HDFS及其各组件的机制
一、HDFS运行机制
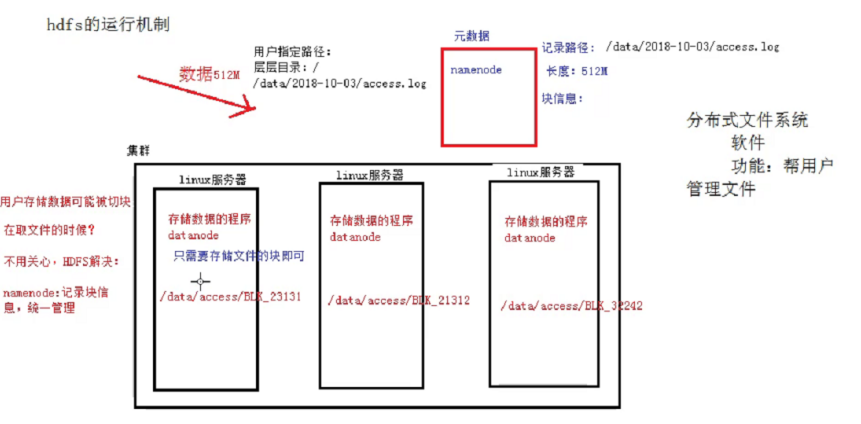
概述:用户的文件会被切块后存储在多台datanode节点中,并且每个文件在整个集群中存放多个副本,副本的数量可以通过修改配置自己设定。
HDFS:Hadoop Distributed file system,分布式文件系统。
HDFS的机制:
HDFS集群中,有两种节点,分别为Namenode,Datanode;
Namenode它的作用时记录元数据信息,记录块信息和对节点进行统一管理。比如用户要存储一个很大的文件,HDFS系统会对这个文件进行切分,然后存储在多台Namenode节点当中,那么每个切的大小,存储的路径信息,文件的副本数等元数据信息会存储在元数据当中,由Namenode进行管理和记录。
Datanode节点的作用是存储数据,Namenode将数据切块后的分配给多个Datanode节点,Datanode对数据块进行存储,Datanode它默认的块大小在hadoop1.x的版本中是64M,而hadoop2.x之后的版本默认块大小为128M。
HDFS还有一个副本机制,它会默认给存在Datanode当中的每块文件进行备份,默认的副本数量(republication)为3,这样保证了数据的安全性。
大致如图:
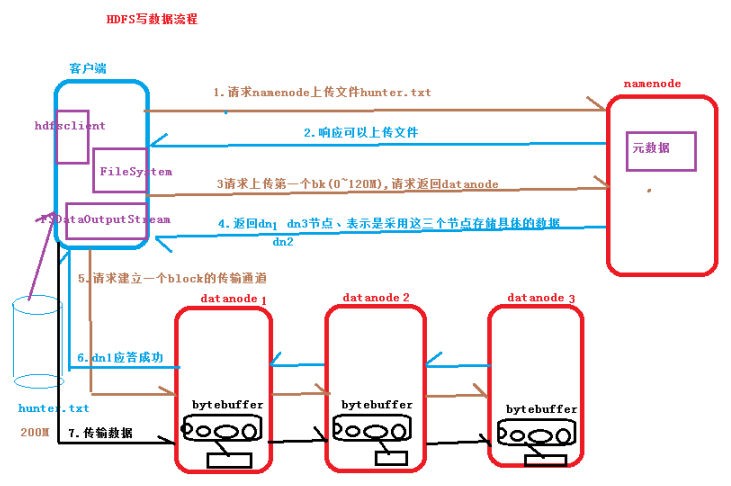
二、HDFS写数据流程
1.客户端向Namenode请求上传文件数据Hunter.txt(大小:200M);
2.Namenode响应可以上传文件;
3.客户端向Namenode请求上传第一个block(0~128M),请求返回Datanode节点;
4.Namenode返回三个Datanode节点(副本数默认为3),采用这三个节点存储数据;
5.客户端向Datanode请求建立一个block的传输通道;
6.Datanode应答通道建立成功;
7.客户端向Datanode传输数据,数据写入到HDFS文件系统当中。
三、hdfs读数据流程
1.客户端向Namenode请求下载文件hunter.txt(200M);
2.Namenode返回目标文件的元数据信息(block所在的datanode);
3.客户端向Datanode请求读取数据文件;
4.Datanode以FSDataInputStream流的形式向客户端传输数据;
