LibSvm流程及java代码测试
使用libSvm实现文本分类的基本过程,此文参考 使用libsvm实现文本分类 对前期数据准备及后续的分类测试进行了验证,同时对文中作者的分词组件修改成hanLP分词,对数字进行过滤,仅保留长度大于1的词进行处理。
转上文作者写的分类流程:
- 选择文本训练数据集和测试数据集:训练集和测试集都是类标签已知的;
- 训练集文本预处理:这里主要包括分词、去停用词、建立词袋模型(倒排表);
- 选择文本分类使用的特征向量(词向量):最终的目标是使得最终选出的特征向量在多个类别之间具有一定的类别区分度,可以使用相关有效的技术去实现特征向量的选择,由于分词后得到大量的词,通过选择降维技术能很好地减少计算量,还能维持分类的精度;
- 输出libsvm支持的量化的训练样本集文件:类别名称、特征向量中每个词元素分别到数字编号的映射转换,以及基于类别和特征向量来量化文本训练集,能够满足使用libsvm训练所需要的数据格式;
- 测试数据集预处理:同样包括分词(需要和训练过程中使用的分词器一致)、去停用词、建立词袋模型(倒排表),但是这时需要加载训练过程中生成的特征向量,用特征向量去排除多余的不在特征向量中的词(也称为降维);
- 输出libsvm支持的量化的测试样本集文件:格式和训练数据集的预处理阶段的输出相同;
- 使用libsvm训练文本分类器:使用训练集预处理阶段输出的量化的数据集文件,这个阶段也需要做很多工作(后面会详细说明),最终输出分类模型文件;
- 使用libsvm验证分类模型的精度:使用测试集预处理阶段输出的量化的数据集文件,和分类模型文件来验证分类的精度;
- 分类模型参数寻优:如果经过libsvm训练出来的分类模型精度很差,可以通过libsvm自带的交叉验证(Cross Validation)功能来实现参数的寻优,通过搜索参数取值空间来获取最佳的参数值,使分类模型的精度满足实际分类需要。
文本预处理阶段,增加了基于hanLP的分词,代码如下:
/**
* 使用hanlp进行分词
* Created by zhouyh on 2018/5/30.
*/
public class HanLPDocumentAnalyzer extends AbstractDocumentAnalyzer implements DocumentAnalyzer { private static final Log LOG = LogFactory.getLog(HanLPDocumentAnalyzer.class); public HanLPDocumentAnalyzer(ConfigReadable configuration) {
super(configuration);
} @Override
public Map<String, Term> analyze(File file) {
String doc = file.getAbsolutePath();
LOG.debug("Process document: file=" + doc);
Map<String, Term> terms = Maps.newHashMap();
BufferedReader br = null;
try {
br = new BufferedReader(new InputStreamReader(new FileInputStream(file), charSet));
String line = null;
while((line = br.readLine()) != null) {
LOG.debug("Process line: " + line);
List<com.hankcs.hanlp.seg.common.Term> termList = HanLP.segment(line);
