爬虫系列---scrapy post请求、框架组件和下载中间件+boss直聘爬取
一 Post 请求
在爬虫文件中重写父类的start_requests(self)方法
- 父类方法源码(Request):
def start_requests(self):
for url in self.start_urls:
yield scrapy.Request(url=url,callback=self.parse)
- 重写该方法(FormRequests(url=url,callback=self.parse,formdata=data))
def start_requests(self):
data={
'kw': 'xml',
}
for url in self.start_urls:
#post请求,并传递参数
yield scrapy.FormRequest(url=url,callback=self.parse,formdata=data)
二 多页面手动爬去数据
import scrapy
from QiubaiPagePro.items import QiubaipageproItem class QiubaiSpider(scrapy.Spider):
name = 'qiubai'
# allowed_domains = ['xxx.com']
start_urls = ['https://www.qiushibaike.com/text/']
'''
https://www.qiushibaike.com/text/page/13/
'''
url='https://www.qiushibaike.com/text/page/%d/'
#手动发起请求
page=1 def parse(self, response):
div_list = response.xpath('//div[@id="content-left"]/div')
for div in div_list:
author = div.xpath('./div[1]/a[2]/h2/text()').extract_first()
content = div.xpath('./a[1]/div[@class="content"]/span//text()').extract()
content = "".join(content) #实例管道对象
item=QiubaipageproItem()
item['author']=author
item['content']=content.strip()
yield item
- 1 构造请求url的格式
url='https://www.qiushibaike.com/text/page/%d/'
#手动发起请求
page=1
- 2 手动发送请求
if self.page<=12:
self.page += 1
url=format(self.url%self.page)
#手动发送请求
yield scrapy.Request(url=url,callback=self.parse)
三 五大核心组件
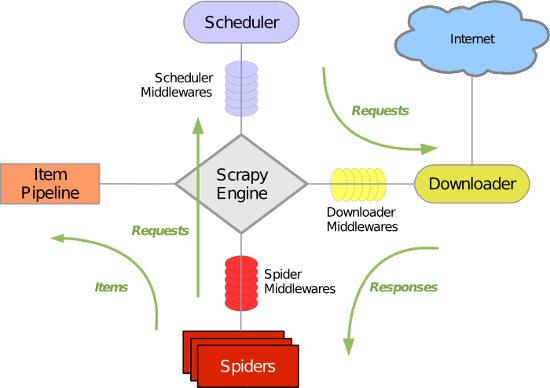
- 引擎(Scrapy)用来处理整个系统的数据流,触发事务(框架核心)
- 调度器(Scheduler) 用来接收应勤发过来的请求,压入队列中,并在引擎再次发起请求的时候返回,可以想象成一个url的优先队列,他决定下一个要爬取的网址是什么,同时去重复的网址。
- 下载器(Downloader)用于下载页面内容,并将页面内容返回给引擎。
- 爬虫(Spider)爬虫主要是干活的,用于从特定的网页中提取自己需要的信息。用户可以在这里面编写程序,从网页中提取链接,让scrapy继续爬取下一个页面。
- 项目管理(Pipeline)负责处理爬虫从网页中爬取的数据,主要功能是持久存储,验证实体的有效性,清楚不需要的信息,当也被爬虫解析后,将被发送到项目管道,经过几个特点的次序处理数据
四 下载中间件
class QiubaipageproDownloaderMiddleware(object):
#拦截请求
def process_request(self, request, spider):
#设置代理
request.meta['proxy']='119.176.66.90:9999'
print('this is process_request')
#拦截响应
def process_response(self, request, response, spider):
