Hive数据导入Elasticsearch
Elasticsearch Jar包准备
所有节点导入elasticsearch-hadoop-5.5.1.jar
/opt/cloudera/parcels/CDH-5.12.0-1.cdh5.12.0.p0.29/lib/hive/lib/elasticsearch-hadoop-5.5.1.jar
HDFS导入数据准备
hdfs dfs -ls /user/logb/464/part-r-00000
进入HIVE shell 执行
引用Elasticsearch jar包进行hive界面
hive -hiveconf hive.aux.jars.path=file:///usr/local/elasticsearch/elasticsearch-hadoop-5.5.1.jar
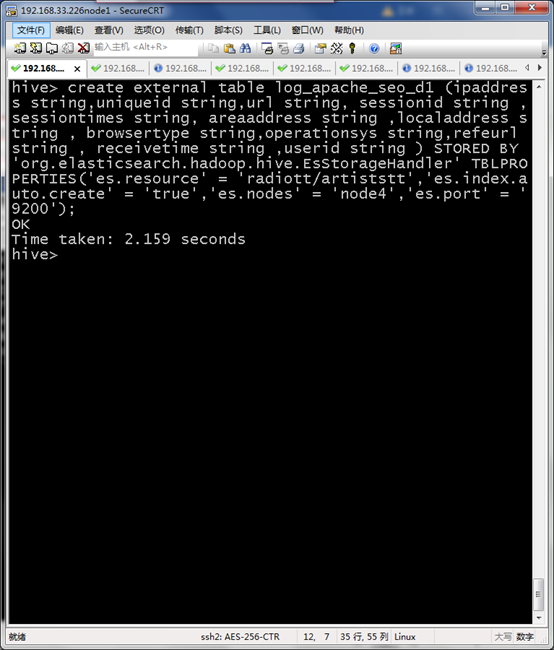
创建与Elasticsearch对接log_apache_seo_d1外部表
create external table log_apache_seo_d1 (ipaddress string,uniqueid string,url string, sessionid string ,sessiontimes string, areaaddress string ,localaddress string , browsertype string,operationsys string,refeurl string , receivetime string ,userid string ) STORED BY 'org.elasticsearch.hadoop.hive.EsStorageHandler' TBLPROPERTIES('es.resource' = 'radiott/artiststt','es.index.auto.create' = 'true','es.nodes' = 'node4','es.port' = '9200');
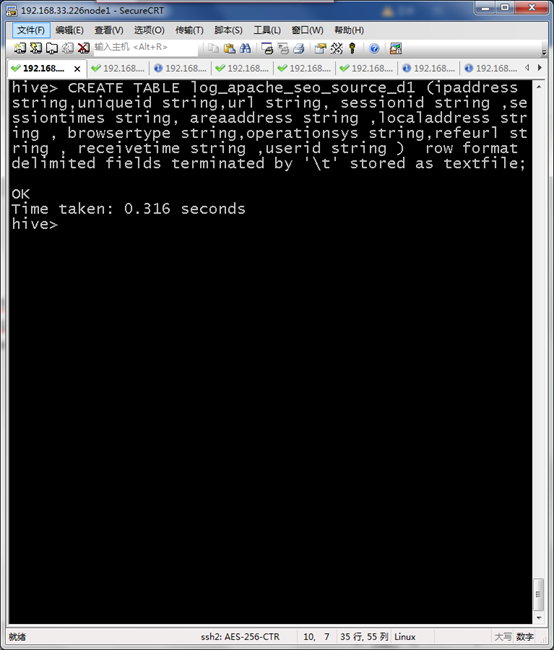
创建源数据表log_apache_seo_source_d1
CREATE TABLE log_apache_seo_source_d1 (ipaddress string,uniqueid string,url string, sessionid string ,sessiontimes string, areaaddress string ,localaddress string , browsertype string,operationsys string,refeurl string , receivetime string ,userid string ) row format delimited fields terminated by '\t' stored as textfile;
加载MR结果到HIVE
load data inpath '/user/logb/464/part-r-00000' into table log_apache_seo_source_d1 ;

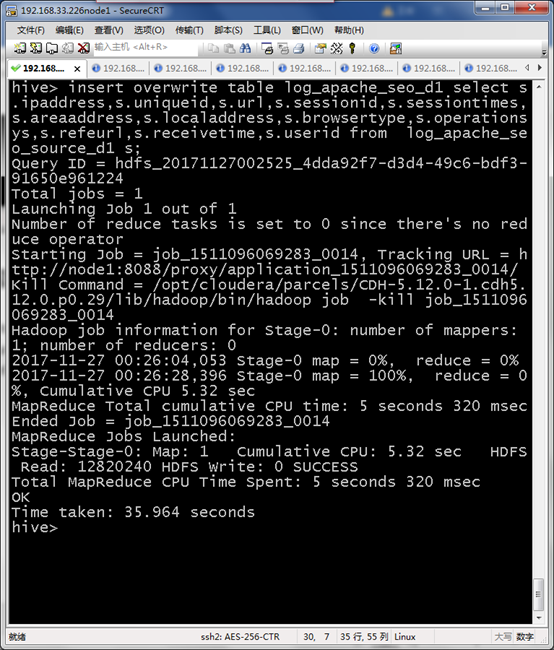
将HIVE数据加载到Elasticsearch所需表中
insert overwrite table log_apache_seo_d1 select s.ipaddress,s.uniqueid,s.url,s.sessionid,s.sessiontimes,s.areaaddress,s.localaddress,s.browsertype,s.operationsys,s.refeurl,s.receivetime,s.userid from log_apache_seo_source_d1 s;
编写shell脚本
#!/bin/sh
# upload logs to hdfs
hive -e "
set hive.enforce.bucketing=true;
set hive.exec.compress.output=true;
set mapred.output.compress=true;
set mapred.output.compression.codec=org.apache.hadoop.io.compress.GzipCodec;
set io.compression.codecs=org.apache.hadoop.io.compress.GzipCodec;
load data inpath '/user/logb/464/part-r-00000' into table log_apache_seo_source_d1 ;
"
执行脚本任务
0 */2 * * * /opt/bin/hive_opt/crontab_import.sh
Hive数据导入Elasticsearch的更多相关文章
- 利用sqoop将hive数据导入导出数据到mysql
一.导入导出数据库常用命令语句 1)列出mysql数据库中的所有数据库命令 # sqoop list-databases --connect jdbc:mysql://localhost:3306 ...
