Scrapy项目_阳光热线问政平台
目的:
爬取阳光热线问政平台问题中每个帖子的标题、详情URL、详情内容、图片以及发布时间
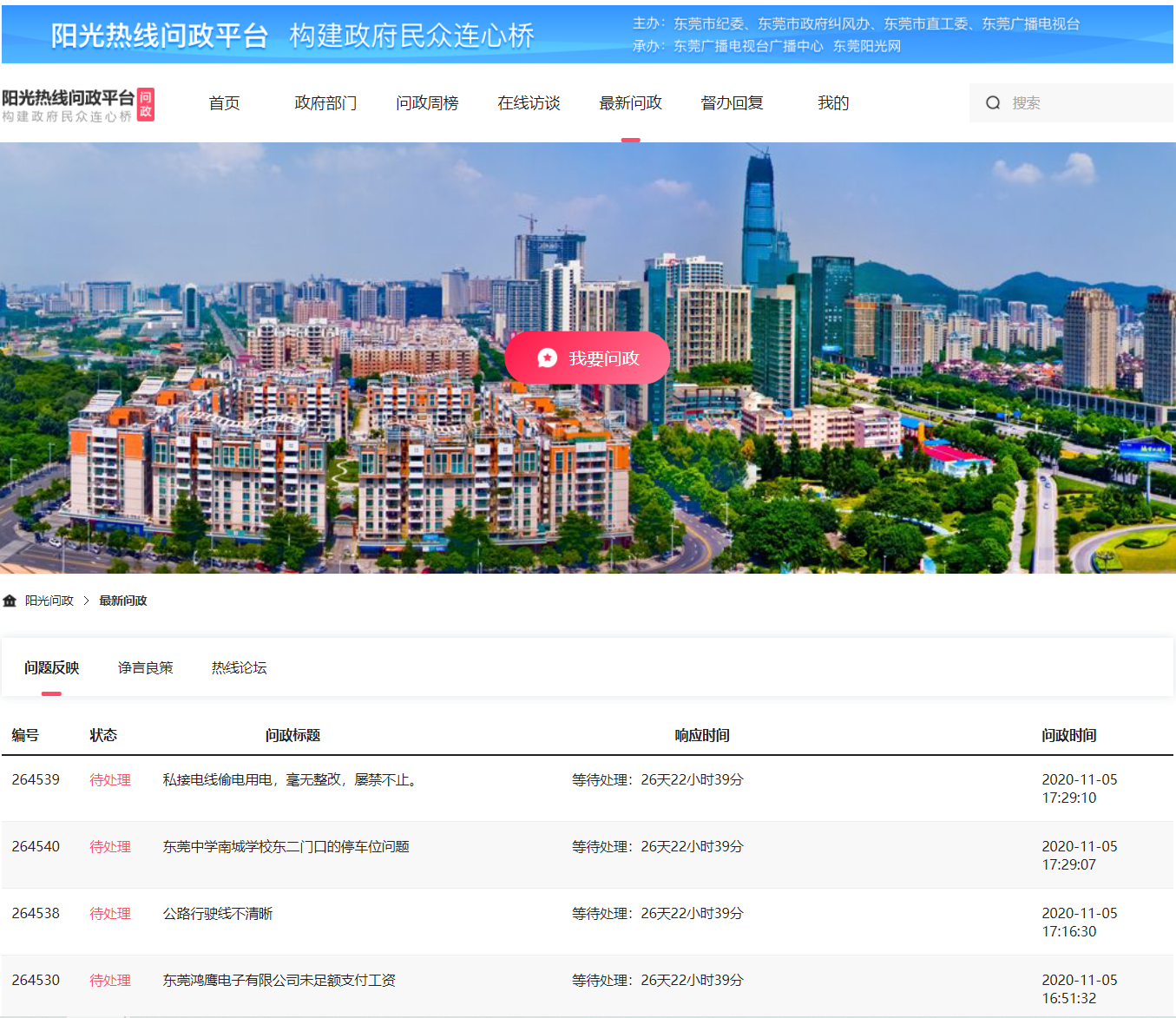

步骤:
1、创建爬虫项目
1 scrapy startproject yangguang
2 cd yangguang
3 scrapy genspider yangguang sun0769.com
2、设置item.py文件
import scrapy class YangguangItem(scrapy.Item):
# 每条帖子的标题
title = scrapy.Field()
# 帖子链接
href = scrapy.Field()
# 发布日期
publish_time = scrapy.Field()
# 详情内容
content = scrapy.Field()
# 详情图片
content_img = scrapy.Field()
3、编写爬虫文件
1 import scrapy
2 from yangguang.items import YangguangItem
3
4
5 class YgSpider(scrapy.Spider):
6 name = 'yg'
7 allowed_domains = ['sun0769.com']
8 start_urls = ['http://wz.sun0769.com/political/index/politicsNewest?id=1&page=1']
9
10 page = 1
11 url = "http://wz.sun0769.com/political/index/politicsNewest?id=1&page= {}"
12
13 def parse(self, response):
14 # 分组
15 li_list = response.xpath("//ul[@class='title-state-ul']/li")
