吴裕雄--天生自然 R语言开发学习:分类














#-----------------------------------------------------------------------------#
# R in Action (2nd ed): Chapter 17 #
# Classification #
# requires packaged rpart, party, randomForest, kernlab, rattle #
# install.packages(c("rpart", "party", "randomForest", "e1071", "rpart.plot") #
# install.packages(rattle, dependencies = c("Depends", "Suggests")) #
#-----------------------------------------------------------------------------# par(ask=TRUE) # Listing 17.1 - Prepare the breast cancer data
loc <- "http://archive.ics.uci.edu/ml/machine-learning-databases/"
ds <- "breast-cancer-wisconsin/breast-cancer-wisconsin.data"
url <- paste(loc, ds, sep="") breast <- read.table(url, sep=",", header=FALSE, na.strings="?")
names(breast) <- c("ID", "clumpThickness", "sizeUniformity",
"shapeUniformity", "maginalAdhesion",
"singleEpithelialCellSize", "bareNuclei",
"blandChromatin", "normalNucleoli", "mitosis", "class") df <- breast[-1]
df$class <- factor(df$class, levels=c(2,4),
labels=c("benign", "malignant")) set.seed(1234)
train <- sample(nrow(df), 0.7*nrow(df))
df.train <- df[train,]
df.validate <- df[-train,]
table(df.train$class)
table(df.validate$class) # Listing 17.2 - Logistic regression with glm()
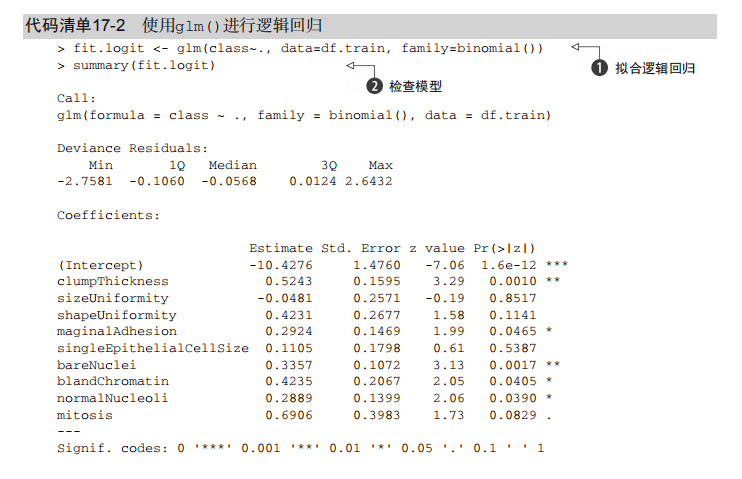
fit.logit <- glm(class~., data=df.train, family=binomial())
summary(fit.logit)
prob <- predict(fit.logit, df.validate, type="response")
logit.pred <- factor(prob > .5, levels=c(FALSE, TRUE),
labels=c("benign", "malignant"))
logit.perf <- table(df.validate$class, logit.pred,
dnn=c("Actual", "Predicted"))
logit.perf # Listing 17.3 - Creating a classical decision tree with rpart()
library(rpart)
set.seed(1234)
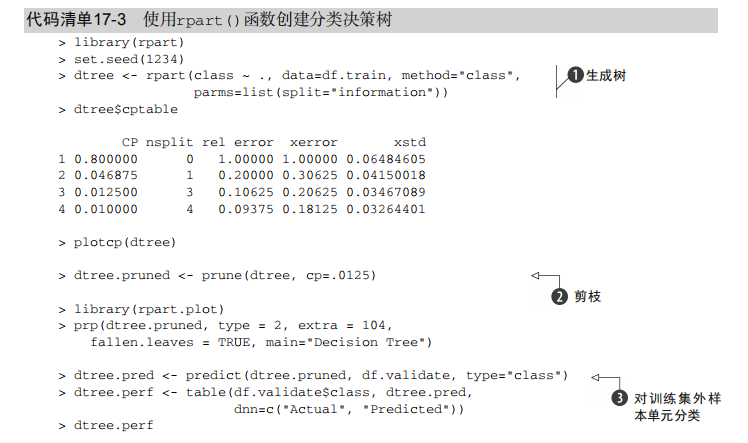
