基于python的scrapy框架爬取豆瓣电影及其可视化
1.Scrapy框架介绍
主要介绍,spiders,engine,scheduler,downloader,Item pipeline
scrapy常见命令如下:
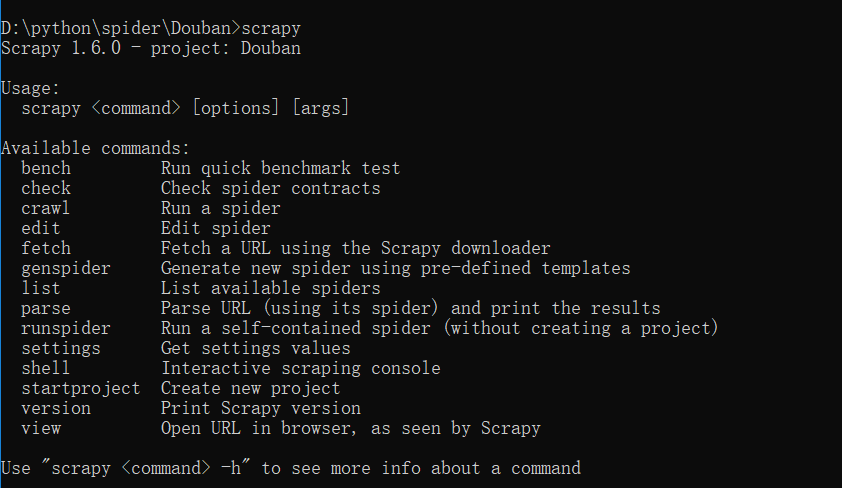
对应在scrapy文件中有,自己增加爬虫文件,系统生成items,pipelines,setting的配置文件就这些。
items写需要爬取的属性名,pipelines写一些数据流操作,写入文件,还是导入数据库中。主要爬虫文件写domain,属性名的xpath,在每页添加属性对应的信息等。
movieRank = scrapy.Field()
movieName = scrapy.Field()
Director = scrapy.Field()
movieDesc = scrapy.Field()
movieRate = scrapy.Field()
peopleCount = scrapy.Field()
movieDate = scrapy.Field()
movieCountry = scrapy.Field()
movieCategory = scrapy.Field()
moviePost = scrapy.Field()
import json class DoubanPipeline(object):
def __init__(self):
self.f = open("douban.json","w",encoding='utf-8') def process_item(self, item, spider):
content = json.dumps(dict(item),ensure_ascii = False)+"\n"
self.f.write(content)
return item def close_spider(self,spider):
self.f.close()
这里xpath使用过程中,安利一个chrome插件xpathHelper。
allowed_domains = ['douban.com']
baseURL = "https://movie.douban.com/top250?start="
offset = 0
start_urls = [baseURL + str(offset)] def parse(self, response):
node_list = response.xpath("//div[@class='item']") for node in node_list:
item = DoubanItem()
item['movieName'] = node.xpath("./div[@class='info']/div[1]/a/span/text()").extract()[0]
item['movieRank'] = node.xpath("./div[@class='pic']/em/text()").extract()[0]
item['Director'] = node.xpath("./div[@class='info']/div[@class='bd']/p[1]/text()[1]").extract()[0]
if len(node.xpath("./div[@class='info']/div[@class='bd']/p[@class='quote']/span[@class='inq']/text()")):
item['movieDesc'] = node.xpath("./div[@class='info']/div[@class='bd']/p[@class='quote']/span[@class='inq']/text()").extract()[0]
else:
item['movieDesc'] = "" item['movieRate'] = node.xpath("./div[@class='info']/div[@class='bd']/div[@class='star']/span[@class='rating_num']/text()").extract()[0]
item['peopleCount'] = node.xpath("./div[@class='info']/div[@class='bd']/div[@class='star']/span[4]/text()").extract()[0]