- Hive数据导入导出的几种方式
一,Hive数据导入的几种方式 首先列出讲述下面几种导入方式的数据和hive表. 导入: 本地文件导入到Hive表: Hive表导入到Hive表; HDFS文件导入到Hive表; 创建表的过程中从其他 ...
- KUDU数据导入尝试一:TextFile数据导入Hive,Hive数据导入KUDU
背景 SQLSERVER数据库中单表数据几十亿,分区方案也已经无法查询出结果.故:采用导出功能,导出数据到Text文本(文本>40G)中. 因上原因,所以本次的实验样本为:[数据量:61w条,文 ...
- sqoop用法之mysql与hive数据导入导出
目录 一. Sqoop介绍 二. Mysql 数据导入到 Hive 三. Hive数据导入到Mysql 四. mysql数据增量导入hive 1. 基于递增列Append导入 1). 创建hive表 ...
- Logstash学习之路(四)使用Logstash将mysql数据导入elasticsearch(单表同步、多表同步、全量同步、增量同步)
一.使用Logstash将mysql数据导入elasticsearch 1.在mysql中准备数据: mysql> show tables; +----------------+ | Table ...
- Nebula Exchange 工具 Hive 数据导入的踩坑之旅
摘要:本文由社区用户 xrfinbj 贡献,主要介绍 Exchange 工具从 Hive 数仓导入数据到 Nebula Graph 的流程及相关的注意事项. 1 背景 公司内部有使用图数据库的场景,内 ...
- 从零自学Hadoop(16):Hive数据导入导出,集群数据迁移上
阅读目录 序 导入文件到Hive 将其他表的查询结果导入表 动态分区插入 将SQL语句的值插入到表中 模拟数据文件下载 系列索引 本文版权归mephisto和博客园共有,欢迎转载,但须保留此段声明,并 ...
- 从零自学Hadoop(17):Hive数据导入导出,集群数据迁移下
阅读目录 序 将查询的结果写入文件系统 集群数据迁移一 集群数据迁移二 系列索引 本文版权归mephisto和博客园共有,欢迎转载,但须保留此段声明,并给出原文链接,谢谢合作. 文章是哥(mephis ...
- Hive 实战(1)--hive数据导入/导出基础
前沿: Hive也采用类SQL的语法, 但其作为数据仓库, 与面向OLTP的传统关系型数据库(Mysql/Oracle)有着天然的差别. 它用于离线的数据计算分析, 而不追求高并发/低延时的应用场景. ...
随机推荐
- 细说Python的lambda函数用法,建议收藏
细说Python的lambda函数用法,建议收藏 在Python中有两种函数,一种是def定义的函数,另一种是lambda函数,也就是大家常说的匿名函数.今天我就和大家聊聊lambda函数,在Pyth ...
- 在Vue项目中加载krpano全景图
在Vue-cli项目中做krpano全景图编辑器的时候,由于js插件的路径是动态的,做的过程中遇到了加载不到资源的难题,在网上搜索了好久也没找到合适的办法,最后想到了可能是JS加载的问题,于是解决了问 ...
- Linux端口是否占用的方法
1.netstat或ss命令 netstat -anlp | grep 80 2.lsof命令 这个命令是查看进程占用哪些文件的 lsof -i:80 3.fuser命令 fuser命令和lsof正好 ...
- 解决IOS把数字渲染为电话号码,颜色为蓝色解决方案
可将telephone=no,则手机号码不被显示为拨号链接<meta name="format-detection" content="telephone=no&q ...
- 使用python的subprocess模块调用linux系统命令
subprocess模块主要有call().check_call().check_output().Popen()函数,简要描述如下: Main API ======== call(...): Run ...
- PropertyUtilsBean 将bean转成map
public static Map<String,String> beanToMap(Object bean) { Map<String,String> params =Map ...
- export ,export default 和 import 区别以及用法
首先要知道export,import ,export default是什么 ES6模块主要有两个功能:export和importexport用于对外输出本模块(一个文件可以理解为一个模块)变量的接口i ...
- vue项目兼容es6语法跟IE浏览器
要安装babel-polyfill和es6-promise.用来兼容ie和es6: 附赠链接下载:https://babeljs.io/docs/en/6.26.3/babel-polyfill:ht ...
- VUE的Seo优化 如何实现
今天看到这样一个问题,在vue中,如何进行seo优化呢? 大家应该都知道,seo优化主要是做搜索引擎的排名,但是ajax异步又不支持seo,同时对于url #/的写法,搜索引擎也没办法爬取网站内其他路 ...
- MySQL第二讲 一一一一 MySQL语句进阶
通过命令来备份数据库: 通过数据库软件里面的,mysqldump模块来操作,如下: mysqldump -u root db1 > db1.sql -p; //没有-d就是备份的时候:数据表结构 ...