if (termList!=null && termList.size()>0){
for (com.hankcs.hanlp.seg.common.Term hanLPTerm : termList){
String word = hanLPTerm.word;
if (!word.isEmpty() && !super.isStopword(word)){
if (word.trim().length()>1){
Pattern compile = Pattern.compile("(\\d+\\.\\d+)|(\\d+)|([\\uFF10-\\uFF19]+)");
Matcher matcher = compile.matcher(word);
if (!matcher.find()){
Term term = terms.get(word);
if (term == null){
term = new TermImpl(word);
terms.put(word, term);
}
term.incrFreq();
}
}
} else {
LOG.debug("Filter out stop word: file=" + file + ", word=" + word);
}
}
}
}
} catch (IOException e) {
throw new RuntimeException("", e);
} finally {
try {
if(br != null) {
br.close();
}
} catch (IOException e) {
LOG.warn(e);
}
LOG.debug("Done: file=" + file + ", termCount=" + terms.size());
}
return terms;
} public static void main(String[] args){
String filePath = "/Users/zhouyh/work/yanfa/xunlianji/UTF8/train/ClassFile/C000008/0.txt";
HanLPDocumentAnalyzer hanLPDocumentAnalyzer = new HanLPDocumentAnalyzer(new Configuration());
hanLPDocumentAnalyzer.analyze(new File(filePath));
String str = "测试hanLP分词";
System.out.println(str);
// Pattern compile = Pattern.compile("(\\d+\\.\\d+)|(\\d+)|([\\uFF10-\\uFF19]+)");
// Matcher matcher = compile.matcher("9402");
// if (matcher.find()){
// System.out.println(matcher.group());
// }
}
}
这里对原作者提供的训练集资源做了合并,将训练集扩大到10个类别,每个类别的8000文本中,前6000文本作为训练集,后2000文本作为测试集,文本结构如下图所示:
测试集中是同样的结构。
生成的特征向量与libsvm需要的训练集格式如下面所示:
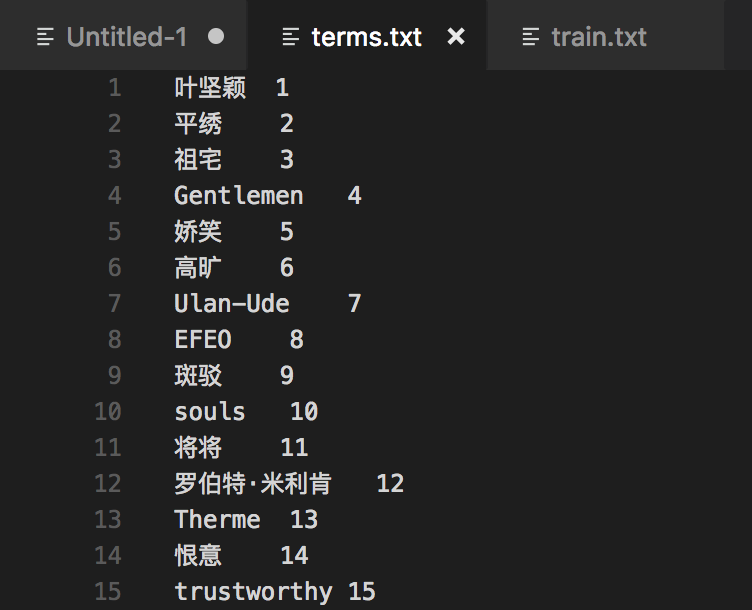
libsvm训练集格式文档:
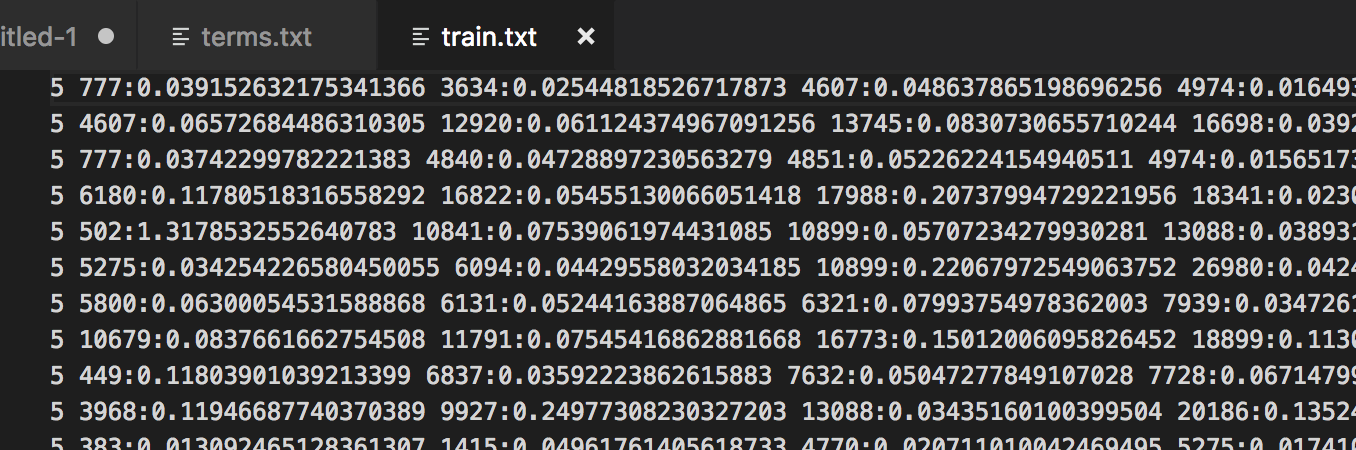
针对测试集也通过上述方式处理。
使用libSvm训练分类文本
文本转换:
./svm-scale -l 0 -u 1 /Users/zhouyh/work/yanfa/xunlianji/UTF8/heji/train.txt > /Users/zhouyh/work/yanfa/xunlianji/UTF8/heji/train-scale.txt
