Hadoop基础-Hadoop的集群管理之服役和退役
Hadoop基础-Hadoop的集群管理之服役和退役
作者:尹正杰
版权声明:原创作品,谢绝转载!否则将追究法律责任。
在实际生产环境中,如果是上千万规模的集群,难免一个一个月会有那么几台服务器出点故障,在IDE机房这种事情几乎每个星期都会有那么几起事故发生,比如服务器断电,磁盘过慢,网络不同,核心路由故障,接入层交换机故障,在严重点就是一些二级运营商出口被攻击导致网络拥堵等等。刚刚说的这些事件都是我在实际工作中遇到的一些现象,因此,在大规模集群部署上,尤其是大数据,存储的都是海量数据,甚至可以用PB级别来形容,几十台服务器做大数据的公司估计也就是玩玩,像BATJ这样的大公司集群规模在4000个节点已经不再话下,每个服务器可插入的硬盘卡槽优先,4000台存储设备服务器,我生产中接触的是爱数的设备,他们有20个卡槽,每个卡槽可以装2T的文件,也就是一台机器只能保存40T文件,如果4000台这样的设备的话,也就160000T的数据,换算成PB差不多也就160PB的数据。
好了,说说我们本篇博客的重点,就是服务器的服役和退役,IDE人员喜欢统称这种操作为上架和下架。很久很久以前,去过北京朝阳酒仙桥的一个IDC机房实习了两个星期(那时候刚刚入职,领导让我去了解一下机房情况),其实用上架和下架来形容服役和退役的话不完全正确,为什么这么说呢?在IDE机房中,上架指的是给服务器通电,插上网线并将公网ip告知客户。下架就是断电将服务器或者网络设备归还给租户,而我们说的服役和退役,不仅仅是开机这么简单,而是让他进入工作状态,才是服役,而退役和其相反,就是不提供服务。
一.添加新节点的过程(服役)
>.在dfs. hosts文件中(hdfs-site-xml)包含新节点名称,该文件在NameNode的本地目录。
dfs. hosts属性是真正指定DataNode服务器的节点,相当于指定白名单。如下:
[/soft/hadoop/etc/hadoop/DataNodesHostname.txt]
s102
s103
s104 >.在hdfs-site-xml文件中添加属性
<property>
<name>dfs.hosts</name>
<value>/soft/hadoop/etc/hadoop/DataNodesHostname.txt</value>
</property> >.在NameNode上刷新节点(hdfs服务)
