java实现一个简单的爬虫小程序
前言
前些天无意间在百度搜索了一下以前写过的博客
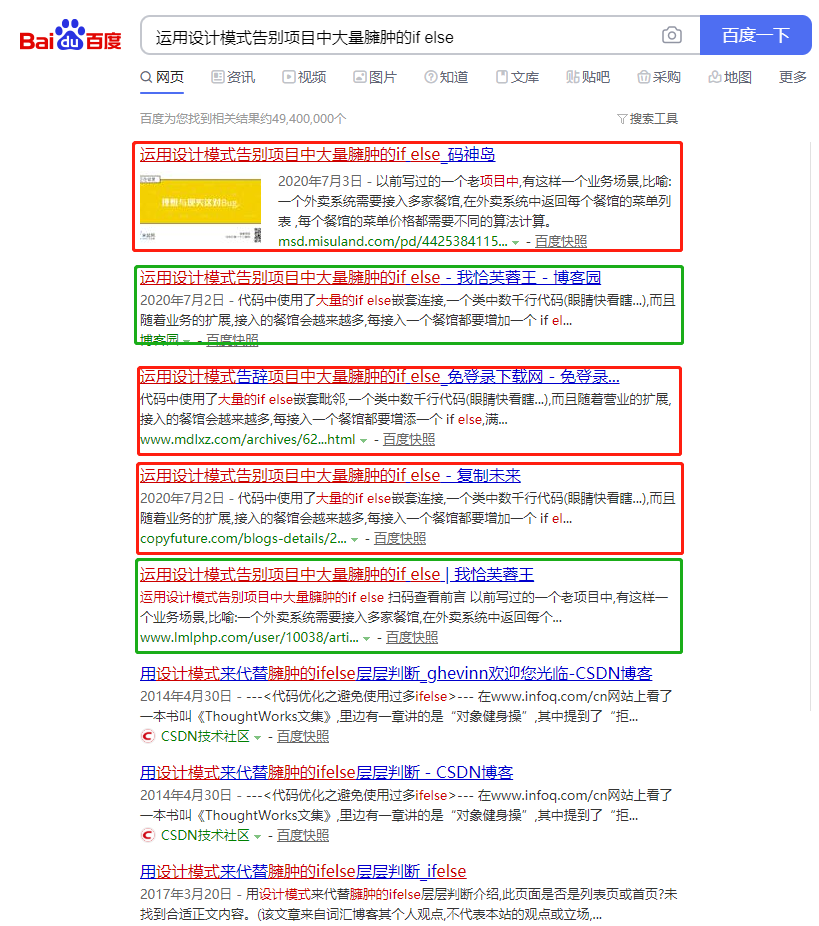
我啥时候在这么多不知名的网站上发表博客了???点进去一看, 内容一模一样,作者却不是我...

然后又去搜了其他篇博客,果然,基本上每篇都在别的网站上有,细想,可能是通过网络爬虫爬取博客园首页博客,然后copy至自己网站中,于是乎,博主也来实现一遍爬取流程。。。
实现思路
先访问博客园首页,F12查看源代码,可以看到博客的链接和标题都是放在一个a标签里,
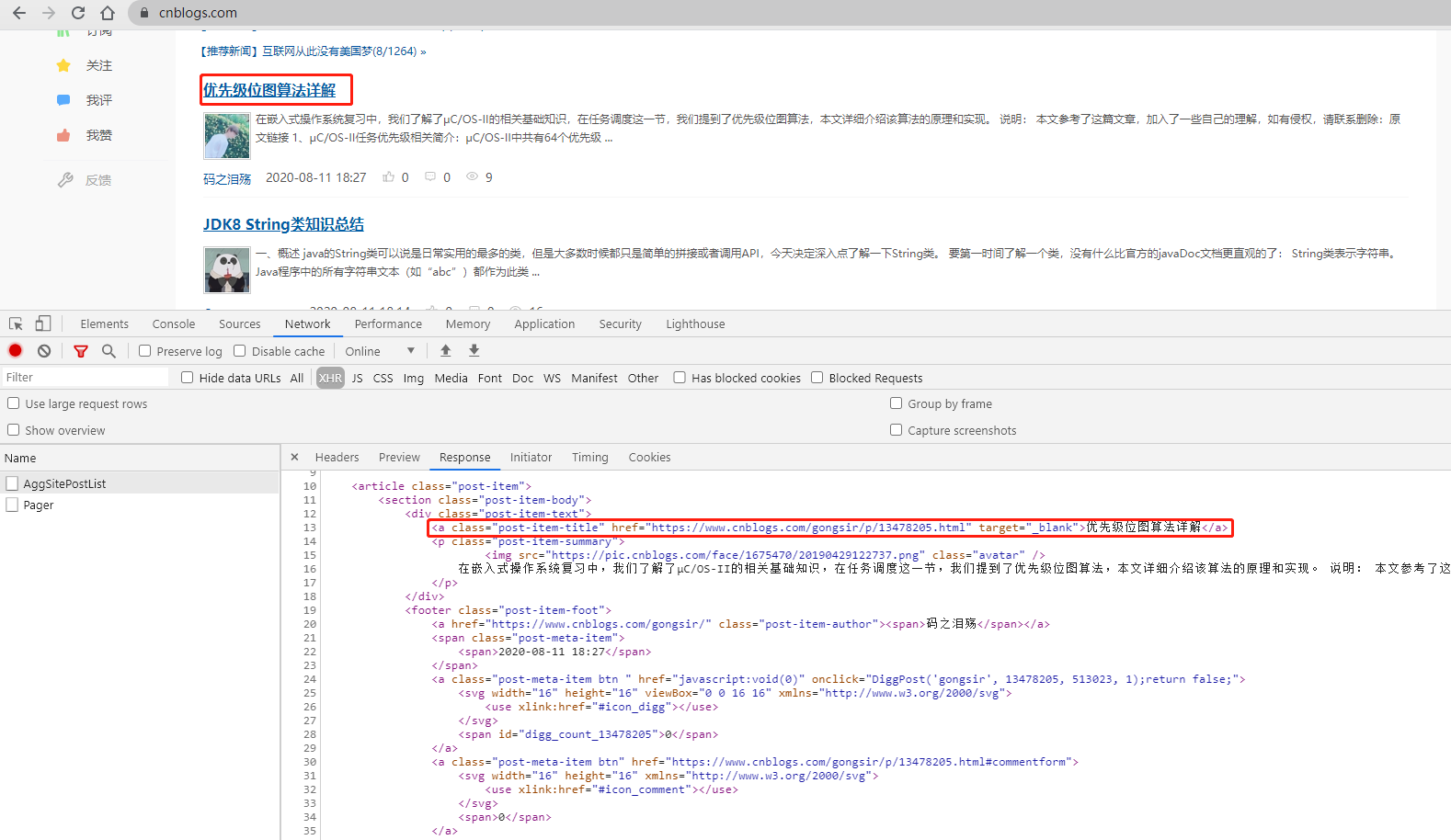
点击一下上一下、下一页,再看一下请求参数,嗯。。。这个应该是页码参数
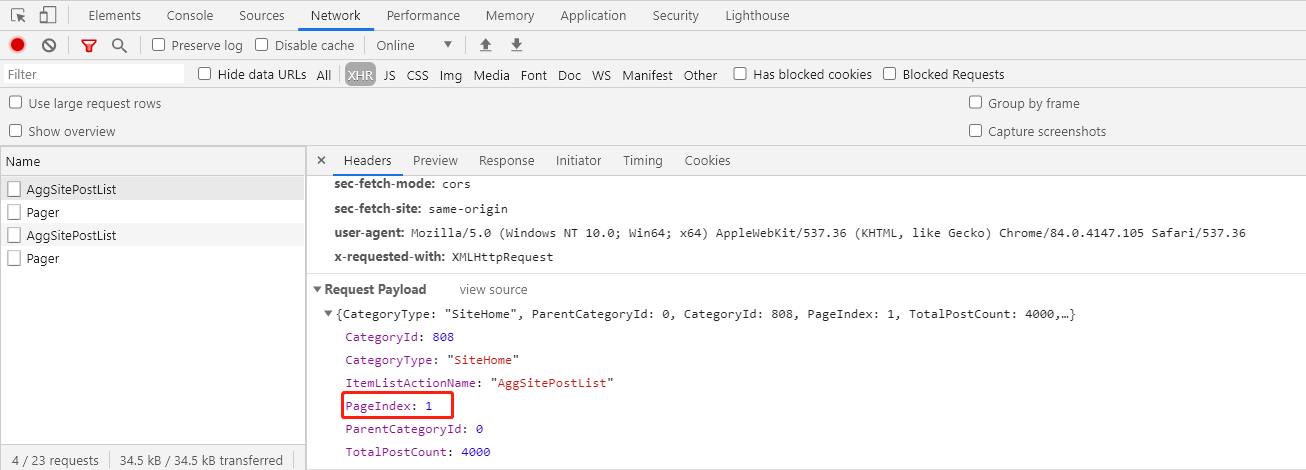
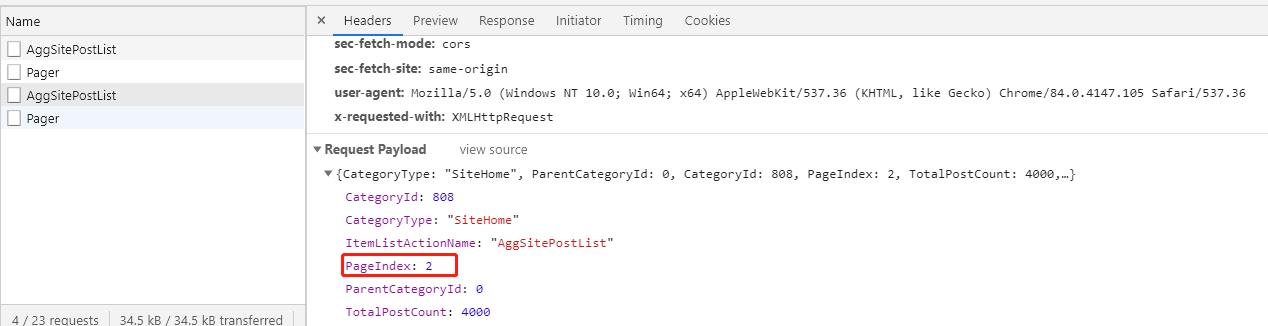
通过以上这些信息,我们就可以知道只需要每次传入不同的页码访问博客园首页,就可以获得相应博客的html页面返回,然后我们返回的html页面,解析出当页的博客链接和标题就可以啦。
说干就干,下面我们用代码实现模拟下载博客园200页(200 * 20 = 4000篇)博文的程序
具体实现
直接上代码了,注释都在代码中
import java.io.*;
import java.net.URL;
import java.net.URLConnection;