dtree <- rpart(class ~ ., data=df.train, method="class",
parms=list(split="information"))
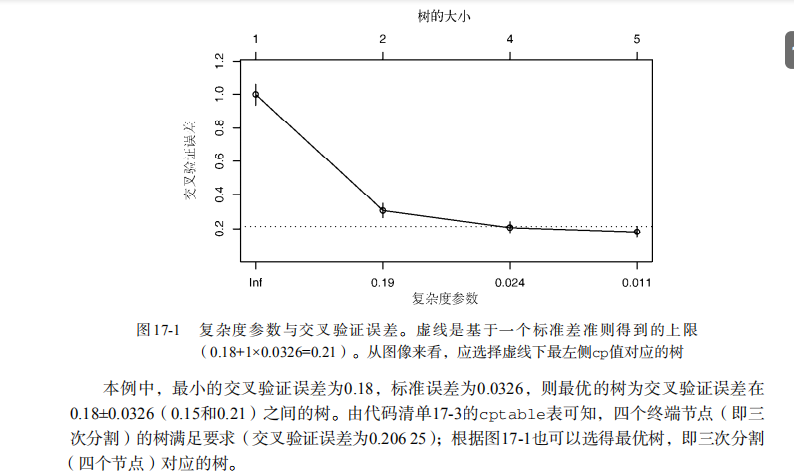
dtree$cptable
plotcp(dtree) dtree.pruned <- prune(dtree, cp=.0125) library(rpart.plot)
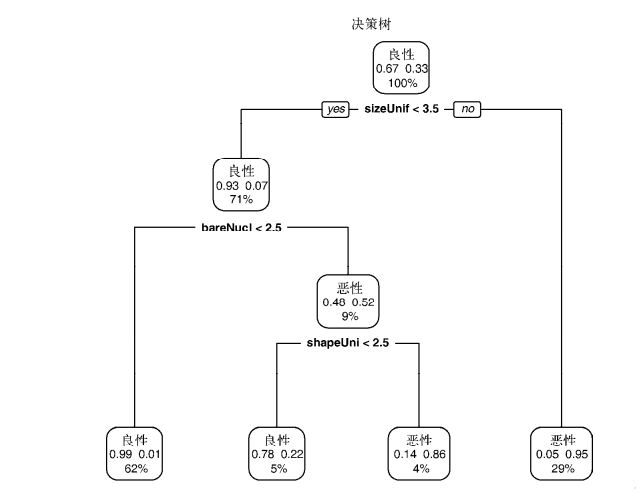
prp(dtree.pruned, type = 2, extra = 104,
fallen.leaves = TRUE, main="Decision Tree") dtree.pred <- predict(dtree.pruned, df.validate, type="class")
dtree.perf <- table(df.validate$class, dtree.pred,
dnn=c("Actual", "Predicted"))
dtree.perf # Listing 17.4 - Creating a conditional inference tree with ctree()
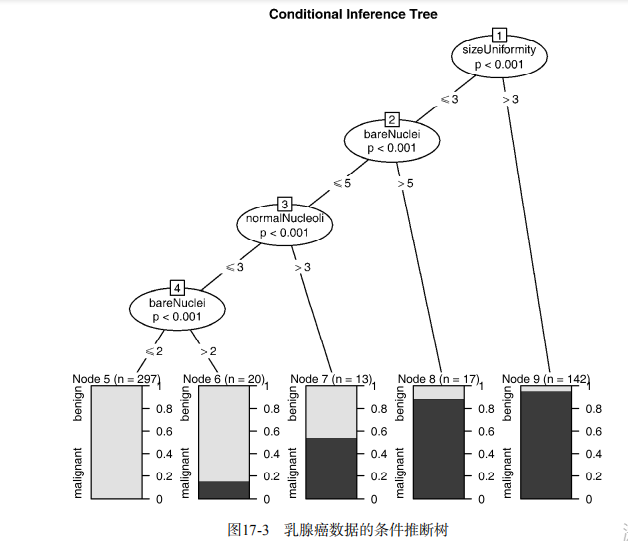
library(party)
fit.ctree <- ctree(class~., data=df.train)
plot(fit.ctree, main="Conditional Inference Tree") ctree.pred <- predict(fit.ctree, df.validate, type="response")
ctree.perf <- table(df.validate$class, ctree.pred,
dnn=c("Actual", "Predicted"))
ctree.perf # Listing 17.5 - Random forest
library(randomForest)
set.seed(1234)
fit.forest <- randomForest(class~., data=df.train,
na.action=na.roughfix,
importance=TRUE)
fit.forest
importance(fit.forest, type=2)
forest.pred <- predict(fit.forest, df.validate)
forest.perf <- table(df.validate$class, forest.pred,
dnn=c("Actual", "Predicted"))
forest.perf # Listing 17.6 - A support vector machine
library(e1071)
set.seed(1234)
fit.svm <- svm(class~., data=df.train)
fit.svm
svm.pred <- predict(fit.svm, na.omit(df.validate))
svm.perf <- table(na.omit(df.validate)$class,
svm.pred, dnn=c("Actual", "Predicted"))
svm.perf # Listing 17.7 Tuning an RBF support vector machine (this can take a while)
set.seed(1234)
tuned <- tune.svm(class~., data=df.train,
gamma=10^(-6:1),
cost=10^(-10:10))
tuned
fit.svm <- svm(class~., data=df.train, gamma=.01, cost=1)
