Elasticsearch介绍和安装
Elasticsearch介绍和安装
软件包:
链接:https://pan.baidu.com/s/1O_C0JQGfF8sC_OtcCCLNoQ
提取码:3iai
1.1.简介
1.1.1.Elastic
Elastic官网:https://www.elastic.co/cn/

Elastic有一条完整的产品线及解决方案:Elasticsearch、Kibana、Logstash等,前面说的三个就是大家常说的ELK技术栈。
1.1.2.Elasticsearch
Elasticsearch官网:https://www.elastic.co/cn/products/elasticsearch

如上所述,Elasticsearch具备以下特点:
- 分布式,无需人工搭建集群(solr就需要人为配置,使用Zookeeper作为注册中心)
- Restful风格,一切API都遵循Rest原则,容易上手
- 近实时搜索,数据更新在Elasticsearch中几乎是完全同步的。
1.1.3.版本
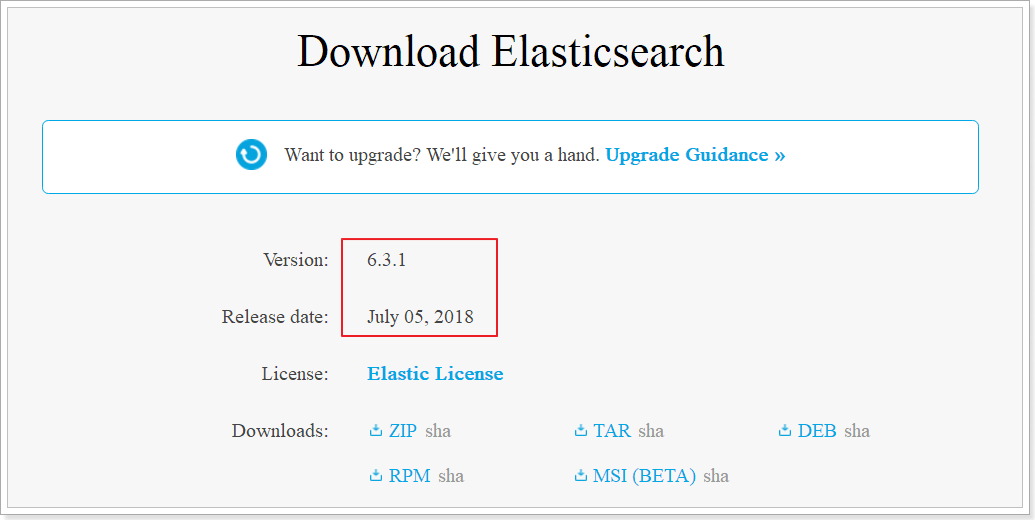
目前Elasticsearch最新的版本是6.3.1,我们就使用6.3.0
需要虚拟机JDK1.8及以上
1.2.安装和配置
为了模拟真实场景,我们将在linux下安装Elasticsearch。
1.2.1.新建一个用户leyou
出于安全考虑,elasticsearch默认不允许以root账号运行。
创建用户:
useradd leyou
设置密码:
passwd leyou
切换用户:
su - leyou
1.2.2.上传安装包,并解压
我们将安装包上传到:/home/leyou目录
解压缩:
tar -zxvf elasticsearch-6.2.4.tar.gz
删除压缩包:
rm -rf elasticsearch-6.2.4.tar.gz
我们把目录重命名:
mv elasticsearch-6.2.4/ elasticsearch
进入,查看目录结构:
1.2.3.修改配置
我们进入config目录:cd config
需要修改的配置文件有两个:
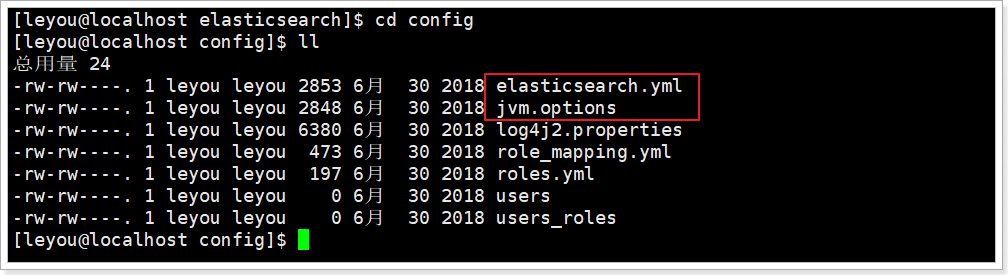
- jvm.options
Elasticsearch基于Lucene的,而Lucene底层是java实现,因此我们需要配置jvm参数。
编辑jvm.options:
vim jvm.options
默认配置如下:
-Xms1g
-Xmx1g
内存占用太多了,我们调小一些:
-Xms512m
-Xmx512m
- elasticsearch.yml
vim elasticsearch.yml
- 修改数据和日志目录:
path.data: /home/leyou/elasticsearch/data # 数据目录位置
path.logs: /home/leyou/elasticsearch/logs # 日志目录位置
我们把data和logs目录修改指向了elasticsearch的安装目录。但是这两个目录并不存在,因此我们需要创建出来。
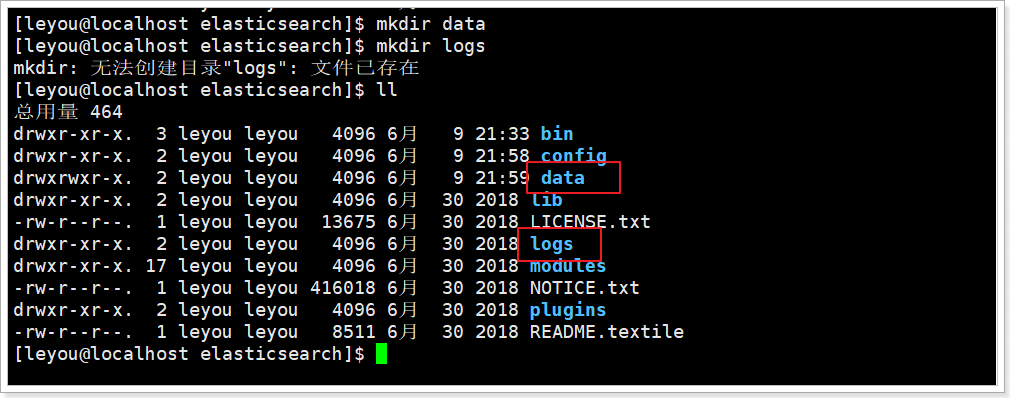
进入elasticsearch的根目录,然后创建:
mkdir data
mkdir logs
- 修改绑定的ip:
network.host: 0.0.0.0 # 绑定到0.0.0.0,允许任何ip来访问
默认只允许本机访问,修改为0.0.0.0后则可以远程访问
目前我们是做的单机安装,如果要做集群,只需要在这个配置文件中添加其它节点信息即可。
elasticsearch.yml的其它可配置信息:
| 属性名 | 说明 |
|---|---|
| cluster.name | 配置elasticsearch的集群名称,默认是elasticsearch。建议修改成一个有意义的名称。 |
| node.name | 节点名,es会默认随机指定一个名字,建议指定一个有意义的名称,方便管理 |
| path.conf | 设置配置文件的存储路径,tar或zip包安装默认在es根目录下的config文件夹,rpm安装默认在/etc/ elasticsearch |
| path.data | 设置索引数据的存储路径,默认是es根目录下的data文件夹,可以设置多个存储路径,用逗号隔开 |
| path.logs | 设置日志文件的存储路径,默认是es根目录下的logs文件夹 |
| path.plugins | 设置插件的存放路径,默认是es根目录下的plugins文件夹 |
| bootstrap.memory_lock | 设置为true可以锁住ES使用的内存,避免内存进行swap |
| network.host | 设置bind_host和publish_host,设置为0.0.0.0允许外网访问 |
| http.port | 设置对外服务的http端口,默认为9200。 |
| transport.tcp.port | 集群结点之间通信端口 |
| discovery.zen.ping.timeout | 设置ES自动发现节点连接超时的时间,默认为3秒,如果网络延迟高可设置大些 |
| discovery.zen.minimum_master_nodes | 主结点数量的最少值 ,此值的公式为:(master_eligible_nodes / 2) + 1 ,比如:有3个符合要求的主结点,那么这里要设置为2 |
修改文件权限:
leyou 要own(拥有) elasticsearch 这个文件夹权限 -R 是递归的赋予权限
chown leyou:leyou elasticsearch/ -R
1.3.运行
进入elasticsearch/bin目录,可以看到下面的执行文件:

然后输入命令:
./elasticsearch
发现报错了,启动失败:
1.3.1.错误1:内核过低

我们使用的是centos6,其linux内核版本为2.6。而Elasticsearch的插件要求至少3.5以上版本。不过没关系,我们禁用这个插件即可。
修改elasticsearch.yml文件,在最下面添加如下配置:
bootstrap.system_call_filter: false
然后重启
1.3.2.错误2:文件权限不足
再次启动,又出错了:
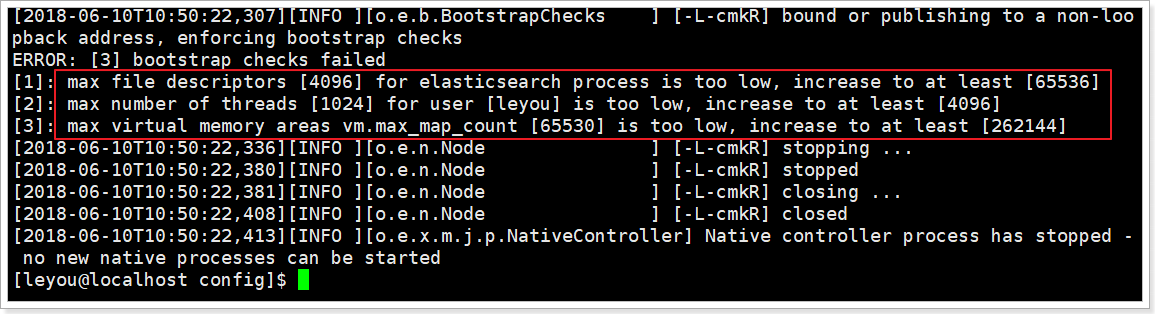
[1]: max file descriptors [4096] for elasticsearch process likely too low, increase to at least [65536]
我们用的是leyou用户,而不是root,所以文件权限不足。
首先用root用户登录。
然后修改配置文件:
vim /etc/security/limits.conf
添加下面的内容:
* soft nofile 65536
* hard nofile 131072
* soft nproc 4096
* hard nproc 4096
1.3.3.错误3:线程数不够
刚才报错中,还有一行:
[1]: max number of threads [1024] for user [leyou] is too low, increase to at least [4096]
这是线程数不够。
继续修改配置:
vim /etc/security/limits.d/90-nproc.conf
修改下面的内容:
* soft nproc 1024
改为:
* soft nproc 4096
1.3.4.错误4:进程虚拟内存
[3]: max virtual memory areas vm.max_map_count [65530] likely too low, increase to at least [262144]
vm.max_map_count:限制一个进程可以拥有的VMA(虚拟内存区域)的数量,继续修改配置文件, :
vim /etc/sysctl.conf
添加下面内容:
vm.max_map_count=655360
然后执行命令:
sysctl -p
1.3.5.重启终端窗口
所有错误修改完毕,一定要重启你的 Xshell终端,否则配置无效。
1.3.6.启动
再次启动,终于成功了!