16 for li in li_list:
17 item = YangguangItem()
18 item["title"] = li.xpath("./span[@class='state3']/a/text()").extract_first()
19 item["href"] = "http://wz.sun0769.com" + li.xpath("./span[@class='state3']/a/@href").extract_first()
20 item["publish_time"] = li.xpath("./span[@class='state5 ']/text()").extract_first()
21
22 yield scrapy.Request(
23 item["href"],
24 callback=self.parse_detail,
25 meta={
26 "item": item,
27 "proxy": "http://171.12.221.51:9999"
28 }
29 )
30 # 翻页
31 if self.page < 10:
32 self.page += 1
33 next_url = self.url.format(self.page)
34
35 yield scrapy.Request(next_url, callback=self.parse, meta={"proxy": "http://123.163.118.71:9999"})
36
37 def parse_detail(self, response): # 处理详情页
38 item = response.meta["item"]
39 item["content"] = response.xpath("//div[@class='details-box']/pre/text()").extract_first()
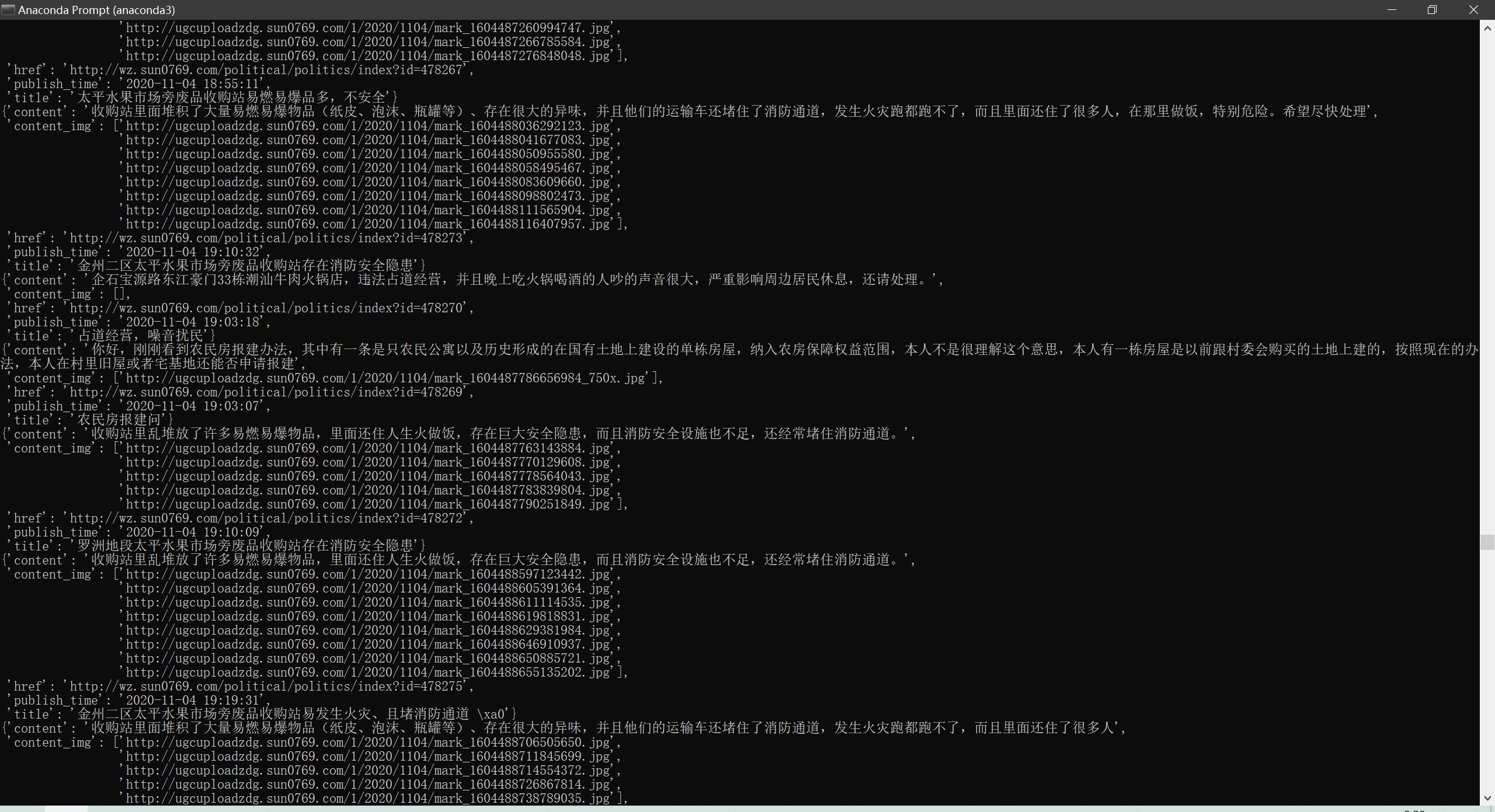
40 item["content_img"] = response.xpath("//div[@class='clear details-img-list Picture-img']/img/@src").extract()
41 yield item
4、测试
scrapy crawl yg
Scrapy项目_阳光热线问政平台的更多相关文章
- scrapy爬虫案例--爬取阳关热线问政平台
阳光热线问政平台:http://wz.sun0769.com/political/index/politicsNewest?id=1&page=1 爬取最新问政帖子的编号.投诉标题.投诉内容以 ...
- Scrapy项目_苏宁图书信息
苏宁图书(https://book.suning.com/) 目标: 1.图书一级分类 2.图书二级分类 3.图书三级分类 4.图书名字 5.图书作者 6.图书价格 7.通过Scrapy获取以上数据 ...
- 爬虫——Scrapy框架案例二:阳光问政平台
阳光热线问政平台 URL地址:http://wz.sun0769.com/index.php/question/questionType?type=4&page= 爬取字段:帖子的编号.投诉类 ...
- scrapy爬虫案例:问政平台
问政平台 http://wz.sun0769.com/index.php/question/questionType?type=4 爬取投诉帖子的编号.帖子的url.帖子的标题,和帖子里的内容. it ...
- C++框架_之Qt的开始部分_概述_安装_创建项目_快捷键等一系列注意细节
C++框架_之Qt的开始部分_概述_安装_创建项目_快捷键等一系列注意细节 1.Qt概述 1.1 什么是Qt Qt是一个跨平台的C++图形用户界面应用程序框架.它为应用程序开发者提供建立艺术级图形界面 ...