[yinzhengjie@s101 ~]$ hdfs dfsadmin -refreshNodes >.在NameNode上刷新节点(yarn服务,如果你没有启动该服务的话就可以暂时不管他)
[yinzhengjie@s101 ~]$ yarn rmadmin -refreshNodes >.在slaves文件中添加新节点ip(主机名)
一行代表一个主机,如下:
s102
s103
s104
s105 >.单独启动新节点中的datanode
[yinzhengjie@s101 ~]$ hadoop-daemon.sh start datanode
二.删除旧节点的过程(退役)
>.添加退役节点的ip到黑名单(dfs.hosts.exclude),不要更新白名单
案例如下:在下面的配置文件中写入相应的主机名
[/soft/hadoop/etc/dfs.hosts.exclude.txt]
s101
s102 >.配置hdfs-site.xml配置文件
<property>
<name>dfs.hosts.exclude</name>
<value>/soft/hadoop/etc/dfs.hosts.exclude.txt</value>
</property> >.在NameNode上刷新节点(hdfs服务)
[yinzhengjie@s101 ~]$ hdfs dfsadmin -refreshNodes >.在NameNode上刷新节点(yarn服务,如果你没有启动该服务的话就可以暂时不管他)
[yinzhengjie@s101 ~]$ yarn rmadmin -refreshNodes >.查看webUI
节点状态在decommisstion In Progresss >.当所有的要退役的节点都报告为Decommissioned
要退役的节点报告信息是Decommissioned ,说明退役成功。说明退役的过程就是在迁移数据到服役的节点中。 >.从白名单删除节点,并刷新节点
[yinzhengjie@s101 ~]$ hdfs dfsadmin -refreshNodes >.从slave文件中删除退役的节点
三.黑白名单的组合情况

四.节点的服役案例展示
1>.查看webUI的界面
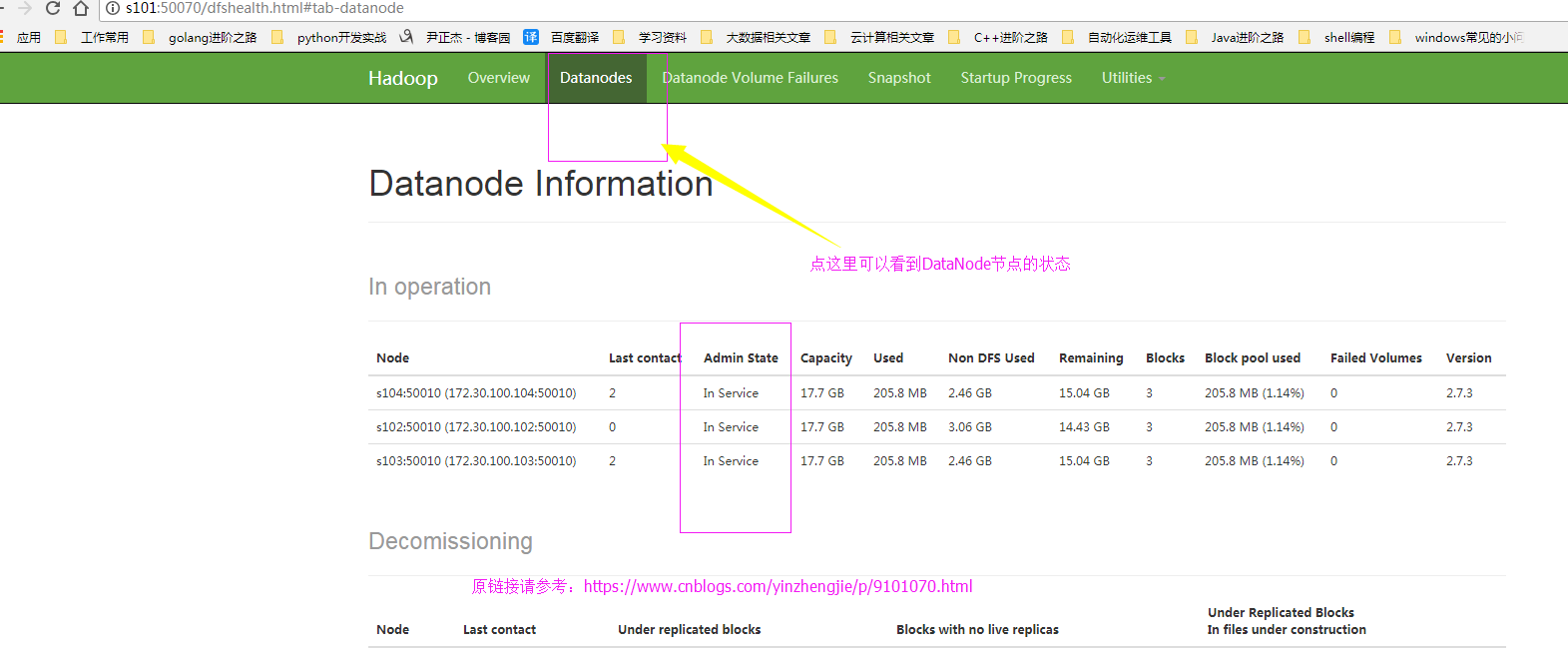
2>.编辑hdfs-site.xml 配置文件