测试集也做同样转换:
./svm-scale -l 0 -u 1 /Users/zhouyh/work/yanfa/xunlianji/UTF8/heji/test.txt > /Users/zhouyh/work/yanfa/xunlianji/UTF8/heji/test-scale.txt
进行模型训练,此部分耗时较长:
./svm-train -h 0 -t 0 /Users/zhouyh/work/yanfa/xunlianji/UTF8/heji/train-scale.txt /Users/zhouyh/work/yanfa/xunlianji/UTF8/heji/model.txt
训练过程如下图所示:
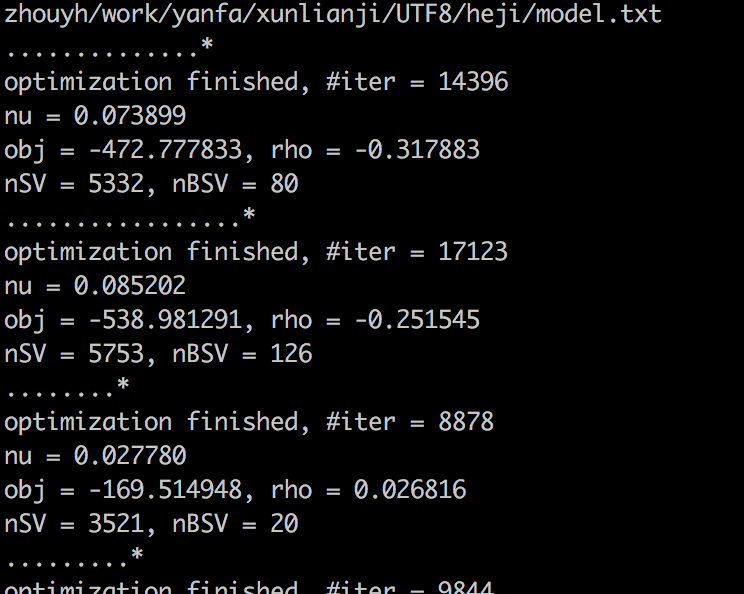
训练完成会生成model文件
采用预先处理好的测试文本进行分类测试:
./svm-predict /Users/zhouyh/work/yanfa/xunlianji/UTF8/heji/test-scale.txt /Users/zhouyh/work/yanfa/xunlianji/UTF8/heji/model.txt /Users/zhouyh/work/yanfa/xunlianji/UTF8/heji/predict.txt
得到结果为:Accuracy = 81.6568% (16333/20002) (classification)
整体流程做完,得到文件如下图所列:
至此,仿照原作者的思路,对libsvm的分类流程做了一次实践。
JAVA代码测试
建立相关java项目,引入libsvm的jar包,我这里采用maven搭建,引入jar包:
<!-- https://mvnrepository.com/artifact/tw.edu.ntu.csie/libsvm -->
<!-- libsvm jar包 -->
<dependency>
<groupId>tw.edu.ntu.csie</groupId>
<artifactId>libsvm</artifactId>
<version>3.17</version>
</dependency>
同时要把libsvm包中的svm_predict.java及svm_train.java引入,并对svm_predict.java的类做简单改动,将预测的结果值返回,测试代码如下:
public class LibSvmAlgorithm {
public static void main(String[] args){
String[] testArgs = {"/Users/zhouyh/work/yanfa/xunlianji/UTF8/heji/test-scale.txt", "/Users/zhouyh/work/yanfa/xunlianji/UTF8/heji/model.txt", "/Users/zhouyh/work/yanfa/xunlianji/UTF8/heji/predict1.txt"};
try {
Double accuracy = svm_predict.main(testArgs);
System.out.println(accuracy);
} catch (IOException e) {
e.printStackTrace();
}
}
}
LibSvm流程及java代码测试的更多相关文章
- 解决java代码测试http协议505错误
代码功能:通过java代码获取网页源代码: 所用工具:Myclipse8.5+tomcat6.0+浏览器 系统环境:windows xp旗舰版 火狐浏览器版本: IE浏览器版本: 测试http协议有错 ...
