)
3.构造xpath路径
上面第一步中三个xath路径分别是:
affair=html.xpath('//td[@class="td-02"]/a/text()')
rank=html.xpath('//td[@class="td-01 ranktop"]/text()')
view=html.xpath('//td[@class="td-02"]/span/text()')
xpath的返回结果是列表,所以affair、rank、view都是字符串列表
4.格式化输出
需要注意的是affair中多了一个置顶热搜,我们先将他分离出来。
top=affair[0]
affair=affair[1:]
这里利用了python的切片。
print('{0:<10}\t{1:<40}'.format("top",top))
for i in range(0, len(affair)):
print("{0:<10}\t{1:{3}<30}\t{2:{3}>20}".format(rank[i],affair[i],view[i],chr(12288)))
这里还是没能做到完全对齐。。。 5.全部代码
###导入模块
import requests
from lxml import etree ###网址
url="https://s.weibo.com/top/summary?Refer=top_hot&topnav=1&wvr=6"
###模拟浏览器
header={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36'} ###主函数
def main():
###获取html页面
html=etree.HTML(requests.get(url,headers=header).text)
rank=html.xpath('//td[@class="td-01 ranktop"]/text()')
affair=html.xpath('//td[@class="td-02"]/a/text()')
view = html.xpath('//td[@class="td-02"]/span/text()')
top=affair[0]
affair=affair[1:]
print('{0:<10}\t{1:<40}'.format("top",top))
for i in range(0, len(affair)):
print("{0:<10}\t{1:{3}<30}\t{2:{3}>20}".format(rank[i],affair[i],view[i],chr(12288)))
main()
结果展示:

Python网络爬虫-爬取微博热搜的更多相关文章
- 如何利用Python网络爬虫爬取微信朋友圈动态--附代码(下)
前天给大家分享了如何利用Python网络爬虫爬取微信朋友圈数据的上篇(理论篇),今天给大家分享一下代码实现(实战篇),接着上篇往下继续深入. 一.代码实现 1.修改Scrapy项目中的items.py ...
- 利用Python网络爬虫爬取学校官网十条标题
利用Python网络爬虫爬取学校官网十条标题 案例代码: # __author : "J" # date : 2018-03-06 # 导入需要用到的库文件 import urll ...
- nodejs实现定时爬取微博热搜
The summer is coming " 我知道,那些夏天,就像青春一样回不来. - 宋冬野 青春是回不来了,倒是要准备渡过在西安的第三个夏天了. 废话 我发现,自己对 coding 这 ...
- 如何用Python网络爬虫爬取网易云音乐歌曲
今天小编带大家一起来利用Python爬取网易云音乐,分分钟将网站上的音乐down到本地. 跟着小编运行过代码的筒子们将网易云歌词抓取下来已经不再话下了,在抓取歌词的时候在函数中传入了歌手ID和歌曲名两 ...
- 04 Python网络爬虫 <<爬取get/post请求的页面数据>>之requests模块
一. urllib库 urllib是Python自带的一个用于爬虫的库,其主要作用就是可以通过代码模拟浏览器发送请求.其常被用到的子模块在Python3中的为urllib.request和urllib ...
- BeautifulSoup爬取微博热搜榜
获取url 设定请求头 requests发出get请求 实例化BeautifulSoup对象 BeautifulSoup提取数据 import requests 2 from bs4 import B ...
- python网络爬虫&&爬取网易云音乐
#爬取网易云音乐 url="https://music.163.com/discover/toplist" #歌单连接地址 url2 = 'http://music.163.com ...
- Python网络爬虫 - 爬取中证网银行相关信息
最终版:07_中证网(Plus -Pro).py # coding=utf-8 import requests from bs4 import BeautifulSoup import io impo ...
- Python爬取微博热搜以及链接
基本操作,不再详述 直接贴源码(根据当前时间创建文件): import requests from bs4 import BeautifulSoup import time def input_to_ ...
随机推荐
- vue --》watch 深度监听的优化。
话不多说,直接上代码,注释很清楚 <template> <div> <input type="text" v-model="value&qu ...
- 编码总结一:Java默认字符集
(一)JVM默认字符集——Charset.defaultCharset() 获取Java虚拟机默认字符集,该字符集默认跟操作系统字符集一致,也可以通过-Dfile.encoding="GBK ...
- heaplog
#ifdef _DEBUG #include <stdio.h> #include <stdlib.h> #include <string.h> #define _ ...
- 史上最全的ORACLE基础教程
ORACLE命令和语句挺多,全部记忆下来不现实,况且有不常用的指令.下面把大部分的指令做了记录和详细的注释.建议收藏.转发此篇文章,如果忘记可以翻出来查查.关注公众号it_learn获取更多学习资源 ...
- Android之异步调用
概述 AsyncTask可以很好的,准确的使用UI线程,他可以将一个比较耗时(几秒钟)的动作运行在后台,并且能将结果返回至UI线程中,不需要通过(Thread操作和Handler操作). 使用时必须通 ...
- IDEA创建SpringBoot+maven项目
1.创建项目: 2.选择spring Initializr,注意要选择jdk,使用默认的spring.io这样就不用再去写pom文件了 3.输入项目名称: 4.选择Spring Web 5.目录结构:
- [2019杭电多校第五场][hdu6629]string matching(扩展kmp)
题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=6629 题意求字符串的每个后缀与原串的最长公共前缀之和. 比赛时搞东搞西的,还搞了个后缀数组...队友一 ...
- 洛谷P4391 [BOI2009]Radio Transmission 无线传输
(https://www.luogu.org/problemnew/show/P4391) 题目描述 给你一个字符串,它是由某个字符串不断自我连接形成的. 但是这个字符串是不确定的,现在只想知道它的最 ...
- 哪吒票房超复联4,100行python代码抓取豆瓣短评,看看网友怎么说
<哪吒之魔童降世>这部国产动画巅峰之作,上映快一个月时间,票房口碑双丰收. 迄今已有超一亿人次观看,票房达到42.39亿元,超过复联4,跻身中国票房纪录第三名,仅次于<战狼2> ...
- React手稿 - Context
Context Context提供了除props之外的传参数的方式. Context是全局跨组件传递数据的. API React.createContext ``` const {Provider, ...