[yinzhengjie@s101 ~]$ more /soft/hadoop/etc/hadoop/hdfs-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>dfs.replication</name>
<value></value>
</property>
<!--
<property>
<name>dfs.hosts</name>
<value>/soft/hadoop/etc/hadoop/DataNodesHostname.txt</value>
</property>
-->
<property>
<name>dfs.hosts.exclude</name>
<value>/soft/hadoop/etc/dfs.hosts.exclude.txt</value>
</property> </configuration> <!--
hdfs-site.xml 配置文件的作用:
#HDFS的相关设定,如文件副本的个数、块大小及是否使用强制权限
等,此中的参数定义会覆盖hdfs-default.xml文件中的默认配置. dfs.replication 参数的作用:
#为了数据可用性及冗余的目的,HDFS会在多个节点上保存同一个数据
块的多个副本,其默认为3个。而只有一个节点的伪分布式环境中其仅用
保存一个副本即可,这可以通过dfs.replication属性进行定义。它是一个
软件级备份。 dfs.hosts 参数的作用:
#添加白名单,功能和黑名单(dfs.hosts.exclude)相反。我这里是将其注释掉了。 dfs.hosts.exclude 参数的作用:
#这是我们添加的黑名单,该属性的value定义的是一个配置文件,这个配置文件的主机就是需要退役的节点。 -->
[yinzhengjie@s101 ~]$
3>.编辑黑名单
[yinzhengjie@s101 ~]$ more /soft/hadoop/etc/dfs.hosts.exclude.txt
s102
[yinzhengjie@s101 ~]$
4>.刷新NameNode节点
[yinzhengjie@s101 ~]$ hdfs dfsadmin -refreshNodes
Refresh nodes successful
[yinzhengjie@s101 ~]$