import java.text.SimpleDateFormat;
import java.util.ArrayList;
import java.util.Date;
import java.util.List;
import java.util.Map;
import java.util.concurrent.CopyOnWriteArrayList;
import java.util.regex.Matcher;
import java.util.regex.Pattern; /**
* @ClassName BKYPageReptile
* @Description TODO(爬取博客园文章)
* @Author 我恰芙蓉王
* @Date 2020年08月11日 9:38
* @Version 2.0.0
**/ public class BKYPageReptile { //请求地址
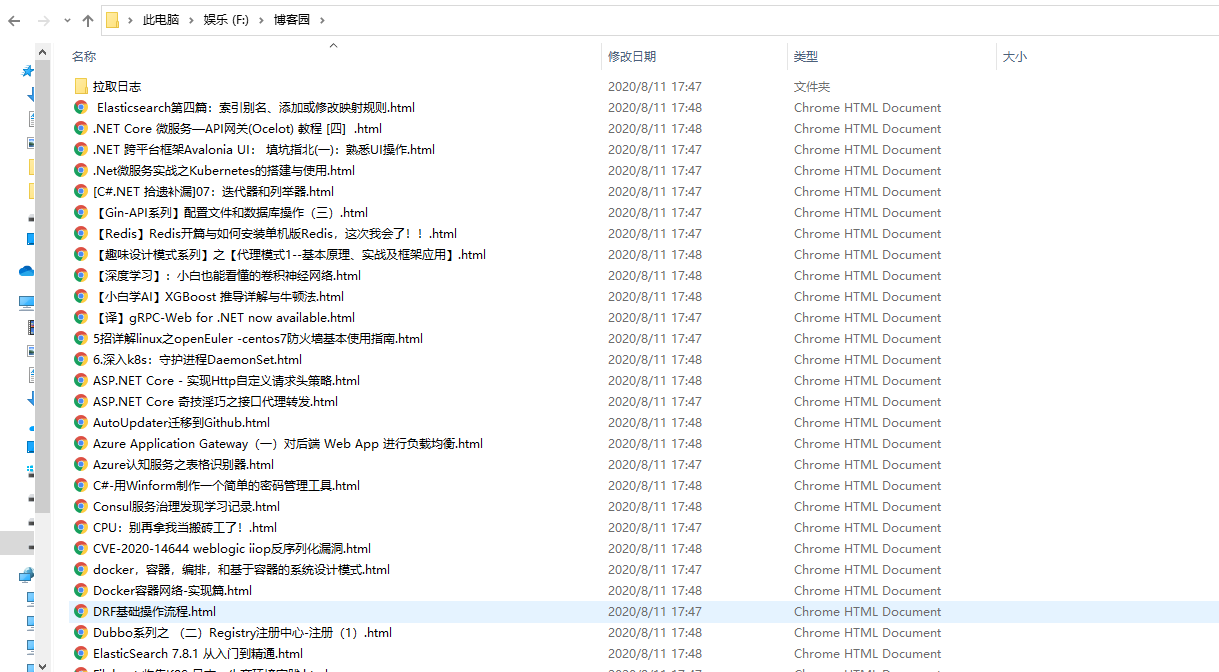
private static final String URL = "https://www.cnblogs.com"; //保存路径
private static final String TARGET_PATH = "F://" + "博客园"; //行匹配正则
