linux安装spark-2.3.0集群
(安装spark集群的前提是服务器已经配置了jdk并且安装hadoop集群(主要是hdfs)并正常启动,hadoop集群安装可参考《hadoop集群搭建(hdfs)》)
1、配置scala环境
详细配置过程可参考《linux安装scala环境》,此处就不在详细描述
2、下载spark安装包
因为我之前安装的hadoop是3.0版本的,所以spark我使用的是spark-2.3.0版本
wget https://www.apache.org/dyn/closer.lua/spark/spark-2.3.0/spark-2.3.0-bin-hadoop2.7.tgz
3、解压安装包
tar zxvf spark-2.3.0-bin-hadoop2.7.tgz
4、修改配置文件
1、spark-env.sh
复制spark-env.sh.template文件成spark-env.sh(cp spark-env.sh.template spark-env.sh)
在spark-env.sh末尾增加以下配置:
export JAVA_HOME=/usr/java/jdk1.8.0_11
export SCALA_HOME=${SCALA_HOME}
export HADOOP_HOME=/home/hadoop/hadoop-3.0.0
export STANDALONE_SPARK_MASTER_HOST=node101
export SPARK_MASTER_IP=$STANDALONE_SPARK_MASTER_HOST
export SPARK_LAUNCH_WITH_SCALA=0
export SPARK_LIBRARY_PATH=${SPARK_HOME}/lib
export SCALA_LIBRARY_PATH=${SPARK_HOME}/lib
export SPARK_MASTER_WEBUI_PORT=18080
if [ -n "$HADOOP_HOME" ]; then
export SPARK_LIBRARY_PATH=$SPARK_LIBRARY_PATH:${HADOOP_HOME}/lib/native
fi
export HADOOP_CONF_DIR=/home/hadoop/hadoop-3.0.0/etc/hadoop
2、slaves
复制slaves.template文件成slaves(cp slaves.template slaves)
修改slave是文件的内容为:
#
# Licensed to the Apache Software Foundation (ASF) under one or more
# contributor license agreements. See the NOTICE file distributed with
# this work for additional information regarding copyright ownership.
# The ASF licenses this file to You under the Apache License, Version 2.0
# (the "License"); you may not use this file except in compliance with
# the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# # A Spark Worker will be started on each of the machines listed below.
node101
node102
node103
3、将整个spark解压出来的文件拷贝到另外的两台机器上
5、启动spark集群
cd /home/hadoop/spark/sbin
./start-all.sj
启动成功后会有如下的信息

6、检查各节点spark启动情况
分别在三台服务器上使用jps命令查看Master进程和worker进程是否存在,一下是分别是三台服务器的情况
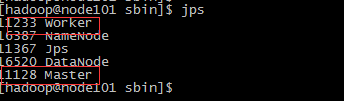
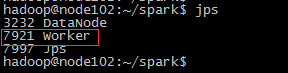
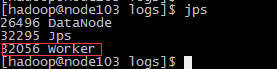
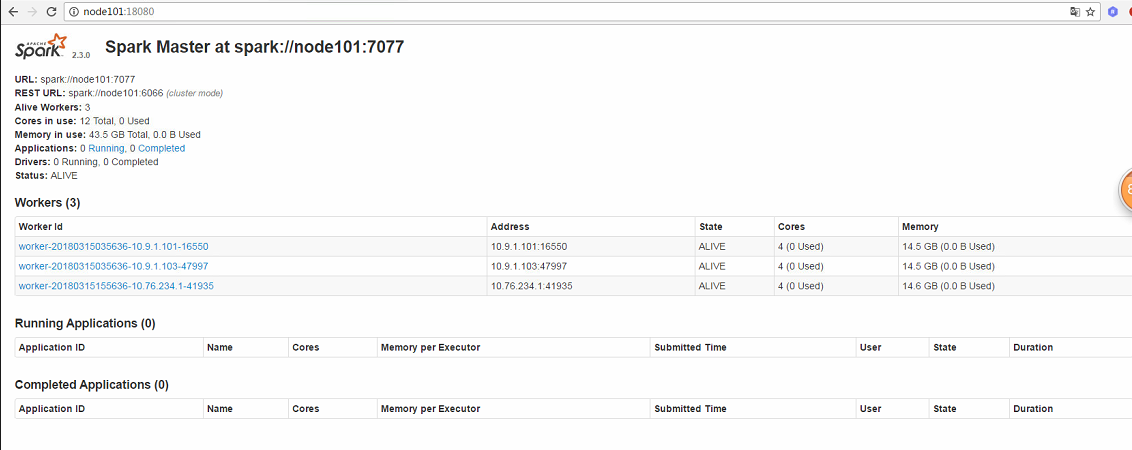
7、使用spark-web在浏览器上查看spark集群的运行情况(之前在配置文件里面配置的端口是18080)
linux安装spark-2.3.0集群的更多相关文章
- spark 2.1.0 集群安装
jdk安装 http://www.cnblogs.com/xiaojf/p/6568426.html scala2.11 安装 http://www.cnblogs.com/xiaojf/p/6568 ...