svm.pred <- predict(fit.svm, na.omit(df.validate))
svm.perf <- table(na.omit(df.validate)$class,
svm.pred, dnn=c("Actual", "Predicted"))
svm.perf # Listing 17.8 Function for assessing binary classification accuracy
performance <- function(table, n=2){
if(!all(dim(table) == c(2,2)))
stop("Must be a 2 x 2 table")
tn = table[1,1]
fp = table[1,2]
fn = table[2,1]
tp = table[2,2]
sensitivity = tp/(tp+fn)
specificity = tn/(tn+fp)
ppp = tp/(tp+fp)
npp = tn/(tn+fn)
hitrate = (tp+tn)/(tp+tn+fp+fn)
result <- paste("Sensitivity = ", round(sensitivity, n) ,
"\nSpecificity = ", round(specificity, n),
"\nPositive Predictive Value = ", round(ppp, n),
"\nNegative Predictive Value = ", round(npp, n),
"\nAccuracy = ", round(hitrate, n), "\n", sep="")
cat(result)
} # Listing 17.9 - Performance of breast cancer data classifiers
performance(dtree.perf)
performance(ctree.perf)
performance(forest.perf)
performance(svm.perf) # Using Rattle Package for data mining loc <- "http://archive.ics.uci.edu/ml/machine-learning-databases/"
ds <- "pima-indians-diabetes/pima-indians-diabetes.data"
url <- paste(loc, ds, sep="")
diabetes <- read.table(url, sep=",", header=FALSE)
names(diabetes) <- c("npregant", "plasma", "bp", "triceps",
"insulin", "bmi", "pedigree", "age", "class")
diabetes$class <- factor(diabetes$class, levels=c(0,1),
labels=c("normal", "diabetic"))
library(rattle)
rattle()
吴裕雄--天生自然 R语言开发学习:分类的更多相关文章
- 吴裕雄--天生自然 R语言开发学习:R语言的安装与配置
下载R语言和开发工具RStudio安装包 先安装R
- 吴裕雄--天生自然 R语言开发学习:数据集和数据结构
数据集的概念 数据集通常是由数据构成的一个矩形数组,行表示观测,列表示变量.表2-1提供了一个假想的病例数据集. 不同的行业对于数据集的行和列叫法不同.统计学家称它们为观测(observation)和 ...
- 吴裕雄--天生自然 R语言开发学习:导入数据
2.3.6 导入 SPSS 数据 IBM SPSS数据集可以通过foreign包中的函数read.spss()导入到R中,也可以使用Hmisc 包中的spss.get()函数.函数spss.get() ...