5.客户端生成hunter.txt文件。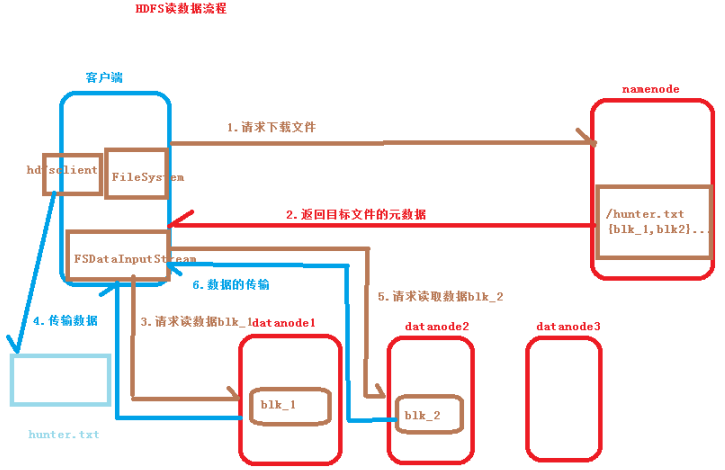
四、Namenode运行机制
首先去到主节点namenode的元数据信息dfs目录中,可以看到很多种文件,如下:
edits:存放HDFS系统所有的更新操作的日志文件
fsimage:HDFS元数据的永久性的检查点,其中包含了hdfs系统所有的目录和文件
seen_txid:最有一个edits文件的数字,即edits文件个数
VERSION:记录了很多的id,如下:
namespaceID:每个节点的id,每个节点都不同
ClusterID:一个集群统一的id,是唯一的,一个集群中所有节点的ClusterID都相同
CTime:Namenode存储系统的使用时间的时间戳
storageType:节点类型
blockpoolID:跨集群的全局唯一
layoutVersion:版本号
Namenode的运行机制:
1.首先启动集群,会启动Namenode和SecondaryNamenode,两个节点的内存会加载日志文件和镜像文件(edits、fsimage文件);
2.当客户端对HDFS集群进行增删改查等操作时,日志文件会更新滚动;
3.当eidts文件数量达到默认阈值,或checkpoint时间到达默认触发时间时;
(dfs.namenode.checkpoint.period :多久checkpoint一次、
dfs.namenode.checkpoint.check.period:多久检查一次操作的次数、
dfs.namenode.checkpoint.txns:多少次操作后chechpoint一次)
4.Namenode将edits文件拷贝到SecondarNamenode;
5.SecondarNamenode的内存会加载拷贝的edits文件并合并;
6.SecondarNamenode会生成新的镜像文件fsimage.checkpoint;
7.SecondarNamenode将新生产的镜像文件拷贝到Namenode;
8.Namenode将收到的镜像文件重命名为fsimage;
9.Namenode将新的fsimage镜像文件发送到SecondarNamenode
这样两个节点的元数据信息就相同了!!!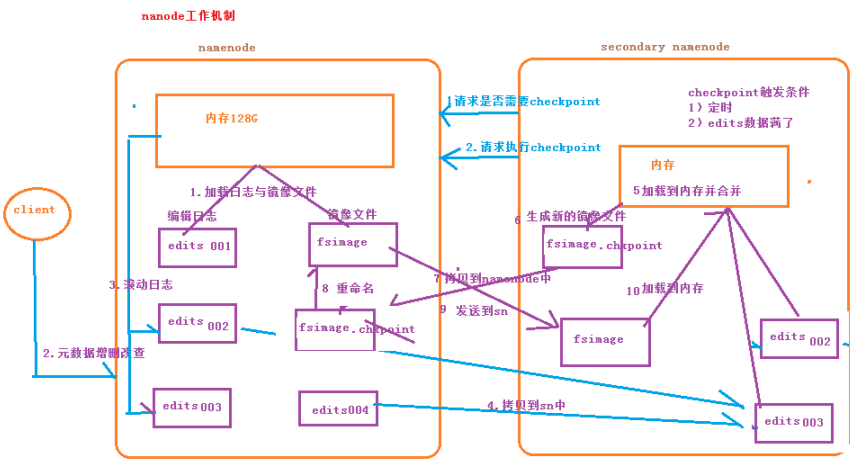
五、Datanode运行机制
1.HDFS集群启动后,Datanode现象Namenode发送注册信息;