5>.上线新的节点(这台机器配置需要和完全分布式的DataNode模式一致),启动DataNode服务
[yinzhengjie@s105 ~]$ ll /soft/hadoop/etc/
total
drwxr-xr-x. yinzhengjie yinzhengjie May : full
drwxr-xr-x. yinzhengjie yinzhengjie May : local
drwxr-xr-x. yinzhengjie yinzhengjie May : pseudo
[yinzhengjie@s105 ~]$
[yinzhengjie@s105 ~]$ ln -s /soft/hadoop/etc/full/ /soft/hadoop/etc/hadoop
[yinzhengjie@s105 ~]$
[yinzhengjie@s105 ~]$ ll /soft/hadoop/etc/
total
drwxr-xr-x. yinzhengjie yinzhengjie May : full
lrwxrwxrwx. yinzhengjie yinzhengjie May : hadoop -> /soft/hadoop/etc/full/
drwxr-xr-x. yinzhengjie yinzhengjie May : local
drwxr-xr-x. yinzhengjie yinzhengjie May : pseudo
[yinzhengjie@s105 ~]$
[yinzhengjie@s105 ~]$ hadoop-daemon.sh start datanode
starting datanode, logging to /soft/hadoop-2.7./logs/hadoop-yinzhengjie-datanode-s105.out
[yinzhengjie@s105 ~]$ jps
Jps
DataNode
[yinzhengjie@s105 ~]$
6>.再次查看webUI界面,查看新节点是否上线
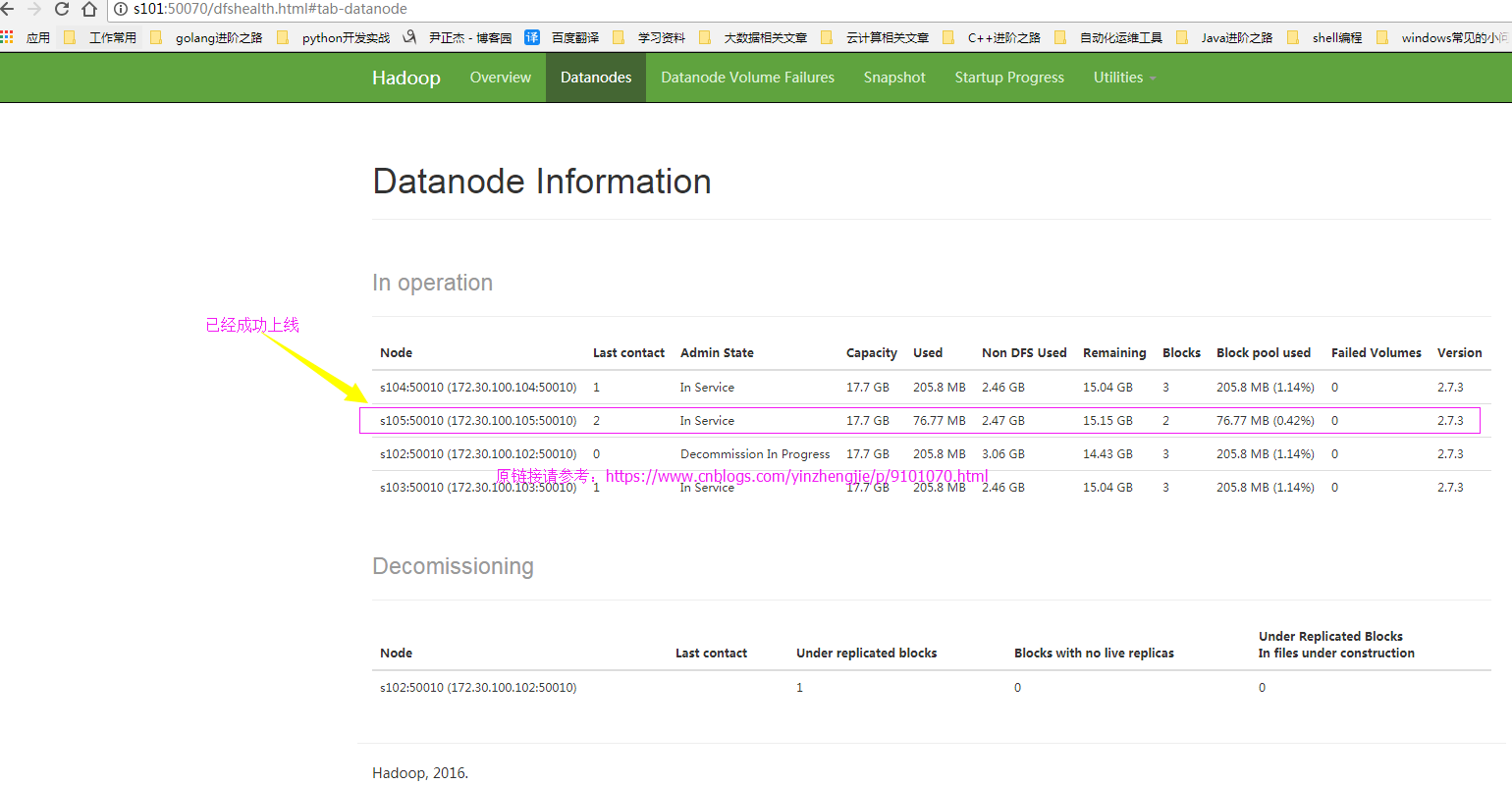
7>.确认退役成功
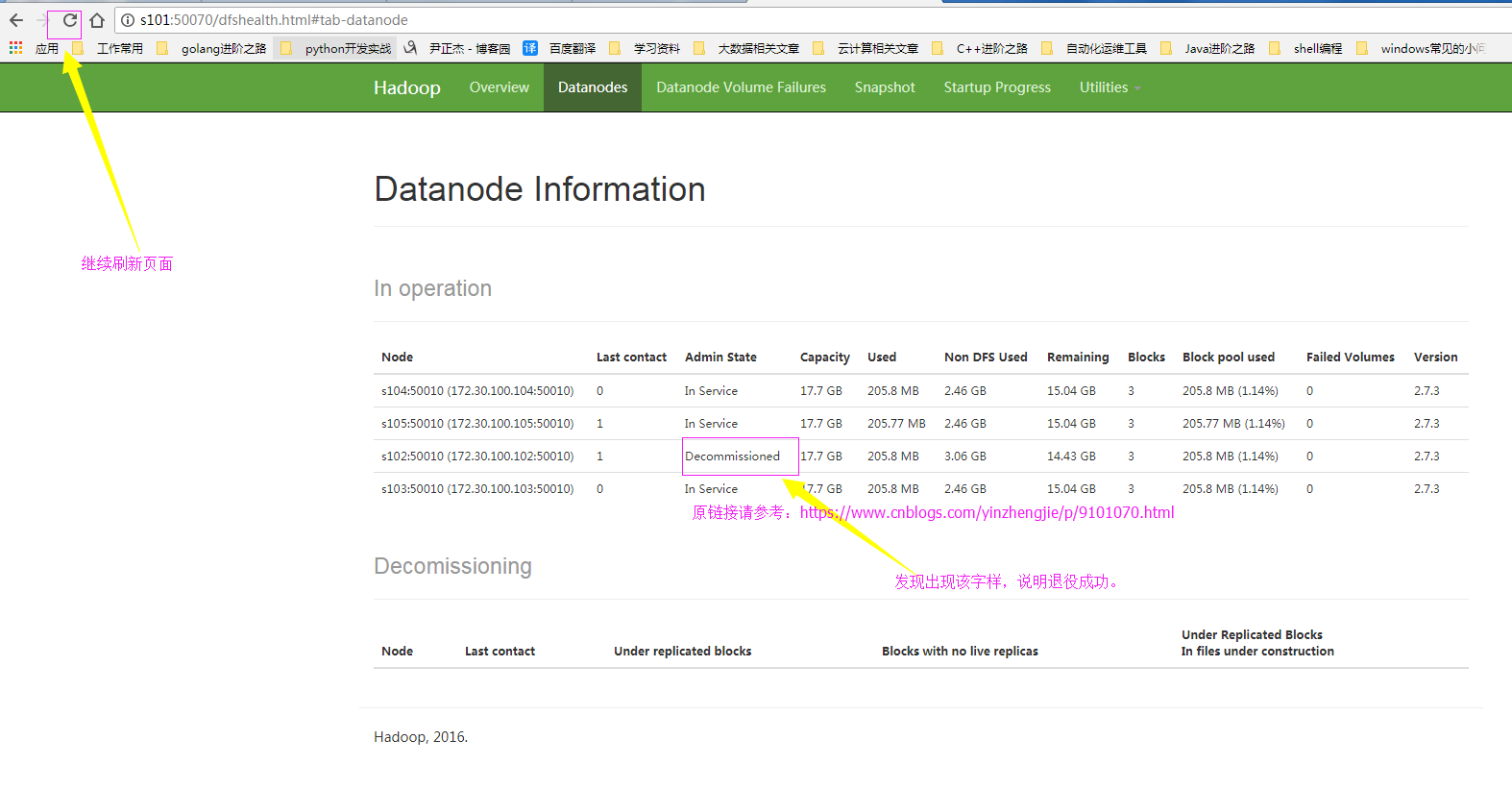
四.节点的服役案例展示
1>.查webUI界面,发现新服役的节点正常工作但是之前的退役节点还在,我们需要将退役的节点删除掉!