- 吴裕雄--天生自然 R语言开发学习:使用键盘、带分隔符的文本文件输入数据
R可从键盘.文本文件.Microsoft Excel和Access.流行的统计软件.特殊格 式的文件.多种关系型数据库管理系统.专业数据库.网站和在线服务中导入数据. 使用键盘了.有两种常见的方式:用 ...
- 吴裕雄--天生自然 R语言开发学习:R语言的简单介绍和使用
假设我们正在研究生理发育问 题,并收集了10名婴儿在出生后一年内的月龄和体重数据(见表1-).我们感兴趣的是体重的分 布及体重和月龄的关系. 可以使用函数c()以向量的形式输入月龄和体重数据,此函 数 ...
- 吴裕雄--天生自然 R语言开发学习:基础知识
1.基础数据结构 1.1 向量 # 创建向量a a <- c(1,2,3) print(a) 1.2 矩阵 #创建矩阵 mymat <- matrix(c(1:10), nrow=2, n ...
- 吴裕雄--天生自然 R语言开发学习:图形初阶(续二)
# ----------------------------------------------------# # R in Action (2nd ed): Chapter 3 # # Gettin ...
- 吴裕雄--天生自然 R语言开发学习:图形初阶(续一)
# ----------------------------------------------------# # R in Action (2nd ed): Chapter 3 # # Gettin ...
- 吴裕雄--天生自然 R语言开发学习:图形初阶
# ----------------------------------------------------# # R in Action (2nd ed): Chapter 3 # # Gettin ...
- 吴裕雄--天生自然 R语言开发学习:基本图形(续二)
#---------------------------------------------------------------# # R in Action (2nd ed): Chapter 6 ...
随机推荐
- Properties in Algebra
附录-Properties in Algebra 部分证明转载自标注,仅作个人整理查阅用. 范数 (norm) \(^{[1]}\) 要更好的理解范数,就要从函数.几何与矩阵的角度去理解,我尽量讲的通 ...
- mysql 获取数据库和表结构信息
SELECT * FROM information_schema.`TABLES` where TABLE_SCHEMA = '数据库名';SELECT * FROM information_sche ...
- 学会用Python操作Mongodb
在linux下,用pip导包. pip install pymongo python操作基本步骤: 导包 建立连接,建立客户端. 获取数据库 获取集合 对数据操作 import pymongo #建立 ...
- MySQL笔记(二)——查询数据
数据库管理系统的一个最重要的功能就是数据查询,数据查询不应只是简单的查询数据库中存储的数据,还应该是根据需要对数据进行筛选,以及确定数据以什么样的格式显示.本篇笔记主要介绍单表查询,子查询,连接查询. ...
- requset请求处理与BeanUtils封装
HTTP: 概念:Hyper Text Transfer Protocol 超文本传输协议 传输协议:定义了,客户端和服务器端通信时,发送数据的格式 特点: 基于TCP/IP的高级协议 默认端口号:8 ...
- 机器学习总结(参考源码ml.hpp)
依据机器学习算法如何学习数据可分为3类: 有监督学习:从有标签的数据学习,得到模型参数,对测试数据正确分类: 无监督学习:没有标签,计算机自己寻找输入数据可能的模型: 强化学习(reinforceme ...
- Opencv笔记(十二)——形态学转换
学习目标: 学习不同的形态学操作,例如腐蚀,膨胀,开运算,闭运算等 我们要学习的函数有: cv2.erode(), cv2.dilate(), cv2.morphologyEx()等 原理简介: 形态 ...
- linux 上安装 tomcat
准备条件:安装java 一.tomcat 的安装 #新建文件夹 mkdir -p /data/tomcat #下载 tomcat8 服务器 wget http://mirrors.tuna.tsing ...
- 【Java杂货铺】JVM#Java高墙之内存模型
Java与C++之间有一堵由内存动态分配和垃圾回收技术所围成的"高墙",墙外的人想进去,墙外的人想出来.--<深入理解Java虚拟机> 前言 <深入理解Java虚 ...
- liquibase 注意事项
liquibase 一个changelog中有多个sql语句时,如果后边报错,前边的sql执行成功后是不会回滚的,所以最好分开写sql <changeSet author="lihao ...