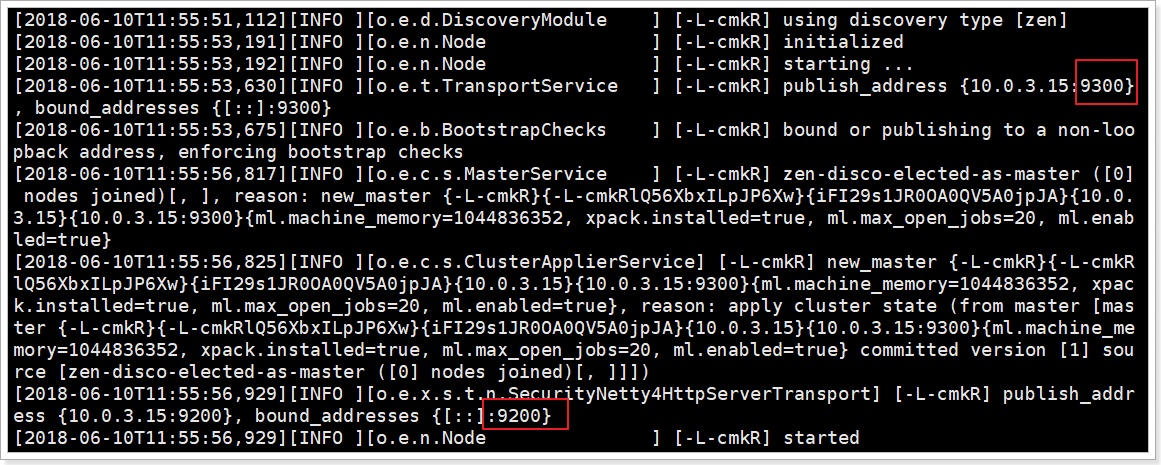
可以看到绑定了两个端口:
- 9300:集群节点间通讯接口
- 9200:客户端访问接口
我们在浏览器中访问:http://192.168.56.101:9200

1.4.安装kibana
1.4.1.什么是Kibana?
Kibana是一个基于Node.js的Elasticsearch索引库数据统计工具,可以利用Elasticsearch的聚合功能,生成各种图表,如柱形图,线状图,饼图等。
而且还提供了操作Elasticsearch索引数据的控制台,并且提供了一定的API提示,非常有利于我们学习Elasticsearch的语法。
1.4.2.安装
因为Kibana依赖于node,我们的虚拟机没有安装node,而window中安装过。所以我们选择在window下使用kibana。
最新版本与elasticsearch保持一致,也是6.3.0
解压到特定目录即可
1.4.3.配置运行
配置
进入安装目录下的config目录,修改kibana.yml文件:
修改elasticsearch服务器的地址:
elasticsearch.url: "http://192.168.56.101:9200"
运行
进入安装目录下的bin目录:
双击运行:
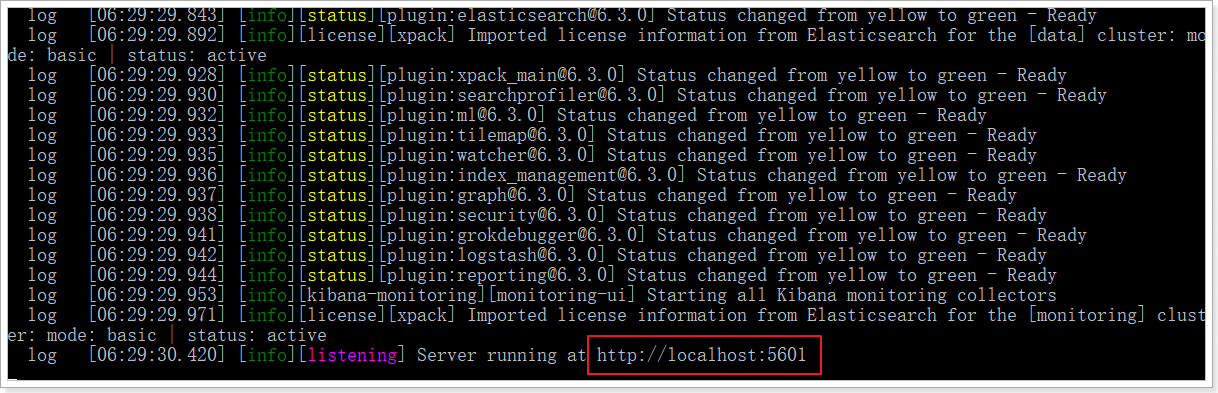
发现kibana的监听端口是5601
1.4.4.控制台