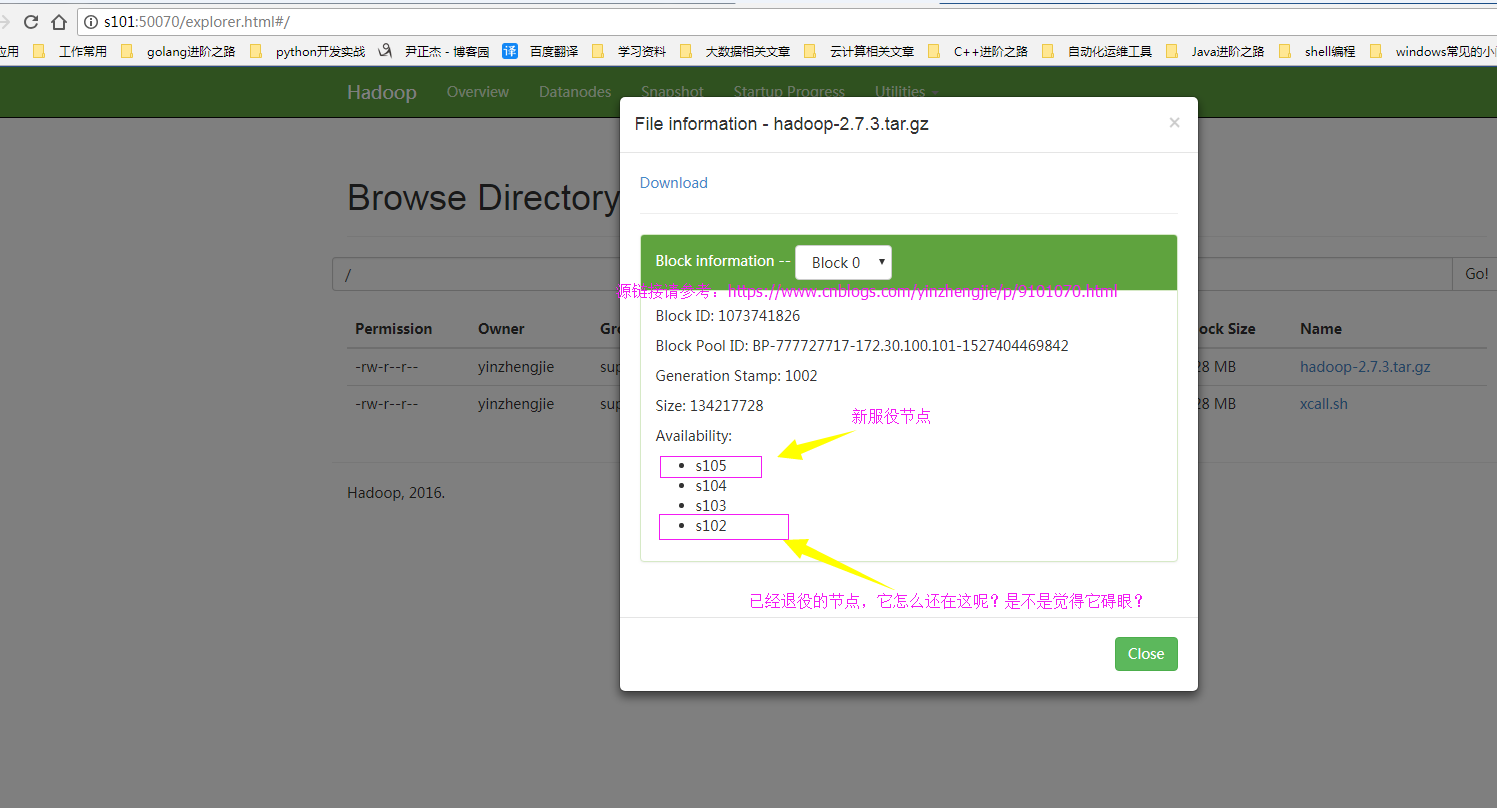
2>.编辑hdfs-site.xml 配置文件
[yinzhengjie@s101 ~]$ more /soft/hadoop/etc/hadoop/hdfs-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>dfs.replication</name>
<value></value>
</property> <property>
<name>dfs.hosts</name>
<value>/soft/hadoop/etc/hadoop/DataNodesHostname.txt</value>
</property>
<property>
<name>dfs.hosts.exclude</name>
<value>/soft/hadoop/etc/dfs.hosts.exclude.txt</value>
</property> </configuration> <!--
hdfs-site.xml 配置文件的作用:
#HDFS的相关设定,如文件副本的个数、块大小及是否使用强制权限
等,此中的参数定义会覆盖hdfs-default.xml文件中的默认配置. dfs.replication 参数的作用:
#为了数据可用性及冗余的目的,HDFS会在多个节点上保存同一个数据
块的多个副本,其默认为3个。而只有一个节点的伪分布式环境中其仅用
保存一个副本即可,这可以通过dfs.replication属性进行定义。它是一个
软件级备份。 dfs.include 参数的作用:
#添加白名单,功能和黑名单(dfs.hosts.exclude)相反。 dfs.hosts.exclude 参数的作用:
#这是我们添加的黑名单,该属性的value定义的是一个配置文件,这个配置文件的主机就是需要退役的节点。 -->
[yinzhengjie@s101 ~]$
3>.编辑白名单
[yinzhengjie@s101 ~]$ more /soft/hadoop/etc/hadoop/DataNodesHostname.txt
s103
s104
s105
[yinzhengjie@s101 ~]$
4>.查看当前的webUI界面(节点已经处于退役状态)
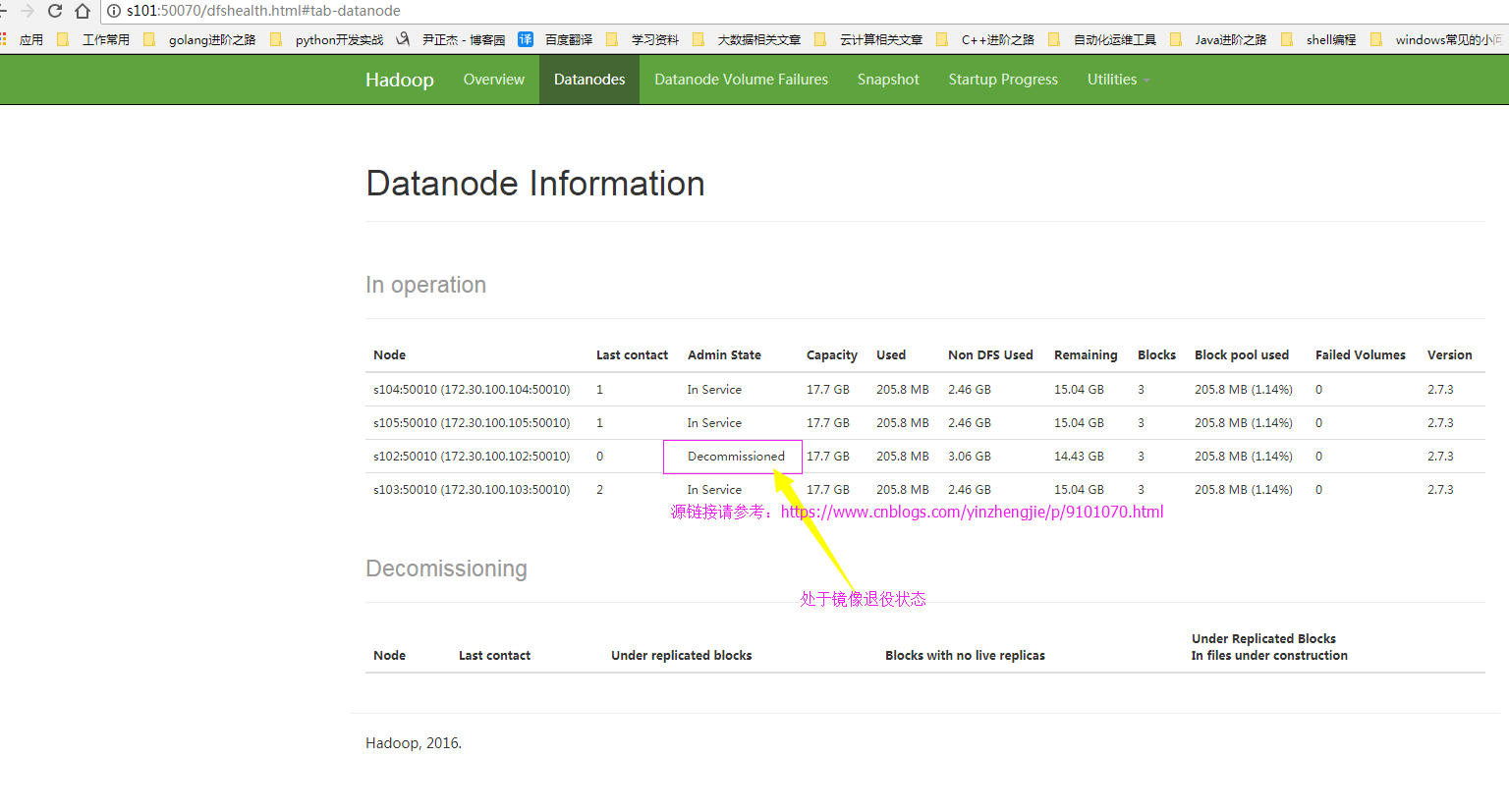
5>.刷新NameNode节点
[yinzhengjie@s101 ~]$ hdfs dfsadmin -refreshNodes
Refresh nodes successful
[yinzhengjie@s101 ~]$
6>.webUI确认刷新成功
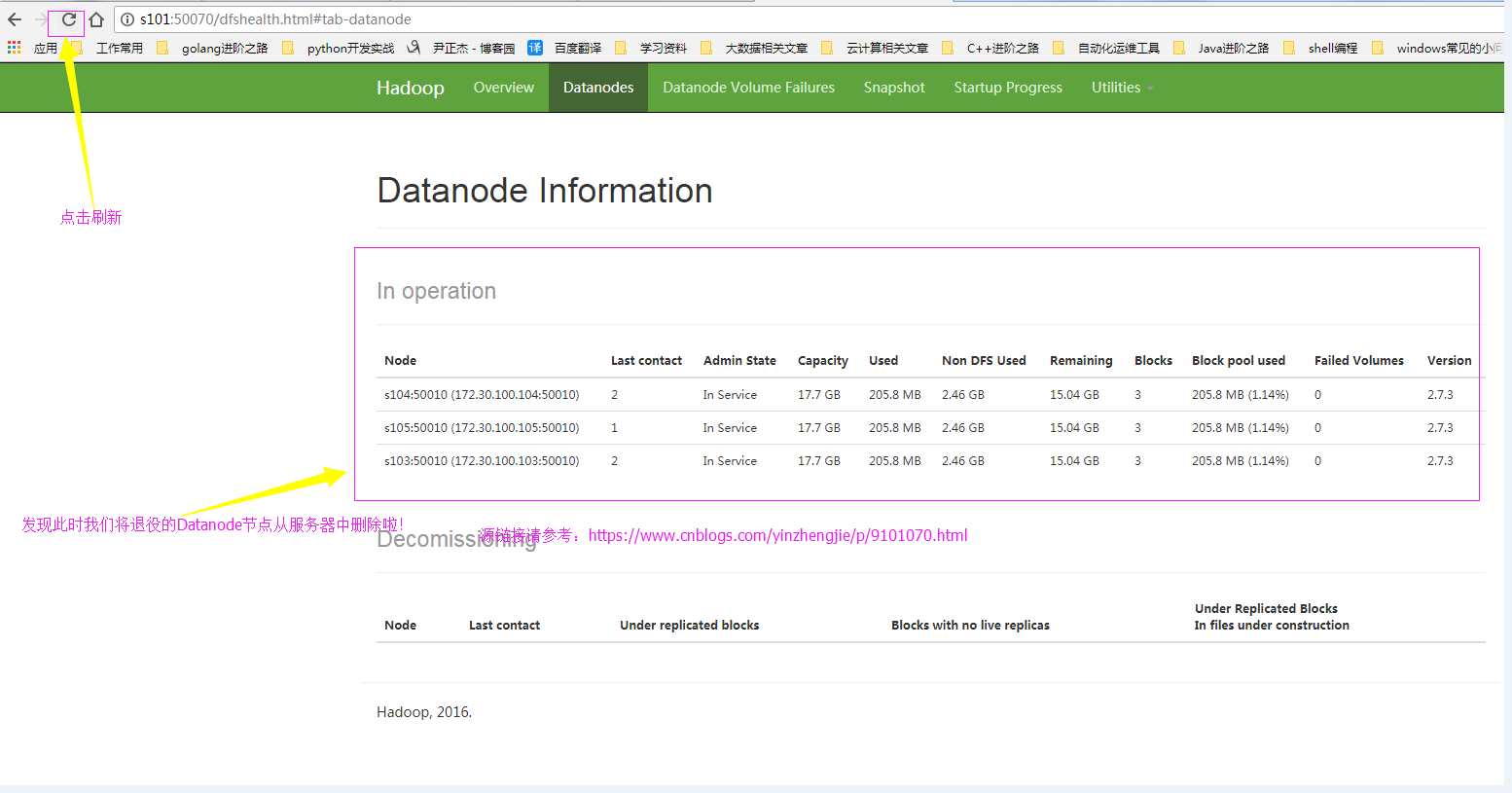
六.yarn的服役和退役
如果你会了hdfs的服役和退役的话,其实yarn就是so easy的一件事啦,就是照猫画虎的方法,步骤重复过程较多,我就懒得截图了,配置过程跟我上面配置hdfs不愁类似,相信你有举一反三的能力哟。
>.首先修改yarn的配置文件("yarn-site-xml")。修改其属性“yarn.resourcemanager.nodes.exclude-path”即可,黑名单配置如下:
[/sotf/hadoop/etc/hadoop/yarn-site.xml]
<property>
<name>yarn.resourcemanager.nodes.exclude-path</name>
