Scrapy五大核心组件简介
五大核心组件
scrapy框架主要由五大组件组成,他们分别是调度器(Scheduler),下载器(Downloader),爬虫(Spider),和实体管道(Item Pipeline),Scrapy引擎(Scrapy Fngine)
下面我们说说他们各自的作用:
调度器
用来接受引擎发过来的请求,由过滤器重复的url并将其压入队列中,在引擎再次请求的时候返回,
可以想象成一个URL(抓取网页的网址或者说是链接)的优先队列,由他决定下一个要抓取的网址是什么,用户可以根据自己的需求定制调度器
下载器
下载器,是所有组件中负担最大的,它用于高速地下载网络上的资源,Scrapy的下载器代码不会太复杂,但效率高(原因:Scrapy下载器是建立在twisted这个高效的异步模型上的)
爬虫
爬虫是主要干活的,用户最关心的部分, 它可以生成url, 并从特定的url中提取自己需要的信息, 即所谓的实体(Item). 用户也可以从中提取出链接, 让Scrapy继续抓取下一个页面.
实体管道
负责处理爬虫从网页中抽取的实体, 主要的功能是持久化实体、验证实体的有效性、清除不需要的信息. 当页面被爬虫解析后, 将被发送到项目管道, 并经过几个特定的次序处理数据.
引擎
Scrapy引擎是整个框架的核心。它用来控制调试器、下载器、爬虫。实际上,引擎相当于计算机的CPU,它控制着整个流程。对整个系统的数据流进行处理, 触发事务(框架核心).
工作流程
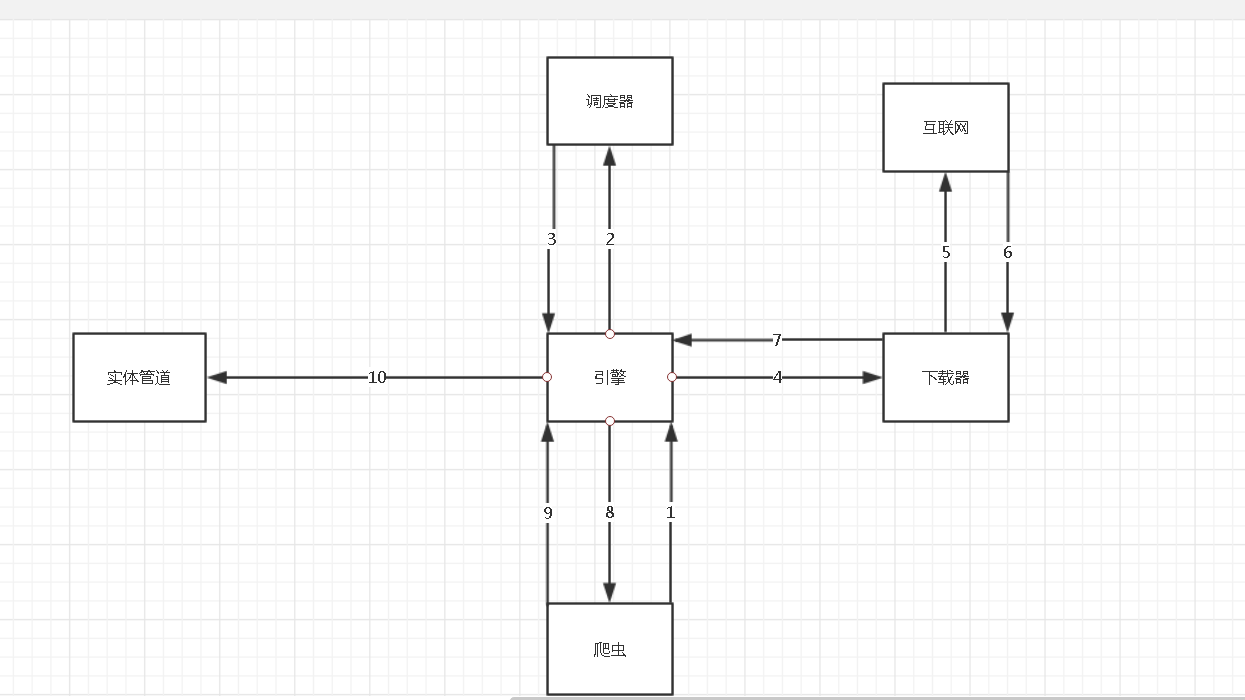
步骤详解:
1.spider中的url被封装成请求对象交给引擎(每一个对应一个请求对象)
2.引擎拿到请求对象之后,将全部交给调度器
3.调度器闹到所有请求对象后,通过内部的过滤器过滤掉重复的url,最后将去重后的所有url对应的请求对象压入到队列中,随后调度器调度出其中一个请求对象,并将其交给引擎
4.引擎将调度器调度出的请求对象交给下载器
5.下载器拿到该请求对象去互联网中下载数据
6.数据下载成功后会被封装到response中,随后response会被交给下载器
7.下载器将response交给引擎
8.引擎将response交给spiders
9.spiders拿到response后调用回调方法进行数据解析,解析成功后生成item,随后spiders将item交给引擎
10引擎将item交给管道,管道拿到item后进行数据的持久化存储
Scrapy五大核心组件简介的更多相关文章
- scrapy 五大核心组件-分页
scrapy 五大核心组件-分页 分页 思路 总的原理和之前是一样的,但是由于框架的原因,要遵循他框架的使用方式,每次更改他的url,并指定回调函数 # -*- coding: utf-8 -*- i ...
