【Java集合系列五】HashMap解析
2017-07-31 19:36:00
一、简介
1、HashMap作用及使用场景
HashMap利用数组+单向链表的方式,实现了key-value型数据的存储功能。HashMap的size永远是2^x的值,主要是为了更加均衡的使用数组位置。
2、存储key-value型数据的数据结构
如下代码,HashMap中定义了Node类,实现了Map.Entry接口,Entry接口只有set和get方法定义,极其简单。Node中定义了key、value、hash及指向下一个Node的指针next,Node类其实也可以作为单向链表。
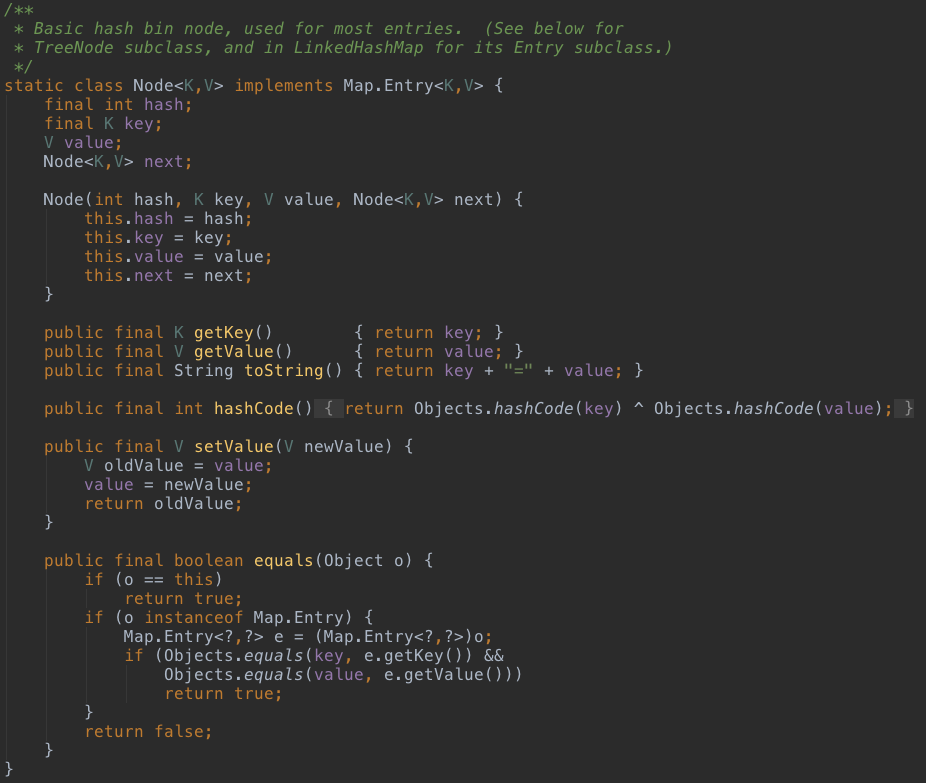
3、HashMap的存储方式
HashMap采用数组+链表的方式存储数据,链表就是前面提到的Node类,数组如下:
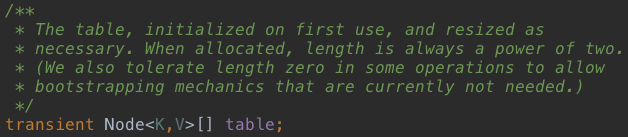
4、HashMap几个重要参数

要想了解HashMap的扩容策略,先看看这几个默认值:
默认容量为16,最大容量为2^30,默认加载因子0.75f。后面3个TREEIFY相关的参数,都是使用tree存存数据时所用,暂时不用理会。
再看几个成员变量:
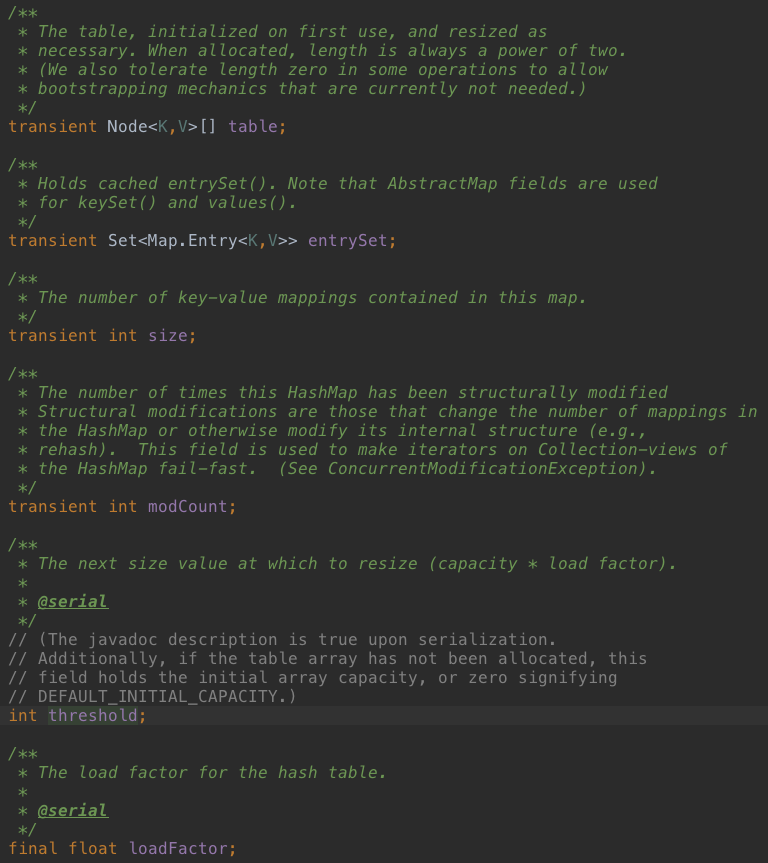
如上图:
table:存数据的数组;
entrySet:是entrySet()的返回值,被当做缓存,这样调用entrySet()方法时不用每次都重新创建一个Set对象;
size:key-value数据的数量;
modCount:防止并发修改的标志位;
threshold:临界值,超过这个临界值要需要扩容;
loadFactor:加载因子,用于计算临界值;
5、HashMap初始容量
HashMap的处理容量要么是默认值,要么使用用户设置的capacity,先看默认值。使用new HashMap()构造器,会使用默认capacity,代码如下:

奇怪了,这里怎么没有new数组呢?构造器中没有创建数组,说明数组的创建采用的是lazy策略,肯定要在put元素之前创建,要么数据存哪里?看看put方法,put方法调用了包级访问权限的putVal(),putVal()又调用了resize(),有如下代码:
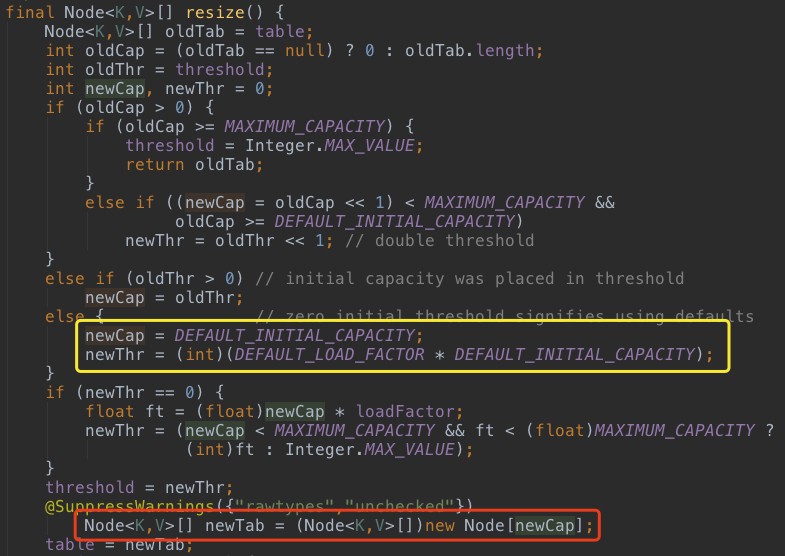
看到了吧,如果table数组为null,在这里创建了数组。
