solr常用操作及集成分词器或cdh集群部署说明
首先,如果是从http://lucene.apache.org/solr/下载的solr,基本都是自带集成的jetty服务,不需要单独搭建tomcat环境,但是要注意jdk版本,直接解压通过cmd命令调用bin目录下的solr.cmd -start 来启动
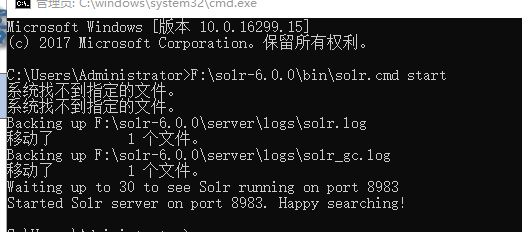
就可以直接通过浏览器访问,默认端口是8983,地址:http://localhost:8983/solr
如果需要集成中文分词器
直接在实例目录下新建lib文件夹,将中文分词器jar复制进去,再修改scahm.xml文件的filetype节点类型就可以。
如:我新建的solr实例名叫new_core,那么就在solr-6.0.0\server\solr\new_core的路径下新建lib文件夹,并把中文分词器的jar复制进去
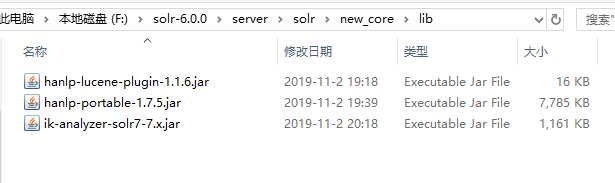
备注:分词器自己根据业务需要选择,常见的ik,hanlp,jcseg等
然后修改managed-schema配置文件的filetype,当然也可以新增(其实可以理解为新增了一种solr字段类型,至于要在那个字段引用,在filed字段节点上配置type为当前类型即可)
<fieldType name="text_ik" class="solr.TextField">
<analyzer type="index" class="org.wltea.analyzer.lucene.IKAnalyzer" useSmart="false"/>
<analyzer type="query" class="org.wltea.analyzer.lucene.IKAnalyzer" useSmart="false"/>
</fieldType>
<fieldType name="text_hp" class="solr.TextField">
<analyzer type="index">
<tokenizer class="com.hankcs.lucene.HanLPTokenizerFactory" enableIndexMode="true"/>
</analyzer>
<analyzer type="query">
<tokenizer class="com.hankcs.lucene.HanLPTokenizerFactory" enableIndexMode="false"/>
</analyzer>
</fieldType>
注:class就是分词器jar解压的src下的路径。
更改完成后,可以重启solr服务,然后进入主页访问查看分词效果,当然前提是你要有自己的solr实例(即solr库)

加词典
在F:\solr-6.0.0\server\solr-webapp\webapp\WEB-INF下新建classes文件夹,然后新建IKAnalyzer.cfg.xml配置文件,内容为:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict">ext.dic;</entry> <!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords">stopword.dic;</entry> </properties>
然后同级目录新增这两个dic文件,内容每行一个词,自己根据业务添加,也可以自己网上下载词库更新
第二种方式是tomcat下自定义部署solr,需要将solr包中的webapps部分复制到tomcat环境中,进行配置,详情可以自己网上找一下,不赘述,分词器配置也是一样的。