item['movieDate'] = node.xpath("./div[2]/div[2]/p[1]/text()[2]").extract()[0].lstrip().split('\xa0/\xa0')[0]
item['movieCountry'] = node.xpath("./div[2]/div[2]/p[1]/text()[2]").extract()[0].lstrip().split('\xa0/\xa0')[1]
item['movieCategory'] = node.xpath("./div[2]/div[2]/p[1]/text()[2]").extract()[0].lstrip().split('\xa0/\xa0')[2]
item['moviePost'] = node.xpath("./div[@class='pic']/a/img/@src").extract()[0]
yield item if self.offset <250:
self.offset += 25
url = self.baseURL+str(self.offset)
yield scrapy.Request(url,callback = self.parse)
这里基本可以爬虫,产生需要的json文件。
接下来是可视化过程。
我们先梳理一下,我们掌握的数据情况。
douban = pd.read_json('douban.json',lines=True,encoding='utf-8')
douban.info()
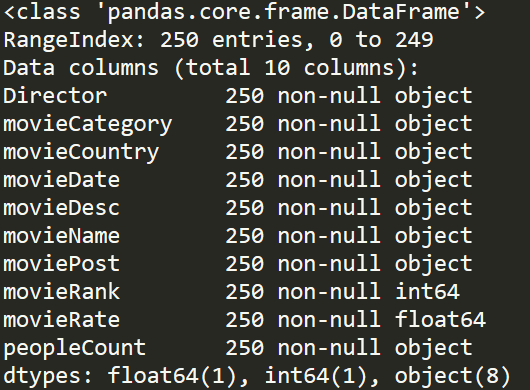
基本我们可以分析,电影国家产地,电影拍摄年份,电影类别以及一些导演在TOP250中影响力。
先做个简单了解,可以使用value_counts()函数。
douban = pd.read_json('douban.json',lines=True,encoding='utf-8')
df_Country = douban['movieCountry'].copy()
for i in range(len(df_Country)):
item = df_Country.iloc[i].strip()
df_Country.iloc[i] = item[0]
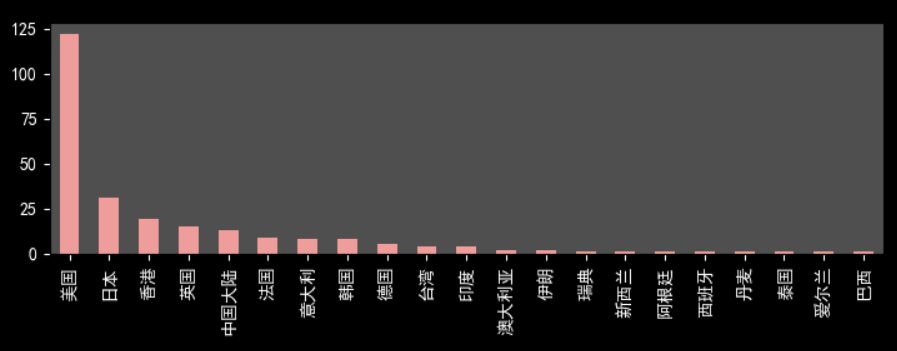
print(df_Country.value_counts())

美国电影占半壁江山,122/250,可以反映好莱坞电影工业之强大。同样,日本电影和香港电影在中国也有着重要地位。令人意外是,中国大陆地区电影数量不是令人满意。豆瓣影迷对于国内电影还是非常挑剔的。
douban = pd.read_json('douban.json',lines=True,encoding='utf-8')
df_Date = douban['movieDate'].copy()
for i in range(len(df_Date)):
item = df_Date.iloc[i].strip()
df_Date.iloc[i] = item[2]
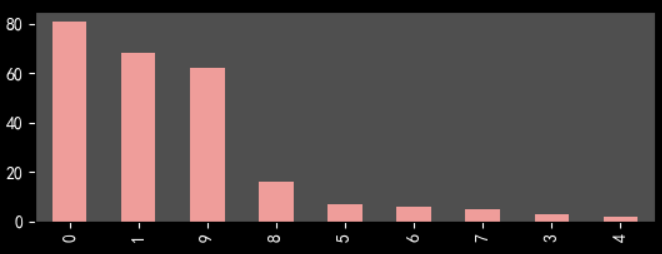
print(df_Date.value_counts())
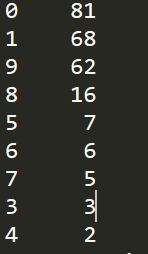
2000年以来电影数目在70%以上,考虑10代才过去9年和打分滞后性,总体来说越新的电影越能得到受众喜爱。这可能和豆瓣top250选取机制有关,必须人数在一定数量以上。
douban = pd.read_json('douban.json',lines=True,encoding='utf-8')
df_Cate = douban['movieCategory'].copy()
for i in range(len(df_Cate)):
item = df_Cate.iloc[i].strip()
df_Cate.iloc[i] = item[0]
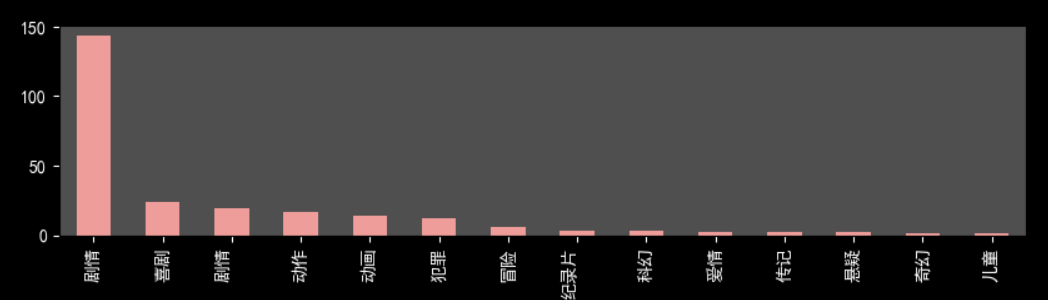
print(df_Cate.value_counts())
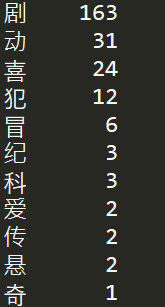
