Python爬取表结构数据---pandas快速获取
例如:
此形式的表数据,可用pandas获取
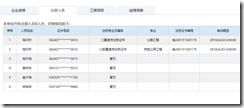
首先获取table
import requests
from lxml import etree
import pandas as pd url = 'http://dn4.gxzjt.gov.cn:1141/WebInfo/Enterprise/Enterprise_Detail.aspx?prjnum=43445821-a17e-4c7b-9217-97c4e38cbf30'
a = requests.get(url).text
b = etree.HTML(a)
c = b.xpath("//div[@id='ContentPlaceHolder1_UpdatePanel2']/fieldset/table")
然后使用pandas将数据内容转成列表嵌套字典格式
zcry_table = etree.tostring(c[0], encoding='utf-8').decode()
df = pd.read_html(zcry_table, encoding='utf-8', header=0)[0]
results = list(df.T.to_dict().values()) # 转换成列表嵌套字典的格式
print(results)
结果如下:
[{'序号': 1, '人员姓名': '高轩跃', '证件号码': '362427********361X', '注册专业及等级': '二建造师注册证书', '专业': '公路工程', '注册证书编号': '桂245151545179', '有效期至': '2018/4/24 0:00:00'}, {'序号': 2, '人员姓名': '高轩跃', '证件号码': '362427********361X', '注册专业及等级': '二级建造师注册证书', '专业': '市政公用工程', '注册证书编号': '桂245151545179', '有效期至': '2018/4/23 0:00:00'}, {'序号': 3, '人员姓名': '高轩强', '证件号码': '362427********3615', '注册专业及等级': '暂无', '专业': nan, '注册证书编号': nan, '有效期至': nan}, {'序号': 4, '人员姓名': '曹明亮', '证件号码': '360101********5010', '注册专业及等级': '暂无', '专业': nan, '注册证书编号': nan, '有效期至': nan}, {'序号': 5, '人员姓名': '崔庆梅', '证件号码': '530325********1726', '注册专业及等级': '暂无', '专业': nan, '注册证书编号': nan, '有效期至': nan}, {'序号': 6, '人员姓名': '李晓燕', '证件号码': '530126********0846', '注册专业及等级': '暂无', '专业': nan, '注册证书编号': nan, '有效期至': nan}]
最后循环依次取出:
for result in results:
ryxm = result['人员姓名']
zjhm = result['证件号码']
zclxjdj = result['注册专业及等级']
zy = result['专业']
zczsbh = result['注册证书编号']
yxqz = result['有效期至']
print(ryxm, zjhm, zclxjdj, zczsbh, zy, yxqz)
高轩跃 362427********361X 二建造师注册证书 桂245151545179 公路工程 2018/4/24 0:00:00
高轩跃 362427********361X 二级建造师注册证书 桂245151545179 市政公用工程 2018/4/23 0:00:00
高轩强 362427********3615 暂无 nan nan nan
曹明亮 360101********5010 暂无 nan nan nan
崔庆梅 530325********1726 暂无 nan nan nan
李晓燕 530126********0846 暂无 nan nan nan
Python爬取表结构数据---pandas快速获取的更多相关文章
- Python爬取猪肉价格网并获取Json数据
场景 猪肉价格网站: http://zhujia.zhuwang.cc/ 注: 博客: https://blog.csdn.net/badao_liumang_qizhi 关注公众号 霸道的程序猿 获 ...
- python爬取信息到数据库与mysql简单的表操作
python 爬取豆瓣top250并导入到mysql数据库中 import pymysql import requests import re url='https://movie.douban.co ...
- steam夏日促销悄然开始,用Python爬取排行榜上的游戏打折信息
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 不知不觉,一年一度如火如荼的steam夏日促销悄然开始了.每年通过大大小小 ...
- 用Python爬取B站、腾讯视频、爱奇艺和芒果TV视频弹幕!