另外提一下solr删除全部索引数据的方法,在documents中,type选择xml,写上如下内容,点击提交,即可ok:
<delete><query>*:*</query></delete>
<commit/>
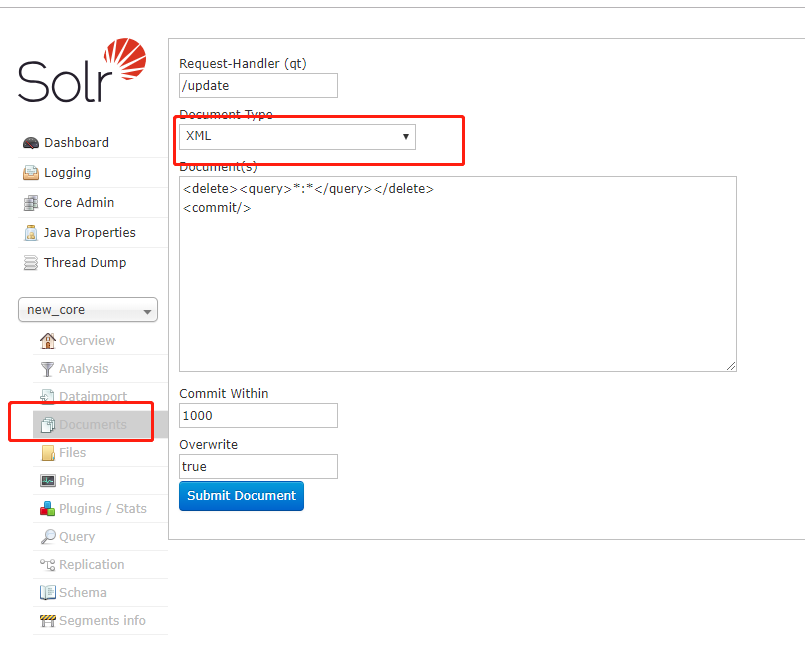
至于查询方法,新增方法,查询排序,加权重,加匹配度等,自己查,懒得写了。
然后值得一记的是cdh环境上的集成分词和部署,此处给自己留个提醒,其他人仅供参考
我这边的大数据环境是4台服务器的集群环境,用ZooKeeper来配置管理,solr便是在上面的,因为是配置管理所以都是模板复制一样的命令操作,虽然我一脸low逼的用FileZilla Client工具将jar包和配置的xml文件按上述本地配置的方式复制到4台服务器上,并且将分词jar包和词典配置都放在tomcat的环境下,
服务器但是重启solr服务后,无效,多次尝试后发现每次重启solr服务会把tomcat下的jar还原掉,问了下同事,才知道需要在服务器上执行一句命令来更新:solrctl instancedir --update suggest /var/lib/solr/suggest
注意:suggest 是我的服务器的实例名(solr库名称)
然后赶紧用xshell工具连上服务器(任意一台都可以),执行命令,但是发现执行完的反馈信息只是刷新了var/lib/solr/suggest /conf下的内容,我的jar包并没用刷新,重启后还是会覆盖放在tomcat/webapps下的solr应用下的web-inf下的lib的jar包,然后继续找问题。
最终在网上找到一片文章:https://blog.csdn.net/weixin_33716941/article/details/92202491
原来这个也是可以直接复制修改的,然后把jar复制到
/opt/cloudera/parcels/CDH-5.4.4-1.cdh5.4.4.pp0.4/lib/solr/webapps/solr/WEB-INF/lib下,再次重启solr服务OK了。
在高版本的CDH中,位置为:/usr/lib/solr/webapps/solr/WEB-INF/lib
另外需要注意的是:
solr版本和分词器的版本要对应,不能出现分词的jar版本高solr低的情况,否则配置完成后重启solr就会发现有错误
solr常用操作及集成分词器或cdh集群部署说明的更多相关文章
- Solr4.4入门,介绍Solr的安装、IK分词器的配置及高亮查询结果(转)
一.Windows下安装solr-4.4.0 1. 下载solr.4.4 2. 下载绿色版tomcat6.0.18 3. 解压下载的solr到d:\study\solr,将dist目录下的sol ...
- solr英文使用的基本分词器和过滤器配置
solr英文应用的基本分词器和过滤器配置 英文应用分词器和过滤器一般配置顺序 索引(index): 1:空格 WhitespaceTokenizer 2:过滤词(停用词,如:on.of.a.an ...
- Springboot 1.5.x 集成基于Centos7的RabbitMQ集群安装及配置
RabbitMQ简介 RabbitMQ是实现了高级消息队列协议(AMQP)的开源消息代理软件(亦称面向消息的中间件). RabbitMQ是一套开源(MPL)的消息队列服务软件,是由LShift提供的一 ...
- solr 集群(SolrCloud 分布式集群部署步骤)
SolrCloud 分布式集群部署步骤 安装软件包准备 apache-tomcat-7.0.54 jdk1.7 solr-4.8.1 zookeeper-3.4.5 注:以上软件都是基于 Linux ...