- CentOS 7.4 安装 K8S v1.11.0 集群所遇到的问题
0.引言 最近打算将现有项目的 Docker 部署到阿里云上面,但是之前是单机部署,现在阿里云上面有 3 台机器,所以想做一个 Docker 集群.之前考虑是用 Docker Swarm 来做这个事情 ...
- Linux安装ElasticSearch与MongoDB分布式集群环境下数据同步
ElasticSearch有一个叫做river的插件式模块,可以将外部数据源中的数据导入elasticsearch并在上面建立索引.River在集群上是单例模式的,它被自动分配到一个节点上,当这个节点 ...
- hadoop 2.6.0 分布式 + Spark 1.1.0 集群环境
配置jdk 执行 sudo apt-get install openjdk-7-jdk jdk被安装到了 /usr/lib/jvm/ 目录 配置hosts 使用 vim 打开 /etc/hosts, ...
- Linux安装MYSQL并部署主从复制集群
主节点部署 安装数据库 Ubuntu apt-get install mysql-server -y systemctl start mysql systemctl enabled mysql Cen ...
- kubeadm安装kubernetes V1.11.1 集群
之前测试了离线环境下使用二进制方法安装配置Kubernetes集群的方法,安装的过程中听说 kubeadm 安装配置集群更加方便,因此试着折腾了一下.安装过程中,也有一些坑,相对来说操作上要比二进制方 ...
- Linux基于Hadoop2.8.0集群安装配置Hive2.1.1及基础操作
前言 安装Apache Hive前提是要先安装hadoop集群,并且hive只需要在hadoop的namenode节点集群里安装即可,安装前需保证Hadoop已启(动文中用到了hadoop的hdfs命 ...
- hadoop2.20.0集群安装教程
一.安装的需要软件及集群描述 1.软件: Vmware9.0:虚拟机 Hadoop2.2.0:Apache官网原版稳定版本 JDK1.7.0_07:Oracle官网版本 Ubuntu12.04LTS: ...
- hadoop 2.2.0集群安装详细步骤(简单配置,无HA)
安装环境操作系统:CentOS 6.5 i586(32位)java环境:JDK 1.7.0.51hadoop版本:社区版本2.2.0,hadoop-2.2.0.tar.gz 安装准备设置集群的host ...
随机推荐
- 解题报告-908. Smallest Range I
题目 : Given an array A of integers, for each integer A[i] we may choose any x with -K <= x <= K ...
- Jenkins构建时间Poll Scm的设置(常用设置)
每15分钟构建一次:H/15 * * * * 或*/5 * * * * 每天8点构建一次:0 8 * * * 每天8点~17点,两小时构建一次:0 8-17/2 * * * 周一到周五,8点~17 ...
- NormalMap原理详细解析
NormalMap的实现标志着对渲染流水线的各个环节以及矩阵变化有了正确和深入的认识.这里记录一下学习过程,以及关于NormalMap的诸多细节. 刚开始想要实现NormalMap程序的时候,查阅的是 ...
- git pull --rebase的使用
原文:http://www.cnblogs.com/kevingrace/p/5896706.html 使用下面的关系区别这两个操作:git pull = git fetch + git mergeg ...
- Mysql 关于not exists一例
场景: 业务上需要做一个查询,因为是Web及时响应,所以对响应时间有要求,原业务场景是需要从无库存订单中剔除绑定闲置库存,因单条sql查询实现复杂,故考虑用差集方式: select a.col1, a ...
- mongo find
MongoVUE 对应成语句,结构如下: db.logs.find({ "message" : /消息/ }, { "message" : 1 }).limit ...
- MarkDown语法练习笔记
MarkDown使用规则 标题Markdown 支持两种标题的语法,类 Setext 和类 atx 形式 Setext 形式:用底线的形式 Selext形式采用: 1.最高阶标题(=)2.第二阶标题( ...
- Google Tango Java SDK开发:Configure and Connect 配置和连接
Configure and Connect 配置和连接 Note: This section assumes you are familiar with the Android Activity Li ...
- I-Keyboard
SPOJ Problem Set (classical) 14. I-Keyboard Problem code: IKEYB Most of you have probably tried to t ...
- Grails入门系列(一)
Grails入门系列(一) JAVAweb开发技术相对于php,python,note.js等新式技术更为复杂,向来以繁杂的配置著称,但是Java任然被广泛的应用于大型企业级的项目,主要是因为技术成熟 ...