那么用户设置了capacity的HashMap是如何初始化的?使用new HashMap(int capacity)构造器:

最终调用了这个构造器,加载因子是默认值。这里也并没有new数组,而是计算了临界值。Android的HashMap源码就清晰多了,不像这里搞这么繁琐。在前一张图片resize()方法中,如果table的size为0,且newThr大于0,则会按照newThr的大小创建数组。前面提到HashMap的size永远是2的幂次值,那现在看看newThr是怎么计算出来的?看看tableSizeFor()方法:

这个方法的作用找到最小的大于cap的2^n的值,so即便我们设置不是一个2^n的值,HashMap也会帮我们处理的。至于为什么一定要是2^n,后面再详细解释。
====================================================================================================================
注:以上分析基于jdk中HashMap源码,从现在开始使用Android的HashMap源码分析,主要原因是Android的HashMap源码中剔除了一些无用的代码,结构更加清晰,便于了解其原理。
====================================================================================================================
二、HashMap中一些重要的方法
1、put(K key, V value)及扩容原理
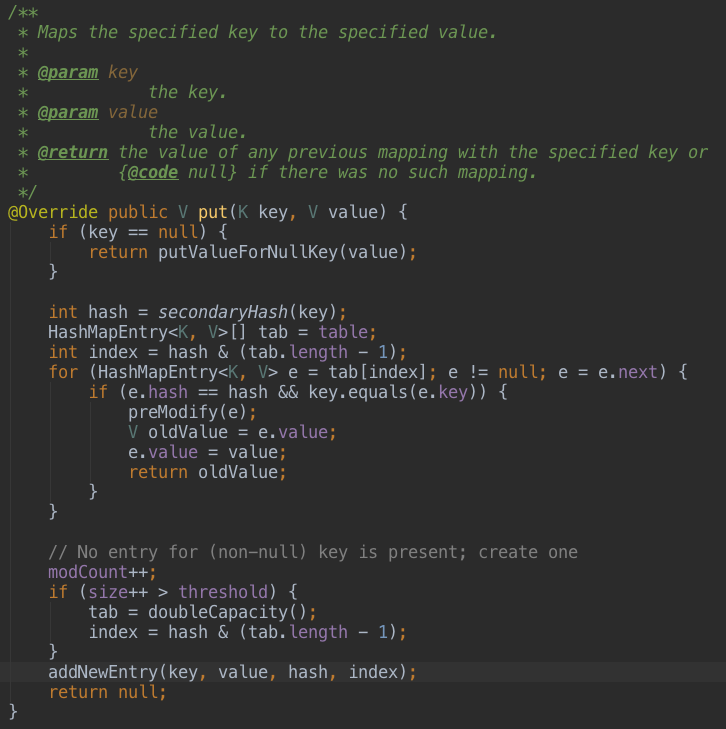
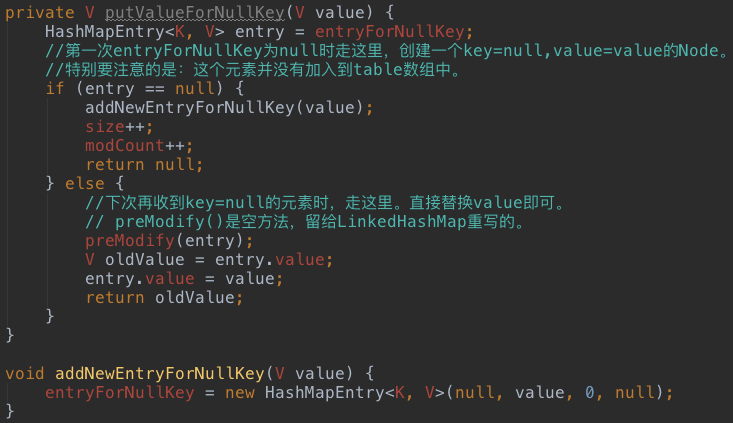
如上代码,如果加入的数据key=null,则执行如下逻辑:
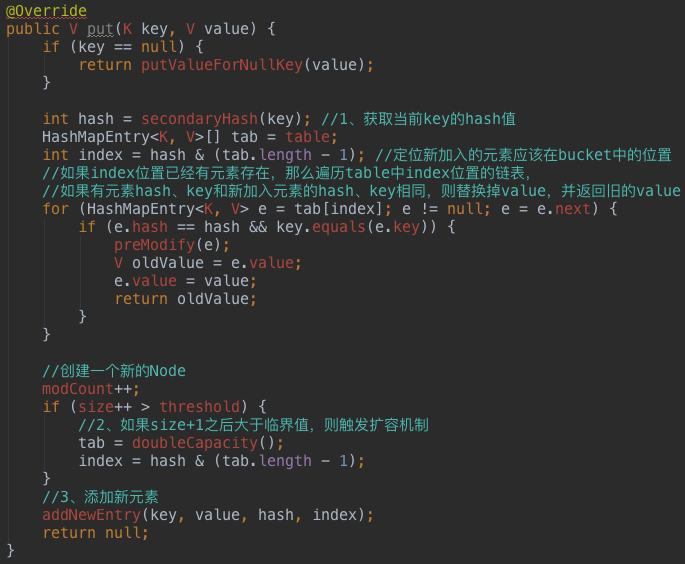
继续看doubleCapacity()方法,扩容就意味着要增加数据的长度,HashMap直接是double,新数组创建后,需要将旧数组中的元素拷贝到新数据中,这就需要再次Hash确定元素在新数组中的位置。这是一个成本较高的操作,所以如果有条件,最好提前设置好Map的capacity。
先看一段JDK早期的扩容代码:
void transfer(Entry[] newTable) {