选择左侧的DevTools菜单,即可进入控制台页面:
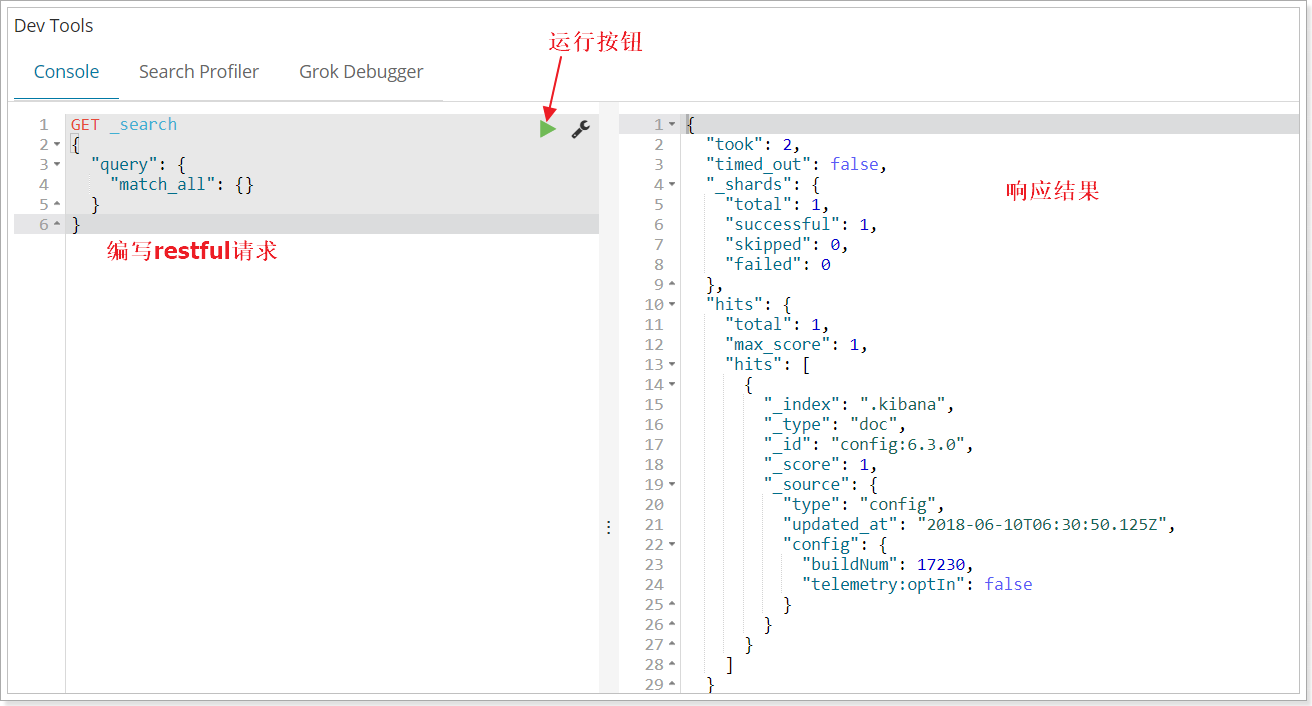
在页面右侧,我们就可以输入请求,访问Elasticsearch了。
1.5.安装ik分词器
Lucene的IK分词器早在2012年已经没有维护了,现在我们要使用的是在其基础上维护升级的版本,并且开发为ElasticSearch的集成插件了,与Elasticsearch一起维护升级,版本也保持一致,最新版本:6.3.0
1.5.1.安装
上传资料中的zip包,解压到Elasticsearch目录的plugins目录中:
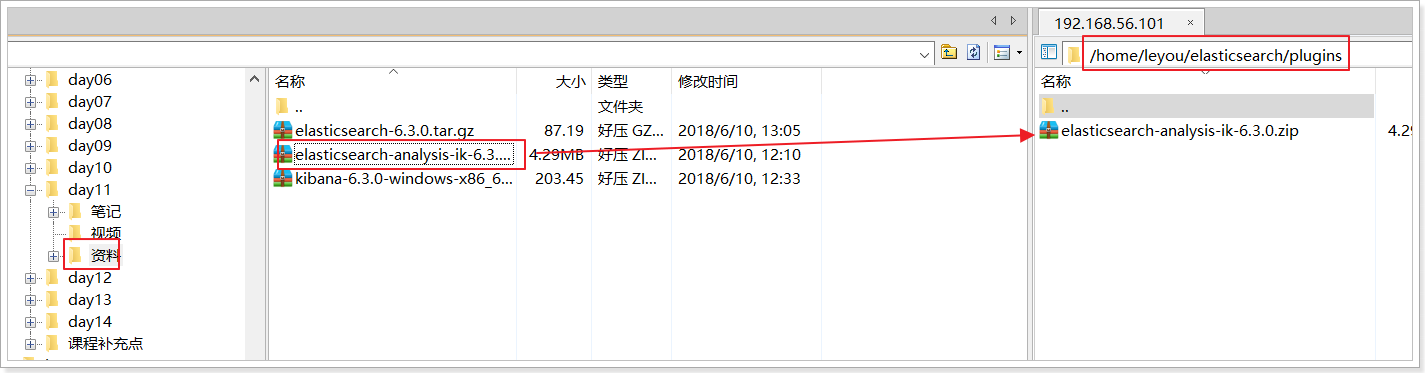
使用unzip命令解压:
unzip elasticsearch-analysis-ik-6.3.0.zip -d ik-analyzer
然后重启elasticsearch:

1.5.2.测试
大家先不管语法,我们先测试一波。
在kibana控制台输入下面的请求:
POST _analyze
{
"analyzer": "ik_max_word",
"text": "我是中国人"
}
运行得到结果:
{
"tokens": [
{
"token": "我",
"start_offset": 0,
"end_offset": 1,
"type": "CN_CHAR",
"position": 0
},
{
"token": "是",
"start_offset": 1,
"end_offset": 2,
"type": "CN_CHAR",
"position": 1
},
{
"token": "中国人",
"start_offset": 2,
"end_offset": 5,
"type": "CN_WORD",
"position": 2
},
{
"token": "中国",
"start_offset": 2,
"end_offset": 4,
"type": "CN_WORD",
"position": 3
},
{
"token": "国人",
"start_offset": 3,
"end_offset": 5,
"type": "CN_WORD",
"position": 4
}
]
}
Elasticsearch介绍和安装的更多相关文章
- Elasticsearch介绍和安装与使用
转载:https://blog.csdn.net/weixin_42633131/article/details/82902812 1.Elasticsearch介绍和安装 1.1.简介1.1.1.E ...
- elasticsearch介绍,安装,安装错误解决及相应插件安装
一.elasticsearch介绍 1.简介(使用的是nosql,更新比mongodb慢): ElasticSearch是一个基于Lucene的搜索服务器.它提供了一个分布式多用户能力的全文搜索引擎, ...
