CPU指令重排序与MESI缓存一致性
一、重排序场景

class ResortDemo {
int a = 0;
boolean flag = false;
public void writer() {
a = 1; //1
flag = true; //2
}
Public void reader() {
if (flag) { //3
int i = a * a; //4
……
}
}
}
当两个线程 A 和 B,A 首先执行writer() 方法,随后 B 线程接着执行 reader() 方法。线程B在执行操作4时,能否看到线程 A 在操作1对共享变量 a 的写入?
答案是:不一定能看到。
由于操作1和操作2没有数据依赖关系,编译器和处理器可以对这两个操作重排序;同样,操作3和操作4没有数据依赖关系,编译器和处理器也可以对这两个操作重排序。
二、追根溯源
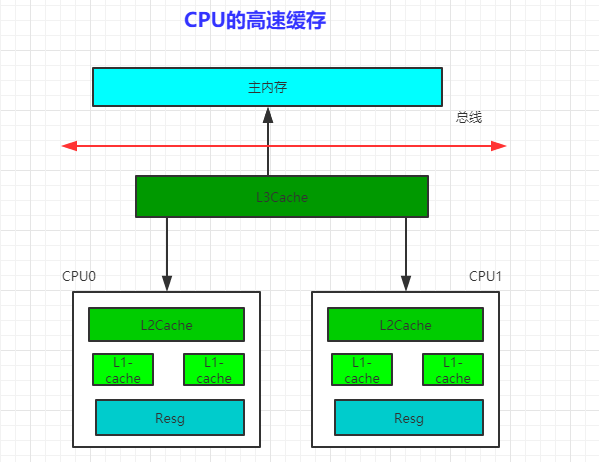
三、缓存一致性协议
据不一致

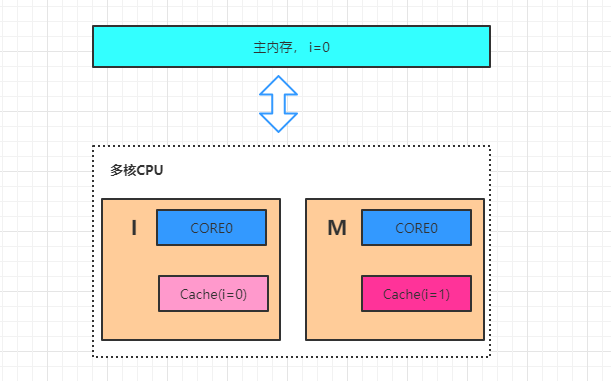
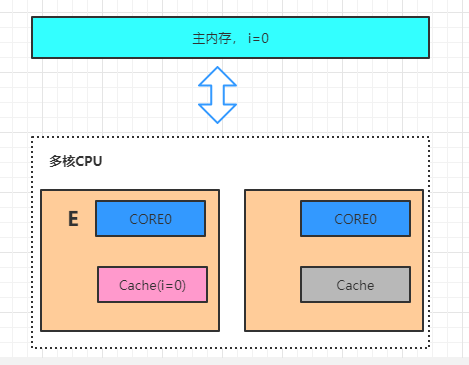
四、重排序原因
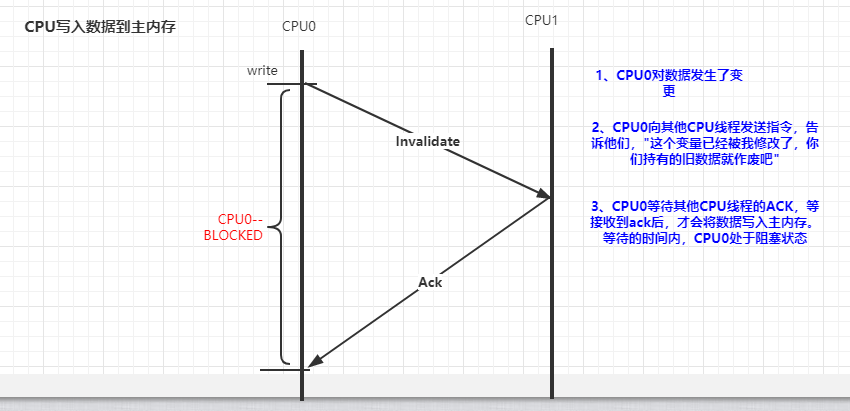
基于上图中的原因,CPU又引入了storeBuffers的缓冲区。CPU0 只需要在写入共享数据时,直接把数据写入到 storebufferes 中,同时发送 invalidate 消息,然后继续去处理其