private static final Pattern LINE_PATTERN = Pattern.compile("<a class=\"post-item-title\" href=\"https://www.cnblogs.com/.*?\\.html\" target=\"_blank\">.*?</a>"); //url正则
private static final Pattern URL_PATTERN = Pattern.compile("https://www.cnblogs.com/.*?\\.html"); //标题/文件名正则
private static final Pattern TITLE_PATTERN = Pattern.compile(">.*?</a>"); //标题缓存
private static final List<String> TITLE_LIST = new CopyOnWriteArrayList<>(); //当前页数
private static int PAGE = 1; //最大拉取页数
private static final int MAX_PAGE = 200; //一共拉取博客篇数
private static int ALL_COUNT = 0; //时间格式
private static final SimpleDateFormat SDF = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss"); public static void main(String[] args) {
//创建根目录
File rootDir = new File(TARGET_PATH);
if (!rootDir.exists()) {
rootDir.mkdir();
} //创建日志文件夹
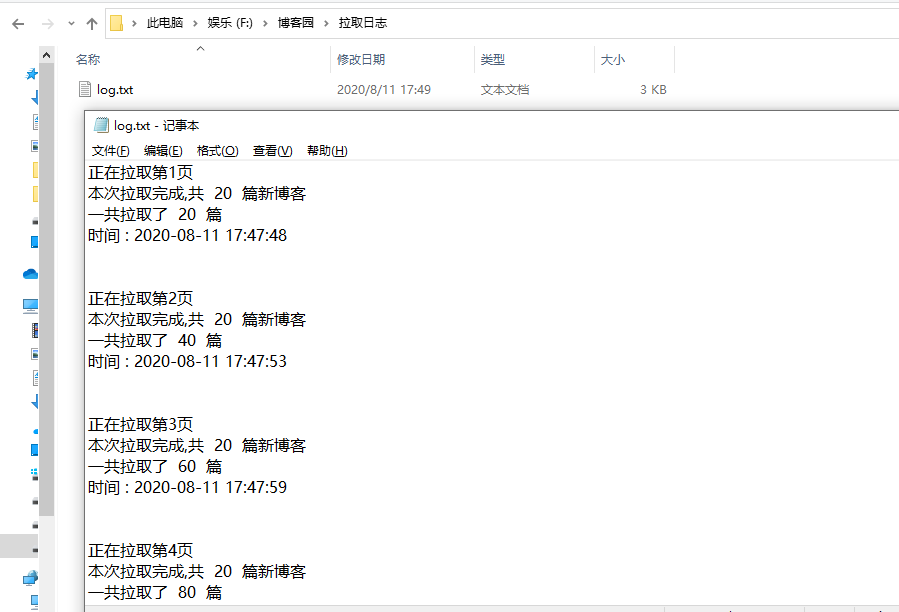
String logPath = TARGET_PATH + "//拉取日志";
File logDir = new File(logPath);
if (!logDir.exists()) {
logDir.mkdir();
} //创建日志文件
File logFile = new File(logPath + "//log.txt");
if (!logFile.exists()) {
try {
logFile.createNewFile();
} catch (IOException e) {
e.printStackTrace();
}
} //循环拉取
while (PAGE <= MAX_PAGE) {
//日志内容
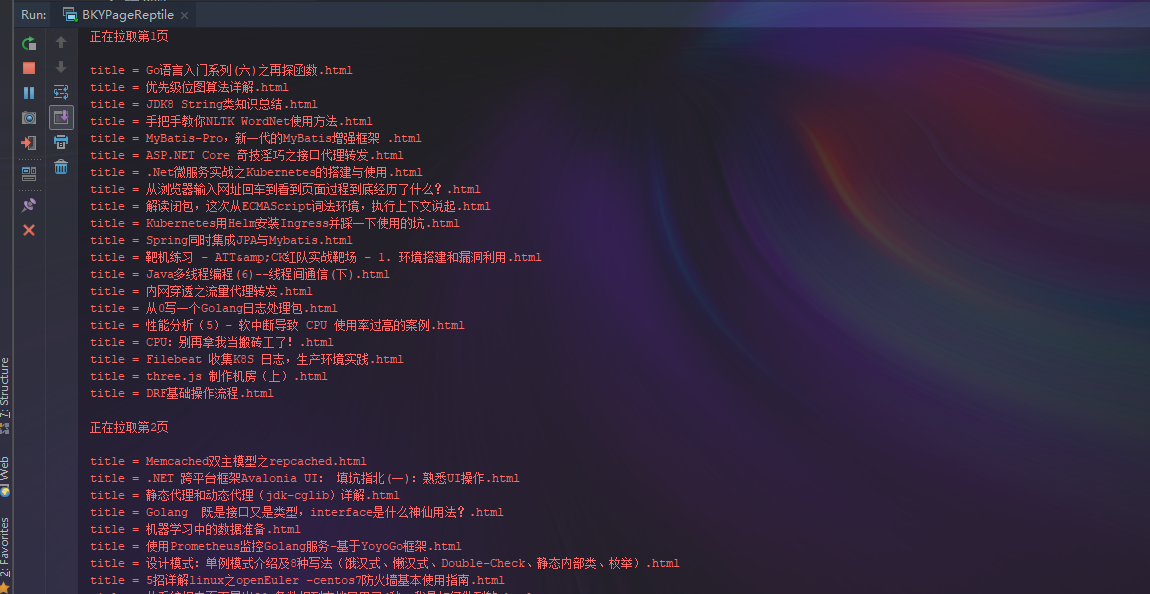
String logContent = "正在拉取第" + PAGE + "页\n";
System.err.println("\n" + logContent);
String param = "PageIndex=" + PAGE; try {
//获取指定页页返回内容
String response = sendPost(URL, param); Matcher matcher = LINE_PATTERN.matcher(response); //需要写入的文件集合
ArrayList<FileTemplate> urlList = new ArrayList<>(20); /**
* 解析返回内容封装成FileTemplate
*/
while (matcher.find()) {
//匹配行
String matchLine = matcher.group(); Matcher matcher1 = TITLE_PATTERN.matcher(matchLine);
String title = null;
while (matcher1.find()) {
//匹配的标题 >标题</a>
title = matcher1.group();
}
//截取拿到真实标题
title = title.substring(1, title.length() - 4);
//特殊字符处理
title = title.replace("<", "《")
.replace(">", "》")
.replace("\\", "-")
.replace("/", "-")
.replace(":", ":")
.replace("*", "")
.replace("?", "?")