<value>/soft/hadoop/etc/hadoop/yarn.exclude.hosts</value>
</property>
对了,如果想要配置白名单的话,需要设置“yarn.resourcemanager.nodes.include-path”属性哟!
>.编辑yarn的配置文件“yarn.resourcemanager.nodes.exclude-path”
修改配置文件内容如下:
[/soft/hadoop/etc/hadoop/yarn.exclude.hosts]
s102
>.刷新节点
配置上述步骤后及得刷新节点,使用命令:“[yinzhengjie@s101 ~]$ yarn rmadmin -refreshNodes” 即可。
>.单独启动新的节点中 nodemanager
[yinzhengjie@s101 ~]$ yarn-daemon.sh start nodemananger
Hadoop基础-Hadoop的集群管理之服役和退役的更多相关文章
- Apache Hadoop 2.9.2 的集群管理之服役和退役
Apache Hadoop 2.9.2 的集群管理之服役和退役 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 随着公司业务的发展,客户量越来越多,产生的日志自然也就越来越大来,可能 ...
- Cloudera Hadoop 4 实战课程(Hadoop 2.0、集群界面化管理、电商在线查询+日志离线分析)
课程大纲及内容简介: 每节课约35分钟,共不下40讲 第一章(11讲) ·分布式和传统单机模式 ·Hadoop背景和工作原理 ·Mapreduce工作原理剖析 ·第二代MR--YARN原理剖析 ·Cl ...