这个时候,我们再来看上述标题一中的重排序场景。
class ResortDemo {
int a = 0;
boolean flag = false;
public void writer() {
a = 1; //1
flag = true; //2
}
Public void reader() {
if (flag) { //3
int i = a * a; //4
……
}
}
}
当执行1操作时,a的状态从S->M,此时,线程A会先把变更写入到storebuffers,然后发送invalidate去异步通知其他CPU线程,紧接着就执行了下面的2操作。
此时,可能1的变更还在storebuffers中,并未提交到主内存。什么时候会提交到主内存,也不确定。
所以,线程B调用read方法可能会出现,看到了flag的变更,但是看不到a的变更,就出现了重排序的现象。
转载:https://www.cnblogs.com/ningJJ/p/11479145.html
CPU指令重排序与MESI缓存一致性的更多相关文章
- cpu指令重排序的原理
目录: 1.重排序场景 2.追根溯源 3.缓存一致性协议 4.重排序原因 一.重排序场景 class ResortDemo { int a = 0; boolean flag = false; pub ...
- java高并发核心要点|系列4|CPU内存指令重排序(Memory Reordering)
今天,我们来学习另一个重要的概念. CPU内存指令重排序(Memory Reordering) 什么叫重排序? 重排序的背景 我们知道现代CPU的主频越来越高,与cache的交互次数也越来越多.当CP ...
- Java的多线程机制系列:不得不提的volatile及指令重排序(happen-before)
一.不得不提的volatile volatile是个很老的关键字,几乎伴随着JDK的诞生而诞生,我们都知道这个关键字,但又不太清楚什么时候会使用它:我们在JDK及开源框架中随处可见这个关键字,但并发专 ...
- Java的多线程机制系列:(四)不得不提的volatile及指令重排序(happen-before)
一.不得不提的volatile volatile是个很老的关键字,几乎伴随着JDK的诞生而诞生,我们都知道这个关键字,但又不太清楚什么时候会使用它:我们在JDK及开源框架中随处可见这个关键字,但并发专 ...
- 指令重排序及Happens-before法则随笔
指令重排序 对主存的一次访问一般花费硬件的数百次时钟周期.处理器通过缓存(caching)能够从数量级上降低内存延迟的成本这些缓存为了性能重新排列待定内存操作的顺序.也就是说,程序的读写操作不一定会按 ...
- JVM并发机制的探讨——内存模型、内存可见性和指令重排序
并发本来就是个有意思的问题,尤其是现在又流行这么一句话:“高帅富加机器,穷矮搓搞优化”. 从这句话可以看到,无论是高帅富还是穷矮搓都需要深入理解并发编程,高帅富加多了机器,需要协调多台机器或者多个CP ...
- 深入浅出 Java Concurrency (4): 原子操作 part 3 指令重排序与happens-before法则
转: http://www.blogjava.net/xylz/archive/2010/07/03/325168.html 在这个小结里面重点讨论原子操作的原理和设计思想. 由于在下一个章节中会谈到 ...
- J.U.C JMM. pipeline.指令重排序,happen-before
pipeline: 现在的CPU一般采用流水线方式来执行指令.一个指令执行周期被分成:取值,译码,执行,访存,写会,更新PC若干阶段.然后,多条指令可以同时存在于流水线中,同时被执行,来提高系统的吞吐 ...
- 不得不提的volatile及指令重排序(happen-before)
微信公众号[程序员江湖] 作者黄小斜,斜杠青年,某985硕士,阿里 Java 研发工程师,于 2018 年秋招拿到 BAT 头条.网易.滴滴等 8 个大厂 offer,目前致力于分享这几年的学习经验. ...
随机推荐
- laravel中model类中好用的方法
public function field() { return $this->belongsTo(HrmAuthFieldsModel::class, 'filed_id', 'id'); } ...
- 旋转数组 空间复杂度为O(1) 的2 种方法 + 1种空间复杂度O(n)
题目地址 : 旋转数组. 网上好多不是根本就是错的,就是空间复杂度不是真正为1 下面总结一下 方法1 普通方法(空间复杂度不满足要求,但是题目并不会判错,说明他们没用对空间进行校验) ··· publ ...
- Django Rest Framework API指南
Django Rest Framework API指南 Django Rest Framework 所有API如下: Request 请求 Response 响应 View 视图 Generic vi ...
- orm练习题
表关系图 models.py from django.db import models # Create your models here. class Teacher(models.Model): ...
- Delphi XE2 之 FireMonkey 入门(33) - 控件基础: TFmxObject: SaveToStream、LoadFromStream、SaveToBinStream、LoadFromBinStream
Delphi XE2 之 FireMonkey 入门(33) - 控件基础: TFmxObject: SaveToStream.LoadFromStream.SaveToBinStream.LoadF ...
- 阶段3 1.Mybatis_11.Mybatis的缓存_2 延迟加载和立即加载的概念
用户关联的account信息,假设一个用户管理的account有100个.那么我们在查询用户的时候那100个关联的信息也被查询出来. 用的时候才去查关联的数据 这两个不同的地方就是查询的时机不同 什么 ...
- Gradle之Android Gradle Plugin 主要流程分析(二)
[Android 修炼手册]Gradle 篇 -- Android Gradle Plugin 主要流程分析 预备知识 理解 gradle 的基本开发 了解 gradle task 和 plugin ...
- CSS3——表单 计数器 网页布局 应用实例
CSS应用实例 表单 实例 输入框样式 输入框填充-----内边距 输入框------边框 输入框-----颜色 输入框-----聚焦 输入框-------图标 输入框------动画 [自动右滑] ...
- Nginx/Nginx配置文件
nginx.conf配置文件 mac目录位置:/usr/local/etc/nginx/ ubuntu目录位置:/etc/nginx nginx.conf配置 /* 全局块:配置影响nginx全局的指 ...
- Java基础语法-运算符
1算术运算符 1.1运算符和表达式 运算符:对常量和变量进行操作的符号. 表达式:用运算符把常量或者变量连接起来符合java语法的式子就可以称为表达式. 不同运算符链接的表达式体现的是不同类型的表达式 ...