Entry[] src = table;
int newCapacity = newTable.length;
//假设旧的HashMap存在元素:11->22,33,位置分别在0和1
for (int j = 0; j < src.length; j++) {
//=============第1次循环=============
Entry<K,V> e = src[j];//j=0,e=11
if (e != null) {
src[j] = null;//清理旧数组中j位置,置为null
do {
Entry<K,V> next = e.next;//e=11,next=22
int i = indexFor(e.hash, newCapacity);//假设i=6
e.next = newTable[i];//e.next=null
newTable[i] = e;//newTable[6]=11
e = next;//e=22
} while (e != null);
do {
Entry<K,V> next = e.next;//e=22,next=null
int i = indexFor(e.hash, newCapacity);//假设i=6,newTable[6]=11
e.next = newTable[i];//e.next=11
newTable[i] = e;//newTable[6]=22
e = next;//e=null
} while (e != null);
}
//=============第2次循环=============
Entry<K,V> e = src[j];//j=1,e=33
if (e != null) {
src[j] = null;
do {
Entry<K,V> next = e.next;//next=null
int i = indexFor(e.hash, newCapacity);//假设i=8,newTable[8]=null
e.next = newTable[i];//e.next=null
newTable[i] = e;//newTable[8]=33
e = next;//e=null
} while (e != null);
}
}
//结束后的存储是:在新数组位置6和8,分别存储元素22->11,33
}