- Hadoop集群管理
1.简介 Hadoop是大数据通用处理平台,提供了分布式文件存储以及分布式离线并行计算,由于Hadoop的高拓展性,在使用Hadoop时通常以集群的方式运行,集群中的节点可达上千个,能够处理PB级的数 ...
- 【原创 Hadoop&Spark 动手实践 5】Spark 基础入门,集群搭建以及Spark Shell
Spark 基础入门,集群搭建以及Spark Shell 主要借助Spark基础的PPT,再加上实际的动手操作来加强概念的理解和实践. Spark 安装部署 理论已经了解的差不多了,接下来是实际动手实 ...
- hadoop搭建伪分布式集群(centos7+hadoop-3.1.0/2.7.7)
目录: Hadoop三种安装模式 搭建伪分布式集群准备条件 第一部分 安装前部署 1.查看虚拟机版本2.查看IP地址3.修改主机名为hadoop4.修改 /etc/hosts5.关闭防火墙6.关闭SE ...
- hadoop基础----hadoop实战(七)-----hadoop管理工具---使用Cloudera Manager安装Hadoop---Cloudera Manager和CDH5.8离线安装
hadoop基础----hadoop实战(六)-----hadoop管理工具---Cloudera Manager---CDH介绍 简介 我们在上篇文章中已经了解了CDH,为了后续的学习,我们本章就来 ...
- hadoop基础----hadoop实战(九)-----hadoop管理工具---CDH的错误排查(持续更新)
在CDH安装完成后或者CDH使用过程中经常会有错误或者警报,需要我们去解决,积累如下: 解决红色警报 时钟偏差 这是因为我们的NTP服务不起作用导致的,几台机子之间有几秒钟的时间偏差. 这种情况下一是 ...
- hadoop 2.2.0 集群部署 坑
注意fs.defaultFS为2..0新的变量,代替旧的:fs.default.name hadoop 2.2.0 集群启动命令:bin/hdfs namenode -formatsbin/start ...
- hadoop 2.2.0集群安装
相关阅读: hbase 0.98.1集群安装 本文将基于hadoop 2.2.0解说其在linux集群上的安装方法,并对一些重要的设置项进行解释,本文原文链接:http://blog.csdn.net ...
随机推荐
- 字符是否为SQL的保留字
要想知道字符是否为MS SQL Server保留字,那我们必须把SQL所有保留字放在一个数据集中.然后我们才能判断所查找的字符是否被包含在数据集中. MS SQL Server保留字: ) = 'ad ...
- SQL Server 2008初次启动
一.关于安装 SQL Server 数据库的安装,经过自己的安装,总体还是比较容易,没有太多难度,安装包在网上也有很多,在此,就跳过安装的这一步. 二.初次启动SQL Server 安装完成数据库后, ...
- Linux分页机制之概述--Linux内存管理(六)
1 分页机制 在虚拟内存中,页表是个映射表的概念, 即从进程能理解的线性地址(linear address)映射到存储器上的物理地址(phisical address). 很显然,这个页表是需要常驻内 ...
- Linux学习历程——Centos 7 mkdir命令
一.命令介绍 mkdir 命令用于创建空白目录格式为“mkdir [选项] 目录”, 除了能够创建单个空白目录,还能结合 -p 参数来递归创建具有嵌套层叠关系的文件目录. -------------- ...
- VMware虚拟机在仅主机模式下的网卡无法动态获取IP
自己在VMware虚拟机中开启一台主机的时候,发现比以往的开机速度慢了好多,起初不以为然,直到用Xshell通过ssh远程连接eth1的ip地址才发现连接失败(这个ip是之前eth1正常的时候获取的i ...
- JS第一部分--ECMAScript5.0标准语法 (JS基础语法)
一,调试语句 二,JS的引入方式 三,变量的使用 四,基本的数据类型 4.1,基本数据类型转换 4.2,字符串的常用方法 五,复杂数据类型 5.1,Array(数组)及常用方法 六,流程控制( 逻辑与 ...
- docker 安装 fastdfs
fastdfs 安装 //1.拉取镜像 docker pull morunchang/fastdfs //2.启动tracker docker run -d --name tracker --net= ...
- Linux下添加windows字体
在Linux下使用wqy字体,在视觉效果上就已近很好了,其实没有必要添加windows字体.但是显然有些人(比如领导,^..^)就喜欢宋体.楷体,所以添加windows字体有时还是需要的,幸运的是这件 ...
- MyIASM和Innodb引擎详解
MyIASM 和 Innodb引擎详解 Innodb引擎 Innodb引擎提供了对数据库ACID事务的支持,并且实现了SQL标准的四种隔离级别,关于数据库事务与其隔离级别的内容请见数据库事务与其隔离级 ...
- 日版iphone5 SB 配合REBELiOS卡贴破解电信3G步骤
1.插入贴膜卡和sim卡:进入“设置—电话—sim卡应用程序”选择CDMA电信解锁: 2.越狱设备,添加cydia.gpplte.com源,安装“6S/6/5S/5C/5电信新补丁”: 3.打卡gpp ...