- python爬虫scrapy项目详解(关注、持续更新)
python爬虫scrapy项目(一) 爬取目标:腾讯招聘网站(起始url:https://hr.tencent.com/position.php?keywords=&tid=0&st ...
- 亲测——pycharm下运行第一个scrapy项目 ©seven_clear
最近在学习scrapy,就想着用pycharm调试,但不知道怎么弄,从网上搜了很多方法,这里总结一个我试成功了的. 首先当然是安装scrapy,安装教程什么的网上一大堆,这里推荐一个详细的:http: ...
- 凡客副总裁崔晓琦离职 曾负责旗下V+商城项目_科技_腾讯网
凡客副总裁崔晓琦离职 曾负责旗下V+商城项目_科技_腾讯网 凡客副总裁崔晓琦离职 曾负责旗下V+商城项目 腾讯科技[微博]乐天2013年09月18日12:44 分享 微博 空间 微信 新浪微博 邮箱 ...
- scrapy(一)建立一个scrapy项目
本项目实现了获取stack overflow的问题,语言使用python,框架scrapy框架,选取mongoDB作为持久化数据库,redis做为数据缓存 项目源码可以参考我的github:https ...
随机推荐
- linux git 命了
#拉取远程分支代码到本地git clone -b 分支名称 sshGit路径 #更新远程代码到本地git pull #提交本地修改的代码到本地仓库git commit -m "自动打包&qu ...
- cachedThreadPool缓存线程池
package com.loan.modules.common.util; import java.util.concurrent.BlockingQueue; import java.util.co ...
- ThreadLocal全面解析,一篇带你入门
===================== 大厂面试题: 1.Java中的引用类型有哪几种? 2.每种引用类型的特点是什么? 3.每种引用类型的应用场景是什么? 4.ThreadLocal你了解吗 5 ...
- 关于RabbitMQ的简单理解
说明:想要理解RabbitMQ,需要先理解MQ是什么?能做什么?然后根据基础知识去理解RabbitMQ是什么.提供了什么功能. 一.MQ的简单理解 1. 什么是MQ? 消息队列(Message Que ...
- 负载均衡之LVS与Nginx对比
今天总结一下负载均衡中LVS与Nginx的区别,好几篇博文一开始就说LVS是单向的,Nginx是双向的,我个人认为这是不准确的,LVS三种模式中,虽然DR模式以及TUN模式只有请求的报文经过Direc ...
- Codeforces Global Round 8 A. C+=(贪心)
题目链接:https://codeforces.com/contest/1368/problem/A 题意 给出 $a,b$,只可以使用 '+=' 运算符,问至少要使用多少次使得 $a$ 或 $b$ ...
- bzoj3626: [LNOI2014]LCA (树链剖分+离线线段树)
Description 给出一个n个节点的有根树(编号为0到n-1,根节点为0).一个点的深度定义为这个节点到根的距离+1. 设dep[i]表示点i的深度,LCA(i,j)表示i与j的最近公共祖先. ...
- Codeforces Round #582 (Div. 3) C. Book Reading
传送门 题意: 给你n,k.表示在[1,n]这个区间内,在这个区间内找出来所有x满足x%k==0,然后让所有x的个位加到一起(即x%10),输出. 例如:输入10 2 那么满足要求的数是2 4 6 8 ...
- Codeforces Round #481 (Div. 3) F. Mentors (模拟,排序)
题意:有一个长度为\(n\)的序列\(a\),求这个序列中有多少比\(a_{i}\)小的数,如果某两个位置上的数有矛盾,则不能算小. 题解:用\(pair\)来记录序列中元素的位置和大小,将他们升序排 ...
- 【应急响应】Windows应急响应入门手册
0x01 应急响应概述 首先我们来了解一下两个概念:应急响应和安全建设,这两者的区别就是应急响应是被动响应.安全建设是主动防御. 所谓有因才有果,既然是被动的,那么我们在应急响应的时候就得先了解 ...