这段代码会将旧数组及链表中的元素挨个取出来,使用新数组的capacity再次计算出index,然后放到新数组index位置。如果同一个bucket中有多个元素构成链表,则会从链表头部依次取出元素,同样会在新数组对应的bucket中形成一个新链表,只不过链表元素的顺序是反的,看代码即可知道。
这里之所以使用比较旧的扩容方法,是因为这个方法更加简洁,能够更方便的搞清楚其工作原理。但是JDK中已经对这个方法做了较大的优化,尤其是JDK8,提高了性能。
期初理解这段代码的时候有个误区,主要集中在这2行代码:
e.next = newTable[i];
newTable[i] = e;
总是转不过弯来,刚开始的理解是:e.next指向newTable[i],然后又把e自己放进newTable[i]位置,脑海中总把newTable[i]理解成一个固定的框,让自己的next指向这个框,然后再把自己放进这个框中,那岂不是框中自己的next指向自己所在的框?挺绕的,但是期初自己就陷入了这种很绕的境地。后来使用了如代码中注释那样的方式,才走出了这个迷魂阵。回过头来看,首先不存在一个实体的框,是我自己想象了一个框,把自己框在里面了。
其实e=src[j],只表示引用e指向src[j]目前指向的堆中元素X;
e.next=newTable[i],表示引用e中的next指向数组newTable[i]指向的元素,如果当前newTable[i]为null,没有指向任何元素,则说明e.next并没有指向任何堆中元素;
newTable[i]=e,表示数组newTable[i]位置指向e所指向的堆中元素,而不是把e放入newTable数组i位置;
对于引用关系,千万不要与实体位置对于起来,他们之间的关系仅仅是一条连线而已。一个引用a连着某个堆中对象X,对引用a的操作其实都是对X对象的操作;a如果指向了别的堆中对象,和X就没任何关系了。
2、get方法
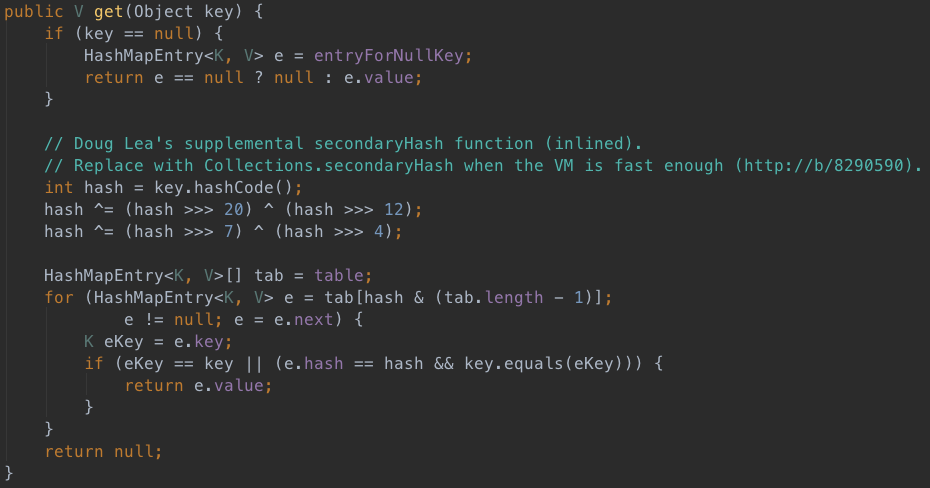
get方法就很简单了,不用多说了。
3、remove方法
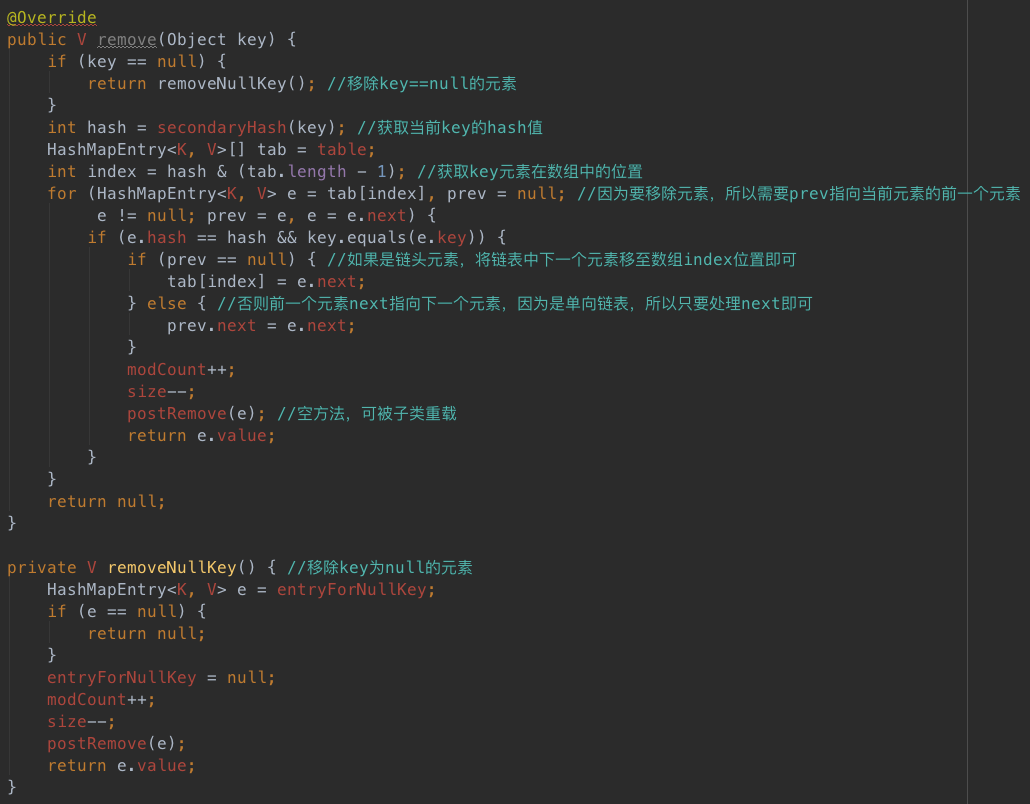
remove方法比较简单,看注释。
4、clear方法

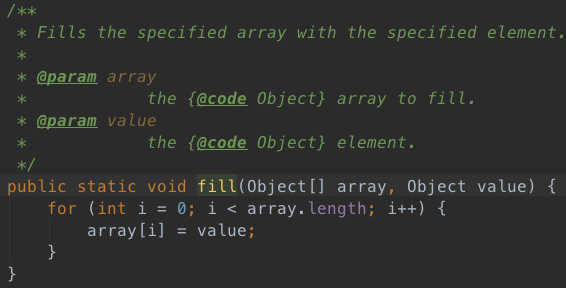
简单粗暴,直接将数组中的每一个位置填充为null。
5、HashMap中的Iterator体系