2.Namenode返回注册成功;
3.每隔一段时间Datanode会上传所有的块信息到Namenode;
(块信息:数据、数据长度、校验和、时间戳等)
4.默认如果超过10分钟Namenode没有收到Datanode的信息信息,则认为节点不可用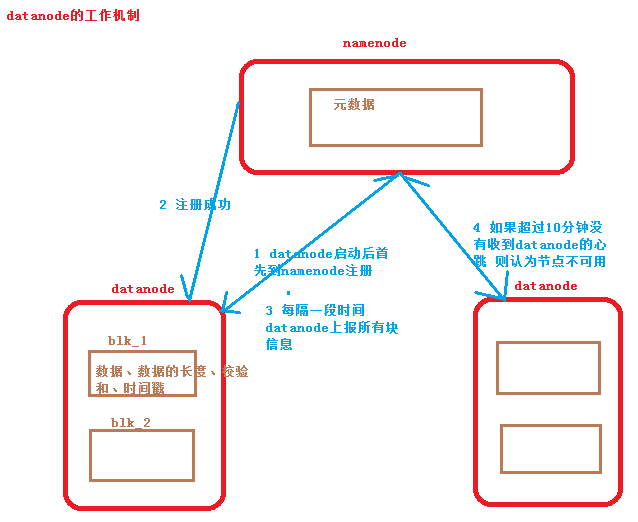
HDFS及其各组件的机制的更多相关文章
- HDFS 09 - HDFS NameNode 的高可用机制
目录 1 - 为什么要高可用 2 - NameNode 的高可用发展史 3 - HDFS 的高可用架构 3.1 Standby 和 Active 的命名空间保持一致 3.2 同一时刻只有一个 Acti ...
- Delphi的组件读写机制
Delphi的组件读写机制(一) 一.流式对象(Stream)和读写对象(Filer)的介绍在面向对象程序设计中,对象式数据管理占有很重要的地位.在Delphi中,对对象式数据管理的支持方式是其一大特 ...
- Hadoop HDFS概念学习系列之HDFS升级和回滚机制(十二)
不多说,直接上干货! HDFS升级和回滚机制 作为一个大型的分布式系统,Hadoop内部实现了一套升级机制,当在一个集群上升级Hadoop时,像其他的软件升级一样,可能会有新的bug或一些会影响现有应 ...
- React: React的组件状态机制
一.简介 在React中,有两个核心的默认属性,分别是state和props.state会记录组件的状态,React根据状态的变化,会对界面做相应的调整或渲染.props则是数据流向属性,React通 ...
- 【React 6/100】 React原理 | setState | JSX语法转换 | 组件更新机制
****关键字 | setState | JSX语法转换 | 组件更新机制 组件更新机制 setState() 的两个作用 修改state 更新组件 过程:父组件重新渲染时,也会重新渲染子组件,但只会 ...
- Vue总结第五天:vue-router (使用模块化(创建Vue组件)机制编程)、router-link 标签的属性、路由代码跳转、懒加载、路由嵌套(子路由)、路由传递数据、导航守卫)
Vue总结第五天:vue-router ✿ 路由(器)目录: □ vue中路由作用 □ vue-router基本使用 □ vue-router嵌套路由 □ vue-router参数传递 □ ...