# Called with the response returned from the downloader.
# Must either;
# - return a Response object
# - return a Request object
# - or raise IgnoreRequest
return response
#拦截发生异常的请求对象
def process_exception(self, request, exception, spider):
# 设置代理
request.meta['proxy'] = 'https:119.176.66.90:9999'
print('this is process_request')
setting中开启下载中间键
DOWNLOADER_MIDDLEWARES = {
'QiubaiPagePro.middlewares.QiubaipageproDownloaderMiddleware': 543,
}
五 boss直聘爬取
- bossspider.py 爬虫文件
# -*- coding: utf-8 -*-
import scrapy
from BossPro.items import BossproItem class BossspiderSpider(scrapy.Spider):
name = 'bossspider'
# allowed_domains = ['boss.com']
start_urls = ['https://www.zhipin.com/c101280600/?query=python%E7%88%AC%E8%99%AB&ka=sel-city-101280600'] def parse(self, response):
li_list=response.xpath('//div[@class="job-list"]/ul/li')
for li in li_list:
job_name=li.xpath('.//div[@class="job-title"]/text()').extract_first()
company_name=li.xpath('.//div[@class="info-company"]/div[1]/h3/a/text()').extract_first()
detail_url='https://www.zhipin.com'+li.xpath('.//div[@class="info-primary"]/h3/a/@href').extract_first()
#实例项目对象,给管道传输数据
item=BossproItem()
item['job_name']=job_name.strip()
item['company_name']=company_name.strip() #手动发起get请求,并通过meta给回调函数传参
yield scrapy.Request(url=detail_url,callback=self.parse_detail,meta={'item':item}) def parse_detail(self,response):
#从meta中取出参数item
item=response.meta['item']
job_desc = response.xpath('//*[@id="main"]/div[3]/div/div[2]/div[2]/div[1]/div//text()').extract()
job_desc = ''.join(job_desc).strip()
job_desc=job_desc.replace(';','\n')
job_desc = job_desc.replace(';', '\n')
job_desc = job_desc.replace('。', '\n')
item['job_desc']=job_desc yield item
- items.py
import scrapy class BossproItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
job_name = scrapy.Field()
company_name = scrapy.Field()
job_desc = scrapy.Field()
- pipelines.py
# -*- coding: utf-8 -*- # Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html class BossproPipeline(object):
fp=None def open_spider(self,spider):
self.fp=open('boss.txt','w',encoding='utf-8') def process_item(self, item, spider):
# print(item)
self.fp.write(item['job_name']+":"+item['company_name'])
self.fp.write('\n'+item['job_desc']+'\n\n')
return item def close_spider(self,spider):
pass
- setings.py
USER_AGENT = 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.119 Safari/537.36' #UA
ROBOTSTXT_OBEY = False #不遵从robots协议
ITEM_PIPELINES = {
'BossPro.pipelines.BossproPipeline': 300, #开启item_pipelines
}
爬虫系列---scrapy post请求、框架组件和下载中间件+boss直聘爬取的更多相关文章
- Python爬虫——Scrapy整合Selenium案例分析(BOSS直聘)
概述 本文主要介绍scrapy架构图.组建.工作流程,以及结合selenium boss直聘爬虫案例分析 架构图 组件 Scrapy 引擎(Engine) 引擎负责控制数据流在系统中所有组件中流动,并 ...
- scrapy——7 scrapy-redis分布式爬虫,用药助手实战,Boss直聘实战,阿布云代理设置
scrapy——7 什么是scrapy-redis 怎么安装scrapy-redis scrapy-redis常用配置文件 scrapy-redis键名介绍 实战-利用scrapy-redis分布式爬 ...
- Pyhton爬虫实战 - 抓取BOSS直聘职位描述 和 数据清洗
Pyhton爬虫实战 - 抓取BOSS直聘职位描述 和 数据清洗 零.致谢 感谢BOSS直聘相对权威的招聘信息,使本人有了这次比较有意思的研究之旅. 由于爬虫持续爬取 www.zhipin.com 网 ...
- Scrapy 爬取BOSS直聘关于Python招聘岗位
年前的时候想看下招聘Python的岗位有多少,当时考虑目前比较流行的招聘网站就属于boss直聘,所以使用Scrapy来爬取下boss直聘的Python岗位. 1.首先我们创建一个Scrapy 工程 s ...
- Python的scrapy之爬取boss直聘网站
在我们的项目中,单单分析一个51job网站的工作职位可能爬取结果不太理想,所以我又爬取了boss直聘网的工作,不过boss直聘的网站一次只能展示300个职位,所以我们一次也只能爬取300个职位. jo ...