为什么要说HashMap的Itaerator体系呢?因为HashMap中提供了遍历Entry、Key、Value三套机制,所有对应的要有3套Iterator方法,但是HashMap中采用继承机制,设计了一套优雅合理的Iterator体系,我们来一探究竟。
private abstract class HashIterator {
int nextIndex;
HashMapEntry<K, V> nextEntry = entryForNullKey;
HashMapEntry<K, V> lastEntryReturned;
int expectedModCount = modCount;
HashIterator() {
if (nextEntry == null) {//如果有key为null的元素,则优先遍历
HashMapEntry<K, V>[] tab = table;
HashMapEntry<K, V> next = null;
while (next == null && nextIndex < tab.length) {//找到数组中第一个不为null的元素
next = tab[nextIndex++];
}
nextEntry = next;
}
}
public boolean hasNext() {
return nextEntry != null;
}
HashMapEntry<K, V> nextEntry() {
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
if (nextEntry == null)
throw new NoSuchElementException();
//假设数组中有2个元素11和33,11只有一个链表元素22,33没有链表元素,运行如下:
//===================第1次调用====================
HashMapEntry<K, V> entryToReturn = nextEntry;//nextEntry=11
HashMapEntry<K, V>[] tab = table;
HashMapEntry<K, V> next = entryToReturn.next;//next=22
while (next == null && nextIndex < tab.length) {
next = tab[nextIndex++];//不走这里
}
nextEntry = next;//nextEntry=22