.replace("|", "")
+ ".html";
System.err.println("title = " + title); //如果已经拉取了此标题的html文件 则跳过此篇
if (TITLE_LIST.contains(title)) {
continue;
} Matcher matcher2 = URL_PATTERN.matcher(matchLine);
String url = null;
while (matcher2.find()) {
//匹配博客的请求url
url = matcher2.group();
}
//封装成文件模板对象
urlList.add(new FileTemplate(url, title, false));
} /**
* 写入磁盘
*/
urlList.parallelStream().forEach(v -> {
FileOutputStream fos = null;
PrintWriter pw = null;
try {
String result = sendGet(v.getGetUrl(), "");
File file = new File(TARGET_PATH + File.separator + v.getTitle());
file.createNewFile(); fos = new FileOutputStream(file);
pw = new PrintWriter(fos);
pw.write(result.toCharArray());
pw.flush();
v.setFlag(true); TITLE_LIST.add(v.getTitle());
} catch (Exception e) {
System.out.println(v.toString());
e.printStackTrace();
} finally {
try {
if (fos != null) {
fos.close();
}
if (pw != null) {
pw.close();
}
} catch (IOException e) {
e.printStackTrace();
} }
}); /**
* 记录日志
*/
//本次写入成功博客数
long count = urlList.stream().filter(v -> v.getFlag()).count(); String date = SDF.format(new Date()); //累加次数
ALL_COUNT += count; logContent += "本次拉取完成,共 " + count + " 篇新博客\r\n";
logContent += "一共拉取了 " + ALL_COUNT + " 篇\r\n";
logContent += "时间 : " + date + "\n\n";
BufferedWriter out = null;
try {
out = new BufferedWriter(new OutputStreamWriter(new FileOutputStream(logFile, true)));
out.write(logContent + "\r\n");
} catch (Exception e) {
e.printStackTrace();
} finally {
try {
out.close();
} catch (IOException e) {
e.printStackTrace();
}
} PAGE++;
} catch (Exception e) {
e.printStackTrace();
}
}
} /**
* 文件模板类
*/
private static class FileTemplate {
/**
* 请求地址
*/
private String getUrl; /**
* 标题
*/
private String title; /**
* 已经爬取标识
*/
private boolean flag; public FileTemplate(String getUrl, String title, boolean flag) {
this.getUrl = getUrl;
this.title = title;
this.flag = flag;
} public String getGetUrl() {
return getUrl;
} public void setGetUrl(String getUrl) {
this.getUrl = getUrl;
} public String getTitle() {
return title;
} public void setTitle(String title) {
this.title = title;
} @Override
public String toString() {
final StringBuilder sb = new StringBuilder("FileTemplate{");
sb.append("getUrl='").append(getUrl).append('\'');
sb.append(", title='").append(title).append('\'');
sb.append('}');
return sb.toString();
} public boolean getFlag() {
return flag;
} public void setFlag(boolean flag) {
this.flag = flag;
}
} /**
* 功能描述: 向指定URL发送GET请求
*
* @param url 发送请求的URL
* @param param 请求参数,请求参数应该是 name1=value1&name2=value2 的形式
* @创建人: 我恰芙蓉王
* @创建时间: 2020年08月11日 16:42:17
* @return: java.lang.String 响应结果
**/
public static String sendGet(String url, String param) {
StringBuilder sb = new StringBuilder();
BufferedReader in = null;
try {