- Elasticsearch介绍及安装部署
本节内容: Elasticsearch介绍 Elasticsearch集群安装部署 Elasticsearch优化 安装插件:中文分词器ik 一.Elasticsearch介绍 Elasticsear ...
- ElasticSearch介绍与安装
什么是ES? 1基于Apache Lucene构建的开源搜索引擎 2采用java编写,提供简单易用的RESTFul API 3轻松的横向扩展,可支持PB级的结构化或非结构化数据处理 ES的应用场景? ...
- 第三百五十九节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)介绍以及安装
第三百五十九节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)介绍以及安装 elasticsearch(搜索引擎)介绍 ElasticSearch是一个基于 ...
- ElasticSearch入门-基本概念介绍以及安装
Elasticsearch基本概念 Elasticsearch是基于Lucene的全文检索库,本质也是存储数据,很多概念与传统关系型数据库类似. 传统关系型数据库与Elasticsearch进行概念对 ...
- 批量搞机(二):分布式ELK平台、Elasticsearch介绍、Elasticsearch集群安装、ES 插件的安装与使用
一.分布式ELK平台 ELK的介绍: ELK 是什么? Sina.饿了么.携程.华为.美团.freewheel.畅捷通 .新浪微博.大讲台.魅族.IBM...... 这些公司都在使用 ELK!ELK! ...
- Elasticsearch(es)介绍与安装
### RabbitMQ从入门到集群架构: https://zhuanlan.zhihu.com/p/375157411 可靠性高 ### Kafka从入门到精通: https://zhuanlan. ...
- 1.ElasticSearch介绍及基本概念
一.ElasticSearch介绍 一个采用RESTful API标准的高扩展性的和高可用性的实时性分析的全文搜索工具 基于Lucene[开源的搜索引擎框架]构建 ElasticSearch是一个面向 ...
随机推荐
- SqlSugar 笔记
分组: 日期分组一: var result = await temp .GroupBy("date_format(Day,'%Y-%m')") .Select(s => ne ...
- jq获取浏览器可视窗口的高度
<script> var window_height = $(window).height(); </script>
- java 删除字符串左边空格和右边空格 trimLeft trimRight
/** * 去右空格 * @param str * @return */ public String trimRight(String str) { if (str == null || str.eq ...
- How do I cover the “no results” text in UISearchDisplayController's searchResultTableView?
How do I cover the "no results" text in UISearchDisplayController's searchResultTableView? ...
- OpenStack项目及组件功能简单介绍
核心项目3个 1.控制台 服务名:Dashboard 项目名:Horizon 功能:web方式管理云平台,建云主机,分配网络,配安全组,加云盘 2.计算 服务名:计算 项目名:Nova 功能:负责响应 ...
- SuperSocket从服务器端主动发起连接
你可以从服务器端主动连接客户端, 连接建立之后的网络通信处理将和客户端主动建立连接的处理方式一样. var activeConnector = appServer as IActiveConnecto ...
- 数据采集之js埋点
一.后台nginx环境搭建 web点数据采集后台配置nginx:https://blog.csdn.net/weixin_37490221/article/details/80894827 下载数据源 ...
- js切割字符串
var time_str= '2019-9-10 13:18:20'; var t = time_str.substr(2,8); console.log(t); 输出 19-9-10
- 提高github下载速度的方法【100%有效】可达到2MB/s
因为大家都知道的原因,在国内从github上面下载代码的速度峰值通常都是20kB/s.这种速度对于那些小项目还好,而对于大一些的并且带有很多子模块的项目来讲就跟耽误时间.而常见的的方法无非就是修改HO ...
- [转]敏捷开发需求管理(产品backlog)
传统的瀑布工作模式使用详细的需求说明书来表达需求,需求人员负责做需求调研,根据调研情况编制详细的需求说明书,进行需求评审,评审之后签字确认交给研发团队设计开发.在这样的环境下,需求文档是信息传递的主体 ...