- 20.fastDFS集群java代码测试
1.工程结构 2.代码内容 FastdfsClientTest.java代码 package cn.itcast.fastdfs.cliennt; import java.io.File; i ...
- 通过Java代码浅谈HTTP协议
最近刚看了http协议,想写点东西加深一下理解,如果哪儿写错了,请指正. 1 介绍 HTTP是Hyper Text Transfer Protocol(超文本传输协议)的缩写.它的发展是万维网协会(W ...
- java代码模拟先入先出,fifo
最近在做一个先入先出的出库.琢磨了一下,写了一个简单的java代码测试: public static void main(String[] args) { LinkedList q = new Lin ...
- Spring+SpringMVC+MyBatis+easyUI整合优化篇(三)代码测试
日常啰嗦 看到标题你可能会问为什么这一篇会谈到代码测试,不是说代码优化么?前两篇主要是讲了程序的输出及Log4j的使用,Log能够帮助我们进行bug的定位,优化开发流程,而代码测试有什么用呢?其实测试 ...
- Java代码安全测试解决方案
Java代码安全测试解决方案: http://gdtesting.com/product.php?id=106
- JNI NDK (AndroidStudio+CMake )实现C C++调用Java代码流程
JNI/NDK Java调用C/C++前言 通过第三篇文章讲解在实际的开发过程中Java层调用C/C++层的处理流程.其实我们在很大的业务里也需要C/C+ +层去调用Java层,这两层之间的相互调用 ...
- 第一章 Java代码执行流程
说明:本文主要参考自<分布式Java应用:基础与实践> 1.Java代码执行流程 第一步:*.java-->*.class(编译期) 第二步:从*.class文件将其中的内容加载到内 ...
- JMETER通过java代码通过代码/ JMETER API实现示例进行负载测试
本教程试图解释Jmeter的基本设计,功能和用法,Jmeter是用于在应用程序上执行负载测试的优秀工具.通过使用jmeter GUI,我们可以根据我们的要求为请求创建测试样本并执行具有多个用户负载的样 ...
随机推荐
- How to install nginx in Ubuntu
The steps for installing the nginx on Ubuntu below. 1.install the packages first. apt-get install gc ...
- 06-Python元组,列表,字典,集合数据结构
一.简介 数据结构是我们用来处理一些数据的结构,用来存储一系列的相关数据. 在python中,有列表,元组,字典和集合四种内建的数据结构. 二.列表 用于存储任意数目.任意类型的数据集合.列表是内置可 ...
- day8 python 列表,元组,集合,字典的操作及方法 和 深浅拷贝
2.2 list的方法 # 增 list.append() # 追加 list.insert() # 指定索引前增加 list.extend() # 迭代追加(可迭代对象,打散追加) # 删 list ...
- 解决使用resin服务器Unsupported major.minor version 51.0错误
是因为jdk版本不对,更换成需要的版本
- 小白在使用ISE编写verilog代码综合时犯得错误及我自己的解决办法
一:错误原因,顶层信号声明类别错误 错误前 更改后 二:综合时警告 更改前: 错误原因:调用子模块时 输出端口只能用wire类型变量进行映射 这是verilog语法规定的 tx_done在uart_t ...
- Java 并发实践 — ConcurrentHashMap 与 CAS
转载 http://www.importnew.com/26035.html 最近在做接口限流时涉及到了一个有意思问题,牵扯出了关于concurrentHashMap的一些用法,以及CAS的一些概念. ...
- chrome浏览器hover时文字抖动bug
今天发现一个奇怪的bug,chrome浏览器里面 当父标签定位为fixed时,hover里面子标签时,文本会发生抖动,百思不得其解,经过多方查证,发现解决办法 -webkit-transform: ...
- 2018年5月15日临下班前找的一个读取assets下数据库的例子
网页 https://blog.csdn.net/li12412414/article/details/51958774 @Override protected void onCreate(Bun ...
- jmeter调试元件Debug Sampler的使用
@@@@@@@@@@@@@@@ 活在当下 今天记录一下jmeter调试工具Debug Sampler的心得,调试对于计算机从业人员来说是家常便饭,jmeter虽然代码不多,但是也需要调试,那么如何进行 ...
- MacOS下Git安装及使用
微信搜索"艺术行者",关注并回复关键词"git"获取Github安装包 上传的在线学习视频(黑马和传智双元,感谢) 微信搜索"艺术行者",关 ...