String urlNameString = url + "?" + param;
URL realUrl = new URL(urlNameString);
// 打开和URL之间的连接
URLConnection connection = realUrl.openConnection();
// 设置通用的请求属性
connection.setRequestProperty("accept", "*/*");
connection.setRequestProperty("connection", "Keep-Alive");
connection.setRequestProperty("user-agent",
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1;SV1)");
// 建立实际的连接
connection.connect();
// 获取所有响应头字段
Map<String, List<String>> map = connection.getHeaderFields();
// 定义 BufferedReader输入流来读取URL的响应
in = new BufferedReader(new InputStreamReader(
connection.getInputStream()));
String line;
while ((line = in.readLine()) != null) {
sb.append(line);
}
} catch (Exception e) {
System.out.println("发送GET请求出现异常!" + e);
e.printStackTrace();
}
// 使用finally块来关闭输入流
finally {
try {
if (in != null) {
in.close();
}
} catch (Exception e2) {
e2.printStackTrace();
}
}
return sb.toString();
} /**
* 功能描述: 向指定URL发送POST请求
*
* @param url 发送请求的URL
* @param param 请求参数,请求参数应该是 name1=value1&name2=value2 的形式
* @创建人: 我恰芙蓉王
* @创建时间: 2020年08月11日 16:42:17
* @return: java.lang.String 响应结果
**/
public static String sendPost(String url, String param) {
PrintWriter out = null;
BufferedReader in = null;
StringBuilder sb = new StringBuilder();
try {
URL realUrl = new URL(url);
// 打开和URL之间的连接
URLConnection conn = realUrl.openConnection();
// 设置通用的请求属性
conn.setRequestProperty("accept", "*/*");
conn.setRequestProperty("connection", "Keep-Alive");
conn.setRequestProperty("user-agent",
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1;SV1)");
// 发送POST请求必须设置如下两行
conn.setDoOutput(true);
conn.setDoInput(true);
// 获取URLConnection对象对应的输出流
out = new PrintWriter(conn.getOutputStream());
// 发送请求参数
out.print(param);
// flush输出流的缓冲
out.flush();
// 定义BufferedReader输入流来读取URL的响应
in = new BufferedReader(
new InputStreamReader(conn.getInputStream()));
String line;
while ((line = in.readLine()) != null) {
sb.append(line);
}
} catch (Exception e) {
System.out.println("发送 POST 请求出现异常!" + e);
e.printStackTrace();
}
//使用finally块来关闭输出流、输入流
finally {
try {
if (out != null) {
out.close();
}
if (in != null) {
in.close();
}
} catch (IOException ex) {
ex.printStackTrace();
}
}
return sb.toString();
}
}
测试结果
控制台输出
下载在电脑磁盘中
日志文件内容
随便打开一个html文件
java实现一个简单的爬虫小程序的更多相关文章
- 利用java开发一个双击执行的小程序
之前我们利用java写了很多东西,但是好像都没有什么实际意义. 因为有意义桌面小程序怎么都得有个界面,可是界面又不太好搞.或者 了解到这一层的人就少之又少了. 呀,是不是还得开辟一些版面来介绍awt和 ...
- 使用vue+koa实现一个简单的图书小程序(1)
这个系列的博客用来记录我开发时候遇到的问题以及学习到的知识 边做边学: 前后端分离,高内聚低耦合小程序端使用了mpvue 内部使用了vuejs的语法 来做整个小程序的渲染层 后端使用的是koa2搭建一 ...
- [C#] Socket 通讯,一个简单的聊天窗口小程序
Socket,这玩意,当时不会的时候,抄别人的都用不好,简单的一句话形容就是“笨死了”:也是很多人写的太复杂,不容易理解造成的.最近在搞erlang和C的通讯,也想试试erlang是不是可以和C#简单 ...
- 一个简单的servlet小程序
servlet是不能单独运行的,他是运行在web服务器或应用服务器上的java程序,或者可以说是在servlet容器上运行的,我们经常使用到的tomcat就是一个servlet容器. 他是处理HTTP ...