- Scrapy五大核心组件工作流程
一.Scrapy五大核心组件工作流程 1.核心组件 # 引擎(Scrapy) 对整个系统的数据流进行处理, 触发事务(框架核心). # 调度器(Scheduler) 用来接受引擎发过来的请求. 由过滤 ...
- scrapy五大核心组件
scrapy五大核心组件 引擎(Scrapy)用来处理整个系统的数据流处理, 触发事务(框架核心) 调度器(Scheduler)用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回. ...
- scrapy五大核心组件和中间件以及UA池和代理池
五大核心组件的工作流程 引擎(Scrapy) 用来处理整个系统的数据流处理, 触发事务(框架核心) 调度器(Scheduler) 用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回. ...
- 爬虫-scrapy五大核心组件及工作流
- scrapy之五大核心组件
scrapy之五大核心组件 scrapy一共有五大核心组件,分别为引擎.下载器.调度器.spider(爬虫文件).管道. 爬虫文件的作用: a. 解析数据 b. 发请求 调度器: a. 队列 队列是一 ...
- Scrapy 框架 安装 五大核心组件 settings 配置 管道存储
scrapy 框架的使用 博客: https://www.cnblogs.com/bobo-zhang/p/10561617.html 安装: pip install wheel 下载 Twisted ...
- scrapy框架post请求发送,五大核心组件,日志等级,请求传参
一.post请求发送 - 问题:爬虫文件的代码中,我们从来没有手动的对start_urls列表中存储的起始url进行过请求的发送,但是起始url的确是进行了请求的发送,那这是如何实现的呢? - 解答: ...
- python爬虫---scrapy框架爬取图片,scrapy手动发送请求,发送post请求,提升爬取效率,请求传参(meta),五大核心组件,中间件
# settings 配置 UA USER_AGENT = 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, l ...
随机推荐
- MySQL--python关联MySQL、练习题
1.python关联MySQL pymysql: 安装:pip3 install pymysql 1.0:连接到数据库中 import pymysql conn = pymysql.connect( ...
- Chrome谷歌浏览器调试
Chrome浏览器调试技巧 https://blog.csdn.net/u014727260/article/details/53231298
- Leetcode665.Non-decreasing Array非递减数组
给定一个长度为 n 的整数数组,你的任务是判断在最多改变 1 个元素的情况下,该数组能否变成一个非递减数列. 我们是这样定义一个非递减数列的: 对于数组中所有的 i (1 <= i < n ...
- 【weex】publishTask
这个小项目还挺有意思的,是一个效果取快递的项目 我们看下效果 放博客的github地址:https://github.com/xiaomaer/publishTask 我们来看下代码,这几个页面运行的 ...
- Oracle存储1.1
1.生成一个表的简单sql语句 CREATE OR REPLACE PROCEDURE proc_AutoGenerateSQL( tableName VARCHAR2 ,--参数 需要操作的表 ...
- ip地址获取无效,自己修改ip地址
(1)
- js读取解析JSON数据(转)
JSON(JavaScript Object Notation) 是一种轻量级的数据交换格式,采用完全独立于语言的文本格式,是理想的数据交换格式.同时,JSON是 JavaScript 原生格式,这意 ...
- 使用 store 来优化 React 组件
在使用 React 编写组件的时候,我们常常会碰到两个不同的组件之间需要共享状态情况,而通常的做法就是提升状态到父组件.但是这样做会有一个问题,就是尽管只有两个组件需要这个状态,但是因为把状态提到了父 ...
- 前端与编译原理——用JS写一个JS解释器
说起编译原理,印象往往只停留在本科时那些枯燥的课程和晦涩的概念.作为前端开发者,编译原理似乎离我们很远,对它的理解很可能仅仅局限于"抽象语法树(AST)".但这仅仅是个开头而已.编 ...
- SDUT-3402_数据结构实验之排序五:归并求逆序数
数据结构实验之排序五:归并求逆序数 Time Limit: 50 ms Memory Limit: 65536 KiB Problem Description 对于数列a1,a2,a3-中的任意两个数 ...