- HDFS原理分析之HA机制:avatarnode原理
一.问题描述 由于namenode 是HDFS的大脑,而这个大脑又是单点,如果大脑出现故障,则整个分布式存储系统就瘫痪了.HA(High Available)机制就是用来解决这样一个问题的.碰到这么个 ...
- hdfs深入:03、hdfs的架构以及副本机制和block块存储
HDFS分布式文件系统设计目标 1. 硬件错误 由于集群很多时候由数量众多的廉价机组成,使得硬件错误成为常态 2. 数据流访问 所有应用以流的方式访问数 ...
- Hadoop(五)—— HDFS NameNode、DataNode工作机制
一.NN与2NN工作机制 NameNode(NN) 1.当HDFS启动时,会加载日志(edits)和镜像文件(fsImage)到内存中. 2-4.当元数据的增删改查请求进来时,NameNode会先将操 ...
随机推荐
- python学习日记(初识面向对象)
面向过程 VS 面向对象 面向过程 面向过程的程序设计把计算机程序视为一系列的命令集合,即一组函数的顺序执行.为了简化程序设计,面向过程把函数继续切分为子函数,即把大块函数通过切割成小块函数来降低系统 ...
- Codeforces 1082B Vova and Trophies(前缀+后缀)
题目链接:Vova and Trophies 题意:给定长度为n的字符串s,字符串中只有G和S,只允许最多一次操作:任意位置的两个字符互换.求连续G的最长长度. 题解:维护pre和pr,nxt和nx. ...
- Java【第三篇】基本语法之--选择结构
Java分支语句分类 分支语句根据一定的条件有选择地执行或跳过特定的语句,分为两类: if-else 语句 switch 语句 if-else语句语法格式 if(布尔表达式){ 语句或语句块; } i ...
- 解决每次从cmd进入sqlplus,都得重新设置pagesize、linesize的问题
https://blog.csdn.net/u012127798/article/details/34146143/ Oracle里的set零零碎碎的,这里整理归纳一下 SQL> set tim ...
- 让WinSCP和Putty一直保持连接
转: 让WinSCP和Putty一直保持连接 2015年08月14日 01:08:19 zcczbq 阅读数:13173 标签: puttywinscp 更多 个人分类: Operation 版权 ...
- [译]Ocelot - Load Balancer
原文 可以对下游的服务进行负载均衡. 提供了下面几种负载均衡: LeastConnection - tracks which services are dealing with requests an ...
- 运维工作笔记-------nginx的反向代理
1.nginx的反向代理意义 一般来说,我们在项目中,不会直接让项目服务器ip与外网做直接映射,这样一则是不安全,二是客户直接去访问项目服务器,对项目服务器带来的压力太大,从而导致项目运行速度变慢,程 ...
- Java8从对象列表中取出某个属性的列表
List<属性值类型> 属性List = 对象List.stream().map(对象::get方法()).collect(Collectors.toList()); 例如: List&l ...
- luogu P5300 [GXOI/GZOI2019]与或和
传送门 题目涉及按位与以及按位或运算,所以可以拆位考虑,枚举某个二进制位,然后某个位置如果那个数的第\(i\)位是\(0\)就放\(0\),否则放\(1\),这一位的贡献就是位运算后值为\(1\)的子 ...
- Studio 5000指令IN_OUT管脚实现西门子风格
习惯了西门子博途编辑风格的同学,乍一看到Studio 5000的编辑界面,一时不适应,尤其是功能块或指令的IN和OUT管脚在一起,不好分辨,本文简单几步搞定,实现像西门子IN和OUT分左右显示风格. ...