- python爬虫10 | 网站维护人员:真的求求你们了,不要再来爬取了!!
今天 小帅b想给大家讲一个小明的小故事 ... 话说 在很久很久以前 小明不小心发现了一个叫做 学习python的正确姿势 的公众号 从此一发不可收拾 看到什么网站都想爬取 有一天 小明发现了一个小黄 ...
- Python 网络爬虫 006 (编程) 解决下载(或叫:爬取)到的网页乱码问题
解决下载(或叫:爬取)到的网页乱码问题 使用的系统:Windows 10 64位 Python 语言版本:Python 2.7.10 V 使用的编程 Python 的集成开发环境:PyCharm 20 ...
- Python 网络爬虫 005 (编程) 如何编写一个可以 下载(或叫:爬取)一个网页 的网络爬虫
如何编写一个可以 下载(或叫:爬取)一个网页 的网络爬虫 使用的系统:Windows 10 64位 Python 语言版本:Python 2.7.10 V 使用的编程 Python 的集成开发环境:P ...
- 爬虫系列---scrapy全栈数据爬取框架(Crawlspider)
一 简介 crawlspider 是Spider的一个子类,除了继承spider的功能特性外,还派生了自己更加强大的功能. LinkExtractors链接提取器,Rule规则解析器. 二 强大的链接 ...
随机推荐
- FTP解决连接慢问题
今天发现程序报登录FTP超时,于是便手动登录发现真的慢,于是网上搜便获取大招亲测有效,于是怕忘的我马上记录下来,zzzzzzz!! 如下解决 vim /etc/vsftpd/vsftpd.conf 在 ...
- asp.net core系列 32 EF查询数据 必备知识(1)
一.查询的工作原理 Entity Framework Core 使用语言集成查询 (LINQ) 来查询数据库中的数据. 通过 LINQ 可使用 C#(或你选择的其他 .NET 语言)基于派生上下文和实 ...
- 在越狱的iPhone/iPad上安装自开发环境
自开发跟自编译意思一样,后者表示一个开发语言的开发能力成熟度:前者则表示一个开发平台的开发能力成熟度. iPhone跟iPad面世这么多年,一直无法摆脱"娱乐"工具的宿命.Appl ...
- [四] JavaIO之类层次体系结构横向比对
IO家族类层次体系结构横向匹配 上一篇文章中主要介绍了JavaIO流家族的整体设计思路,简单回顾下 基本逻辑涉及数据源 流的方向,以及流的数据形式这三个部分的组合 按照流的数据形式和流的方向, ...
- springboot情操陶冶-web配置(四)
承接前文springboot情操陶冶-web配置(三),本文将在DispatcherServlet应用的基础上谈下websocket的使用 websocket websocket的简单了解可见维基百科 ...
- Python机器学习笔记 使用scikit-learn工具进行PCA降维
之前总结过关于PCA的知识:深入学习主成分分析(PCA)算法原理.这里打算再写一篇笔记,总结一下如何使用scikit-learn工具来进行PCA降维. 在数据处理中,经常会遇到特征维度比样本数量多得多 ...
- 【记录一次坑经历】axios使用x-www-form-urlencoded 服务器报400(错误的请求。 )(后端.Net MVC5 WebApi OAuth,前端Electron-Vue)
首先放上源码 electron-vue axios 注册 import Vue from 'vue' import axios from 'axios' axios.defaults.baseUR ...
- [转]koa-router使用指南
更多参考:https://www.npmjs.com/package/koa-router 本文转自:https://blog.csdn.net/luchuanqi67/article/details ...
- ASP.NET MVC Session 过期验证跳转至登入页面
一.在要检查登入的控制器上继承 CheckLoginController 类 2. CheckLoginController 类的写法 using System; using System.Colle ...
- [PHP] PHP多个进程配合redis的有序集合实现大文件去重
1.对一个大文件比如我的文件为 -rw-r--r-- 1 ubuntu ubuntu 9.1G Mar 1 17:53 2018-12-awk-uniq.txt 2.使用split命令切割成10 ...