python爬取365好书中小说
需要转载的小伙伴转载后请注明转载的地址
需要用到的库
from bs4 import BeautifulSoup
import requests
import time
365好书链接:http://www.365haoshu.com/ 爬取《我以月夜寄相思》小说
首页进入到目录:http://www.365haoshu.com/Book/Chapter/List.aspx?NovelId=3026
获取小说的每个章节的名称和章节链接
打开浏览器的开发者工具,查找一个章节:如下图,找到第一章的名称和href(也就是第一章节内容页面的链接),开始写代码
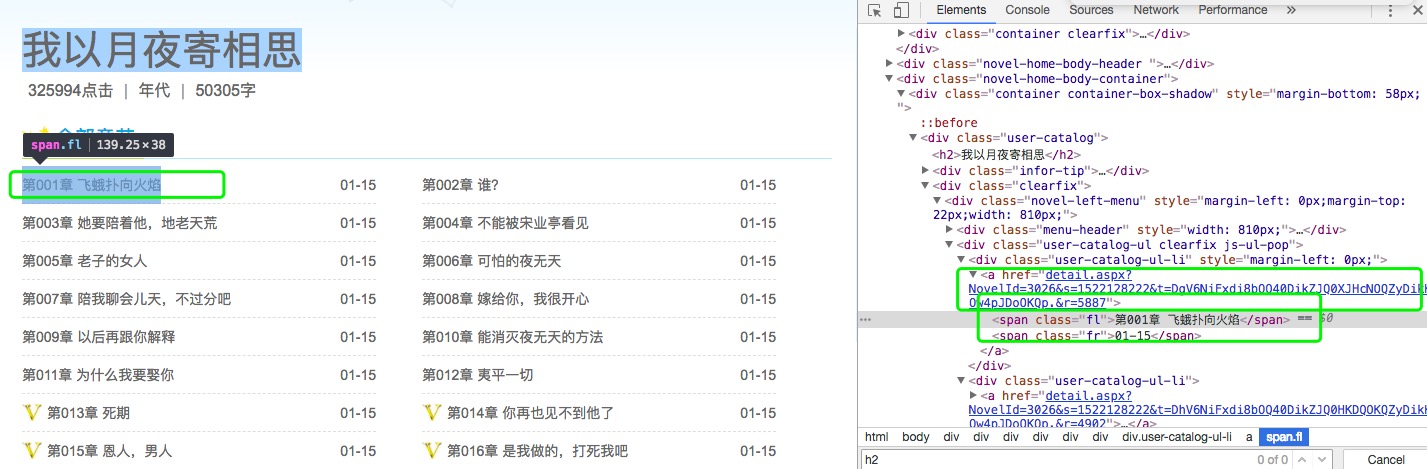
from bs4 import BeautifulSoup
import requests
import time
# 分别导入time、requests、BeautifulSoup库
url = 'http://www.365haoshu.com/Book/Chapter/'
# 链接地址url,这儿url章节链接没全写出来是因为下面获取章节链接时要用到这些url
req = requests.get(url+'List.aspx?NovelId=0326')
# 打开章节页面,
req_bf = BeautifulSoup(req.text,"html.parser")
print(req_bf)
# 将打开的页面以text打印出来
div = req_bf.find_all('div',class_='user-catalog-ul-li')
# 分析页面,所需要的章节名和章节链接是在div标签,属性class为user-catalog-ul-li下
# 找到这个下的内容,并打印
s = []
for d in div:
s.append(d.find('a'))
print(s)
# 获取div下面的a标签下的内容
names=[] # 存储章节名
hrefs=[] # 存储章节链接
for i in s:
names.append(i.find('span').string)
hrefs.append(url + i.get('href'))
# 将所有的章节和章节链接存入的列表中
观察href后的链接和打开章节内容页面的链接是不完全的相同的, 所以要拼接使得浏览器能直接打开章节内容
获取到链接和章节名后打开一个章节获取文本内容;
和获取章节名方法一致,一步一步查找到内容的位置
txt = requests.get(hrefs[0])
div_bf = BeautifulSoup(txt.text,'html.parser')
div = div_bf.find_all('div',class_='container user-reading-online pos-rel')
#print(div)
ps = BeautifulSoup(str(div),"html.parser")
p=ps.find_all('p',class_='p-content')
print(p)
txt=[]
for i in p:
txt.append(i.string+'\n')
print(txt)
获取单一章节完成
接下来整理代码,获取整个小说的内容,代码如下:
# --*-- coding=utf-8 --*--
from bs4 import BeautifulSoup
import requests
import time
class spiderstory(object):
def __init__(self): # 初始化
self.url = 'http://www.365haoshu.com/Book/Chapter/'
self.names = [] # 存放章节名
self.hrefs = [] # 存放章节链接
def get_urlAndName(self):
'''获取章节名和章节链接'''
req = requests.get(url=self.url+'List.aspx?NovelId=0326') # 获取章节目录页面
time.sleep(1) # 等待1秒
div_bf = BeautifulSoup(req.text,"html.parser") # req后面跟text和html都行
div = div_bf.find_all('div', class_='user-catalog-ul-li') # 查找内容,标签为div,属性为class='user-catalog-ul-li'
a_bf = BeautifulSoup(str(div))
a = a_bf.find_all('a') # # 查找内容,标签为a
for i in a:
self.names.append(i.find('span').string) # 获取内容直接string就行
self.hrefs.append(self.url + i.get('href')) # 获取链接
def get_text(self,url):
'''获取章节内容'''
req = requests.get(url=url)
div_bf = BeautifulSoup(req.text,"html.parser")
div = div_bf.find_all('div', class_='container user-reading-online pos-rel') # 查找内容
ps = BeautifulSoup(str(div), "html.parser")
p = ps.find_all('p', class_='p-content')
text = []
for each in p:
text.append(each.string)
print(text)
return text # 将获得的内容返回
def writer(self, name, path, text):
'''写入text文档中'''
with open(path, 'a', encoding='utf-8') as f:
f.write(name + '\n')
f.writelines(text)
f.write('\n\n')
if __name__ == "__main__": # 运行入口
s = spiderstory()
s.get_urlAndName()
le = len(s.names)
for i in range(le): # 利用for循环获得所有的内容
name = s.names[i]
text = str(s.get_text(s.hrefs[i]))
s.writer(name,"我以月夜寄相思.txt",text)
print('下载完毕!!!')