return lastEntryReturned = entryToReturn;//lastEntryReturned=11
//===================第2次调用====================
HashMapEntry<K, V> entryToReturn = nextEntry;//nextEntry=22
HashMapEntry<K, V>[] tab = table;
HashMapEntry<K, V> next = entryToReturn.next;//next=null
while (next == null && nextIndex < tab.length) {
next = tab[nextIndex++];//走这里,找数组中下一个不为null的元素33
}
nextEntry = next;//nextEntry=33
return lastEntryReturned = entryToReturn;//lastEntryReturned=22
//===================第3次调用====================
HashMapEntry<K, V> entryToReturn = nextEntry;//nextEntry=33
HashMapEntry<K, V>[] tab = table;
HashMapEntry<K, V> next = entryToReturn.next;//next=null
while (next == null && nextIndex < tab.length) {//找不到其他非null元素
next = tab[nextIndex++];
}
nextEntry = next;//nextEntry=null,下一次调用hasNext方法时会判断退出
return lastEntryReturned = entryToReturn;//lastEntryReturned=33
}
public void remove() {
if (lastEntryReturned == null)
throw new IllegalStateException();
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
HashMap.this.remove(lastEntryReturned.key);//调用HashMap的remove方法
lastEntryReturned = null;
expectedModCount = modCount;
}
}
上面的代码做了一些注释,这是HashMap中Iterator体系中的最顶层的Itarator,可以发现这个Itarator并没有实现系统的Iterator接口,所以使用时不可强转。
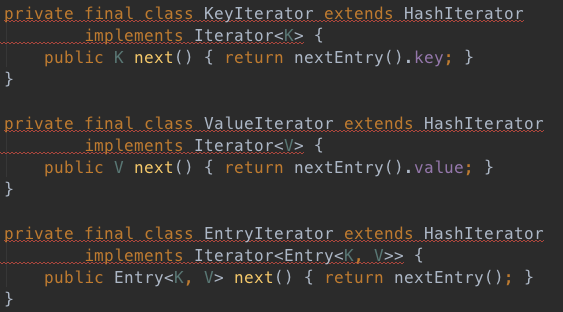
6、其他Iterator
顶层设计已经搞好了,其他3个Itarator只需要按需定制即可,如下:
7、keySet()、values()和entrySet()方法
keySet返回HashMap中所有key的Set集合,继承自AbstractSet,使用的正是KeyIterator,如下:

values()方法返回HashMap中所有value的Collection,继承自AbstractCollection,如下:
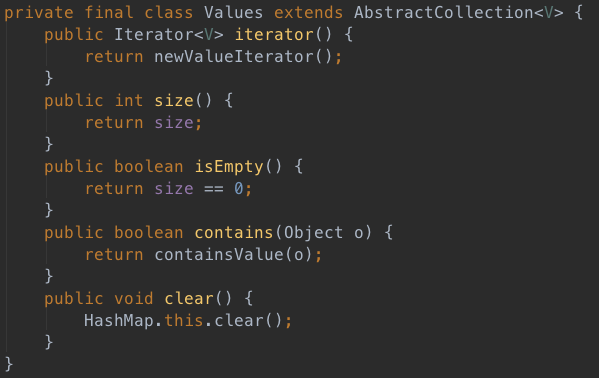
entrySet返回HashMap中所有元素的Set集合,如下:
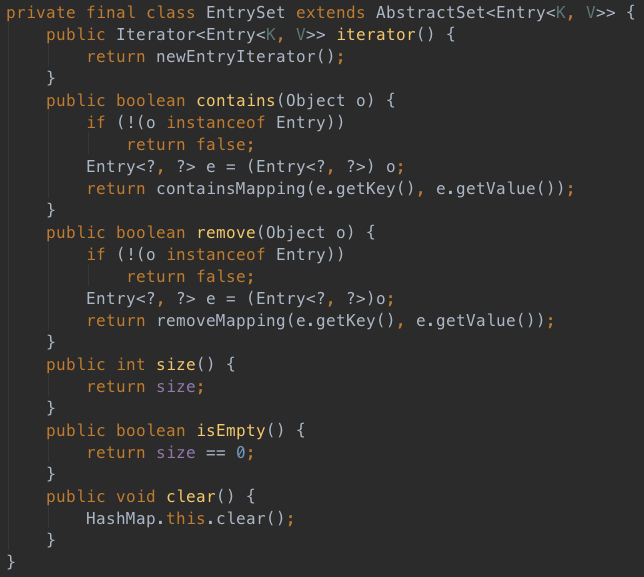
有个疑问,为什么keySet和entrySet都是Set集合,value却是Collection呢?虽然AbstractCollection提供了更丰富的操作,但好像不是理由。
【Java集合系列五】HashMap解析的更多相关文章
- Java 集合系列 09 HashMap详细介绍(源码解析)和使用示例
java 集合系列目录: Java 集合系列 01 总体框架 Java 集合系列 02 Collection架构 Java 集合系列 03 ArrayList详细介绍(源码解析)和使用示例 Java ...
- Java 集合系列 11 hashmap 和 hashtable 的区别
java 集合系列目录: Java 集合系列 01 总体框架 Java 集合系列 02 Collection架构 Java 集合系列 03 ArrayList详细介绍(源码解析)和使用示例 Java ...
- java集合系列之HashMap源码
java集合系列之HashMap源码 HashMap的源码可真不好消化!!! 首先简单介绍一下HashMap集合的特点.HashMap存放键值对,键值对封装在Node(代码如下,比较简单,不再介绍)节 ...