- python写的的简单的爬虫小程序
import re import urllib def getHtml(url): page=urllib.urlopen(url) html=page.read() return html def ...
- 福利贴——爬取美女图片的Java爬虫小程序代码
自己做的一个Java爬虫小程序 废话不多说.先上图. 目录命名是用标签缩写,假设大家看得不顺眼能够等完成下载后手动改一下,比方像有强迫症的我一样... 这是挂了一个晚上下载的总大小,只是还有非常多由于 ...
- 一个python爬虫小程序
起因 深夜忽然想下载一点电子书来扩充一下kindle,就想起来python学得太浅,什么“装饰器”啊.“多线程”啊都没有学到. 想到廖雪峰大神的python教程很经典.很著名.就想找找有木有pdf版的 ...
- Java实现一个简单的网络爬虫
Java实现一个简单的网络爬虫 import java.io.BufferedReader; import java.io.BufferedWriter; import java.io.FileWri ...
- IOS开发之小实例--使用UIImagePickerController创建一个简单的相机应用程序
前言:本篇博文是本人阅读国外的IOS Programming Tutorial的一篇入门文章的学习过程总结,难度不大,因为是入门.主要是入门UIImagePickerController这个控制器,那 ...
随机推荐
- GPO - General GPO Settings(2)
Creating local folders and copying files Mapping printers via GPO Deny logon locally. Installation ...
- JAVA面向对象:三大特征 封装讲解
一.JAVA封装 1.封装的理解 封装是 JAVA 面向对象思想的 一 种特性,也是一种信息隐蔽的技术 2.封装的原则 将类中的某些信息隐藏起来,来防止外部程序直接访问,通过类中的方法实现对隐藏的信息 ...
- C++语法小记---函数重载
函数重载 函数重载的本质是对已有功能的扩展 构成重载的三大条件 函数名相同 参数列表不通(与返回值无关) 重载函数的作用域相同 成员函数之间可以重载,成员函数和静态成员函数之间可以构成重载,全局函数之 ...
- MacOS系统隐藏文件操作
显示或关闭隐藏文件 显示:defaults write com.apple.finder AppleShowAllFiles -bool true ; killall Finder隐藏:default ...
- 2n皇后问题-------递归 暴力求解题与分布讨论题
问题描述 给定一个n*n的棋盘,棋盘中有一些位置不能放皇后.现在要向棋盘中放入n个黑皇后和n个白皇后,使任意的两个黑皇后都不在同一行.同一列或同一条对角线上,任意的两个白皇后都不在同一行.同一列或同一 ...
- 微服务迁移记(五):WEB层搭建(3)-FreeMarker集成
一.redis搭建 二.WEB层主要依赖包 三.FeignClient通用接口 以上三项,参考<微服务迁移记(五):WEB层搭建(1)> 四.SpringSecurity集成 参考:< ...
- 02_Linux实操篇
第五章 VI和VIM编辑器 5.1. VI和VIM基本介绍 Vi编辑器是所有Unix及Linux系统下标准的编辑器,它的强大不逊色于任何最新的文本编辑器.由于对Unix及Linux系统的任何版本,Vi ...
- 记一次针对静态页面的DDOS基本防护
可以说是我试图进入安全口的天才第一步了,能走多远鬼知道呢 背景 去年年前接到的一个外包项目,是一个base在日本的中国人留学机构做的静态页面.出于锻炼自己的目的,选择为他们按次结薪做长期服务维护.20 ...
- day20:正则表达式
单个字符的匹配 findall(正则表达式,字符串) 把符合正则表达式的字符串存在列表中返回 预定义字符集(8) \d 匹配数字 \D 匹配非数字 \w 匹配数字字母下划线 \W 匹配非数字或字母或下 ...
- 解Bug之路-Nginx 502 Bad Gateway
解Bug之路-Nginx 502 Bad Gateway 前言 事实证明,读过Linux内核源码确实有很大的好处,尤其在处理问题的时刻.当你看到报错的那一瞬间,就能把现象/原因/以及解决方案一股脑的在 ...