python爬取365好书中小说的更多相关文章
- Python爬取贴吧中的图片
#看到贴吧大佬在发图,准备盗一下 #只是爬取一个帖子中的图片 1.先新建一个scrapy项目 scrapy startproject TuBaEx 2.新建一个爬虫 scrapy genspider ...
- python 爬取全本免费小说网的小说
这几天朋友说想看电子书,但是只能在网上看,不能下载到本地后看,问我有啥办法?我找了好几个小说网址看了下,你只能直接在网上看,要下载txt要冲钱买会员,而且还不能在浏览器上直接复制粘贴.之后我就想到py ...
- Python爬取笔趣阁小说,有趣又实用
上班想摸鱼?为了摸鱼方便,今天自己写了个爬取笔阁小说的程序.好吧,其实就是找个目的学习python,分享一下. 1. 首先导入相关的模块 import os import requests from ...
- python爬取返利网中值得买中的数据
先使用以前的方法将返利网的数据爬取下来,scrapy框架还不熟练,明日再战scrapy 查找目标数据使用的是beautifulsoup模块. 1.观察网页,寻找规律 打开值得买这块内容 1>分析 ...
- python入门学习之Python爬取最新笔趣阁小说
Python爬取新笔趣阁小说,并保存到TXT文件中 我写的这篇文章,是利用Python爬取小说编写的程序,这是我学习Python爬虫当中自己独立写的第一个程序,中途也遇到了一些困难,但是最后 ...
- Python爬取招聘信息,并且存储到MySQL数据库中
前面一篇文章主要讲述,如何通过Python爬取招聘信息,且爬取的日期为前一天的,同时将爬取的内容保存到数据库中:这篇文章主要讲述如何将python文件压缩成exe可执行文件,供后面的操作. 这系列文章 ...
- 14.python案例:爬取电影天堂中所有电视剧信息
1.python案例:爬取电影天堂中所有电视剧信息 #!/usr/bin/env python3 # -*- coding: UTF-8 -*- '''======================== ...
- Python爬取CSDN博客文章
0 url :http://blog.csdn.net/youyou1543724847/article/details/52818339Redis一点基础的东西目录 1.基础底层数据结构 2.win ...
- python爬取《龙岭迷窟》的数据,看看质量剧情还原度到底怎么样
前言 文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者:简单 PS:如有需要Python学习资料的小伙伴可以加点击下方链接自行 ...
随机推荐
- Struts源码之ValueStack
/** * ValueStack allows multiple beans to be pushed in and dynamic EL expressions to be evaluated ag ...
- CentOS服务器下JavaEE环境搭建指南(远程桌面+JDK+Tomcat+MySQL)
--------------------------------------------------------------------------------1 系统设置:1.1 远程桌面设置:通过 ...
- rails项目编写中的一些小技巧小心得
1. 如果form中有数据要传回服务器可以用隐藏属性的控件: form_for(xxx) do |f| f.hidden_field :xxx,value:xxx end 2. 如果你需要一些信息放在 ...
- java多线程的基础-java内存模型(JMM)
在并发编程中,需要处理两个关键问题:线程之间如何通信,以及线程之间如何同步.通信是指线程之间如何交换信息,在命令式编程中,线程之间的通信机制有两种:内存共享和消息传递. 同步是指程序中用于控 ...
- Java IO学习--(二)文件
在Java应用程序中,文件是一种常用的数据源或者存储数据的媒介.所以这一小节将会对Java中文件的使用做一个简短的概述.这篇文章不会对每一个技术细节都做出解释,而是会针对文件存取的方法提供给你一些必要 ...
- dom4j 解析 xml标签属性
重写onEnd()和onStart()方法 public class XmlElementHandler implements ElementHandler { @Override public vo ...
- 如何修改和查看tomcat内存大小
为了解决tomcat在大进行大并发请求时,出现内存溢出的问题,请修改tomcat的内存大小,其中分为以下两种方式: 一.使用 catalina.bat 等命令行方式运行的 tomcat 查看系统最大支 ...
- JAVA堆栈的区别
1. 栈(stack)与堆(heap)都是Java用来在Ram中存放数据的地方.与C++不同,Java自动管理栈和堆,程序员不能直接地设置栈或堆. 2. 栈的优势是,存取速度 ...
- IIR滤波器软件实现(Matlab+C++)
使用C++来写一个IIR滤波器 我们首先要在MATLAB中设计一个IIR滤波器,并生成一个头文件,这个头文件中反映了IIR滤波器的频率响应特性 理论支持 IIR滤波叫做递归滤波器,它是一种具有反馈的滤 ...
- YUV420格式解析
一般的的YUV420图像格式实际上是Y'UV,420指的是其在Y U V上面的采样率.在YUV420的格式中,首先存储每一个像素的Y'值,然后跟着存储的是每2*2方阵采样一次的U值,最后存储的是每2* ...