- Java集合系列之HashMap
概要 第1部分 HashMap介绍 HashMap简介 HashMap 是一个散列表,它存储的内容是键值对(key-value)映射.HashMap 继承于AbstractMap,实现了Map.Clo ...
- Java集合系列[3]----HashMap源码分析
前面我们已经分析了ArrayList和LinkedList这两个集合,我们知道ArrayList是基于数组实现的,LinkedList是基于链表实现的.它们各自有自己的优劣势,例如ArrayList在 ...
- 【java基础】java集合系列之HashMap
Hashmap是一种非常常用的.应用广泛的数据类型,最近研究到相关的内容,就正好复习一下.网上关于hashmap的文章很多,但到底是自己学习的总结,就发出来跟大家一起分享,一起讨论. 1.hashma ...
- Java 集合系列 10 Hashtable详细介绍(源码解析)和使用示例
java 集合系列目录: Java 集合系列 01 总体框架 Java 集合系列 02 Collection架构 Java 集合系列 03 ArrayList详细介绍(源码解析)和使用示例 Java ...
- Java 集合系列 06 Stack详细介绍(源码解析)和使用示例
java 集合系列目录: Java 集合系列 01 总体框架 Java 集合系列 02 Collection架构 Java 集合系列 03 ArrayList详细介绍(源码解析)和使用示例 Java ...
- Java 集合系列 05 Vector详细介绍(源码解析)和使用示例
java 集合系列目录: Java 集合系列 01 总体框架 Java 集合系列 02 Collection架构 Java 集合系列 03 ArrayList详细介绍(源码解析)和使用示例 Java ...
随机推荐
- .NET EF框架的安装、及三种开发模式
一.EF框架的安装: 要在VS(如Visual Studio 2012)中使用EF框架,就需要先进行安装. 我们需要给这个应用安装EntityFramework包,引入EF框架相关的内容,我们需要引入 ...
- 破解360doc个人图书馆网站的右键、复制方法
chrome浏览器如下做法: 右上角菜单按钮→设置→显示高级设置→隐私设置下的 内容设置按钮→javascript下的管理例外情况→添加 [*.]360doc.com 设置为禁止 →完成
- Ubuntu 14.04 安装 sysrepo v0.7.5
参考: Tentative gNMI support with sysrepo protobuf-c/protobuf-c Ubuntu 14.04 安装 sysrepo v0.7.5 安装依赖: s ...
- mongodb在ubuntu下无法打开的问题
通过查询大概知道了是非正常关闭,mongod.lock的事,ubuntu的mongod.lock在/var/lib/mongodb中,删除之后即可重新打开.
- 钉钉授权第三方WEB网站扫码登录
一.阅读开发文档 首先阅读钉钉官方的开发文档,扫码登录其实用的是官方文档描述的第二种方式,即将钉钉登录二维码内嵌到自己页面中,用户使用钉钉扫码登录第三方网站,网站可以拿到钉钉的用户信息. 二.准备工作 ...
- java.lang.ClassNotFoundException: javax.servlet.SessionCookieConfig
使用 MockMvc 模拟进行单元测试时出现以下的错误,网上看到的资料应该是说Spring4.0需要servlet3.0的支持? 在pom.xml更改servlet的版本依赖后即可
- 接口测试工具Jmeter
一.安装Jmeter 1.安装JDK ①下载jdk,到官网下载jdk,地址:http://jmeter.apache.org/download_jmeter.cgi ② 安装jdk(Oracle官网下 ...
- Go语言学习之12 etcd、contex、kafka消费实例、logagent
本节内容: 1. etcd介绍与使用 2. ElastcSearch介绍与使用 1. etcd介绍与使用 概念:高可用的分布式key-value存储,可以使用配置共享和服务发现 ...
- Django web框架-----url path name详解
说明:mytestsite是django框架下的项目,quicktool是mytestsite项目中的应用 quicktool/view.py文件修改视图函数index(),渲染一个home.html ...
- 转载aaa
前言 对于喜欢逛CSDN的人来说,看别人的博客确实能够对自己有不小的提高,有时候看到特别好的博客想转载下载,但是不能一个字一个字的敲了,这时候我们就想快速转载别人的博客,把别人的博客移到自己的空间 ...