- Gitlab CI 集成 Kubernetes 集群部署 Spring Boot 项目
在上一篇博客中,我们成功将 Gitlab CI 部署到了 Docker 中去,成功创建了 Gitlab CI Pipline 来执行 CI/CD 任务.那么这篇文章我们更进一步,将它集成到 K8s 集 ...
- HBase集成Zookeeper集群部署
大数据集群为了保证故障转移,一般通过zookeeper来整体协调管理,当节点数大于等于6个时推荐使用,接下来描述一下Hbase集群部署在zookeeper上的过程: 安装Hbase之前首先系统应该做通 ...
- Hbase集群部署及shell操作
本文详述了Hbase集群的部署. 集群部署 1.将安装包上传到集群并解压 scp hbase-0.99.2-bin.tar.gz mini1:/root/apps/ tar -zxvf hbase-0 ...
- RabbitMQ (简单集群部署操作)
RabbitMQ 集群部署 前期准备 第一步:三台linux系统(centos7.3) 主机名(hostname) 网卡ip node1 192.168.137.138 node2 192.168.1 ...
- 13.solr学习速成之IK分词器
IKAnalyzer简介 IKAnalyzer是一个开源的,基于java语言开发的轻量级的中文分词工具包. IKAnalyzer特性 a. 算法采用“正向迭代最细粒度切分算法”,支持细粒度和最大词长两 ...
随机推荐
- 19徐州网络赛E 线段树加离散化
题目链接:https://nanti.jisuanke.com/t/41387 按wi的值建立权值线段树维护值为wi出现的最后位置,对于第i个人的答案,查询线段树[wi+m,max]区间的最大位置po ...
- [bzoj4815] [洛谷P3700] [Cqoi2017] 小Q的表格
Description 小Q是个程序员. 作为一个年轻的程序员,小Q总是被老C欺负,老C经常把一些麻烦的任务交给小Q来处理. 每当小Q不知道如何解决时,就只好向你求助.为了完成任务,小Q需要列一个表格 ...
- SycSec成都信息工程大学2019CTF-前五道WEB题writeup
一.WEB (1)一起来撸猫 flag藏在标签的注释内 <!--这是注释--> (2)你看见过我的菜刀么 eval漏洞 利用蚁剑连接 连接密码就是要post传的参数 连接成功后在网站根目 ...
- kuangbin专题专题十一 网络流 Dining POJ - 3281
题目链接:https://vjudge.net/problem/POJ-3281 题目:有不同种类的食物和饮料,每种只有1个库存,有N头牛,每头牛喜欢某些食物和某些饮料,但是一头牛 只能吃一种食物和喝 ...
- python GUI测试自动化
#! /usr/bin/env python#coding=GB18030'''GUI测试自动化 语言:python模块:pywinauto环境:windows7中文.python-2.6_32bit ...
- 「雅礼集训 2017 Day2」棋盘游戏
祝各位圣诞后快乐(逃) 题目传送门 分析: 首先棋盘上的路径构成的图是一张二分图 那么对于一个二分图,先求出最大匹配,先手如果走到关键匹配点,只要后手顺着匹配边走,由于不再会出现增广路径,所以走到最后 ...
- [HNOI2008]Cards(dp,Burnside引理)
Burnside引理: 参考自 某大佬对Burnside引理和Polya定理的讲解 相关概念 群:在数学中,群表示一个拥有满足封闭性.满足结合律.有单位元.有逆元的二元运算的代数结构. 置换群:由有限 ...
- 尼姆博弈+SG函数
博弈这个东西真的很费脑诶.. 尼姆博奕(Nim Game):游戏者轮流从一堆棋子(或者任何道具)中取走一个或者多个,最后不能再取的就是输家.当指定相应数量时,一堆这样的棋子称作一个尼姆堆 当n堆棋子的 ...
- Java反射机制——学习总结
前几天上REST课,因为涉及到Java的反射机制,之前看过一直没有用过,有些遗忘了,周末找了些资料来重新学习,现在总结一下,加深印象. 什么是反射机制? 参考百度百科对java反射机制的定义: “JA ...
- screen配置窗口显示
screen的下方不显示,可以复制如下的代码 cd /root && vim .screenrc 贴上如下内容 hardstatus on hardstatus alwayslastl ...