众所周知,弹幕,即在网络上观看视频时弹出的评论性字幕.不知道大家看视频的时候会不会点开弹幕,于我而言,弹幕是视频内容的良好补充,是一个组织良好的评论序列.通过分析弹幕,我们可以快速洞察广大观众对于视频 ...
- 利用python爬取城市公交站点
利用python爬取城市公交站点 页面分析 https://guiyang.8684.cn/line1 爬虫 我们利用requests请求,利用BeautifulSoup来解析,获取我们的站点数据.得 ...
- 复仇者联盟3热映,我用python爬取影评告诉你它都在讲什么
Python(发音:英[?pa?θ?n],美[?pa?θɑ:n]),是一种面向对象.直译式电脑编程语言,也是一种功能强大的通用型语言,已经具有近二十年的发展历史,成熟且稳定.它包含了一组完善而且容易理 ...
- python爬取免费优质IP归属地查询接口
python爬取免费优质IP归属地查询接口 具体不表,我今天要做的工作就是: 需要将数据库中大量ip查询出起归属地 刚开始感觉好简单啊,毕竟只需要从百度找个免费接口然后来个python脚本跑一晚上就o ...
- Python爬取豆瓣指定书籍的短评
Python爬取豆瓣指定书籍的短评 #!/usr/bin/python # coding=utf-8 import re import sys import time import random im ...
- python爬取微信公众号
爬取策略 1.需要安装python selenium模块包,通过selenium中的webdriver驱动浏览器获取Cookie的方法.来达到登录的效果 pip3 install selenium c ...
随机推荐
- 原来python还可以这样处理文件
首先我为大家介绍一下python语言吧! Python 是一个高层次的结合了解释性.编译性.互动性和面向对象的脚本语言. Python 的设计具有很强的可读性,相比其他语言经常使用英文关键字,其他语言 ...
- 服务质量分析:腾讯会议&腾讯云Elasticsearch玩出了怎样的新操作?
导语 | 腾讯会议于2019年12月底上线,两个月内日活突破1000万,被广泛应用于疫情防控会议.远程办公.师生远程授课等场景,为疫情期间的复工复产提供了重要的远程沟通工具.上线100天内,腾讯会议快 ...
- ElasticSearch(三)springboot整合ES
最基础的整合: 一.maven依赖 <parent> <groupId>org.springframework.boot</groupId> <artifac ...
- http连接,缓存,cookie,重定向,代理
早期的HTTP协议使用短连接,收到响应后就立即关闭连接,效率很低: HTTP/1.1默认启用长连接,在一个连接上收发多个请求响应,提高了传输效率: 服务器会发送“Connection: ...
- PHP入门之流程控制
前言 上一篇文章对PHP的一些类型和运算符进行了简单的讲解.PHP入门之类型与运算符 这篇简单讲解一下流程控制.结尾有实例,实例内容是用switch分支和for循环分别做一个计算器和金字塔. 分支控制 ...
- 【Django组件】WebSocket的简单实现
1:HTML: <!DOCTYPE html><html lang="en"><head> <meta charset="UTF ...
- 导弹拦截问题 dp c++
// // Created by snnnow on 2020/4/13. // //每一次拦截只能是降续的导弹 //如果该次不能拦截成功,则拦截次数需要加一 //求每次最大拦截量,以及需要的拦截次数 ...
- lemon使用方法
1.打开lemon,点击文件--新建比赛 2.输入比赛标题.保存文件名.比赛目录,点击确定 3.打开主文件夹,找到刚才创建的目录,双击打开 4.进入文件夹\(data\) 5.建立一个名为T1的文件夹 ...
- 线程_apply堵塞式
''' 创建三个进程,让三个进程分别执行功能,关闭进程 Pool 创建 ,apply执行 , close,join 关闭进程 ''' from multiprocessing import Pool ...
- list 和 [ ] 的功能不相同
对于一个对象: list(对象) 可以进行强制转换 [对象] 不能够进行强制转换,只是在外围加上 [ ] 列表推导式中相同 2020-05-06