剧情电影情节起伏更容易得到观众认可。
下面展示几张可视化图片
不太会用python进行展示,有些难看。其实,推荐用Echarts等插件,或者用Excel,BI软件来处理图片,比较方便和美观。
第一次做这种爬虫和可视化,多有不足之处,恳请指出。
基于python的scrapy框架爬取豆瓣电影及其可视化的更多相关文章
- Python爬虫入门:爬取豆瓣电影TOP250
一个很简单的爬虫. 从这里学习的,解释的挺好的:https://xlzd.me/2015/12/16/python-crawler-03 分享写这个代码用到了的学习的链接: BeautifulSoup ...
- Python使用Scrapy框架爬取数据存入CSV文件(Python爬虫实战4)
1. Scrapy框架 Scrapy是python下实现爬虫功能的框架,能够将数据解析.数据处理.数据存储合为一体功能的爬虫框架. 2. Scrapy安装 1. 安装依赖包 yum install g ...
- scrapy框架爬取豆瓣读书(1)
1.scrapy框架 Scrapy,Python开发的一个快速.高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据.Scrapy用途广泛,可以用于数据挖掘.监测和自动化测试 ...
- Python的scrapy之爬取豆瓣影评和排名
基于scrapy框架的爬影评 爬虫主程序: import scrapy from ..items import DoubanmovieItem class MoviespiderSpider(scra ...
- python爬虫scrapy框架——爬取伯乐在线网站文章
一.前言 1. scrapy依赖包: 二.创建工程 1. 创建scrapy工程: scrapy staratproject ArticleSpider 2. 开始(创建)新的爬虫: cd Artic ...
- python利用scrapy框架爬取起点
先上自己做完之后回顾细节和思路的东西,之后代码一起上. 1.Mongodb 建立一个叫QiDian的库,然后建立了一个叫Novelclass(小说类别表)Novelclass(可以把一级类别二级类别都 ...
- python scrapy框架爬取豆瓣
刚刚学了一下,还不是很明白.随手记录. 在piplines.py文件中 将爬到的数据 放到json中 class DoubanmoviePipelin2json(object):#打开文件 open_ ...
- 初识python 之 爬虫:爬取豆瓣电影最热评论
主要用到lxml的etree解析网页代码,xpath获取HTML标签. 代码如下: 1 #!/user/bin env python 2 # author:Simple-Sir 3 # time:20 ...
- scrapy爬虫框架教程(二)-- 爬取豆瓣电影TOP250
scrapy爬虫框架教程(二)-- 爬取豆瓣电影TOP250 前言 经过上一篇教程我们已经大致了解了Scrapy的基本情况,并写了一个简单的小demo.这次我会以爬取豆瓣电影TOP250为例进一步为大 ...
随机推荐
- linq to sql 和linq to php 的区别
linq to sql 这是自.net框架3.5版本以上做出了相关规定. linq to php .Net的linq库的忠实移植到PHP 这个库使得大量使用匿名函数在PHP 5.3中引入的功能.因此, ...
- 优化方法:SGD,Momentum,AdaGrad,RMSProp,Adam
参考: https://blog.csdn.net/u010089444/article/details/76725843 1. SGD Batch Gradient Descent 在每一轮的训练过 ...
- [转] Eclipse安装SVN插件
eclipse里安装SVN插件,一般来说,有三种方式: 1. 直接下载SVN插件,将其解压到eclipse的对应目录里 2. 使用eclipse 里Help菜单的“Install New Softwa ...
- $2018/8/15 = Day \ \ 1$杂题整理
\(\mathcal{Morning}\) \(Task1\)高精度\(\times\)高精度 哦呵呵--真是喜闻乐见啊,我发现这一部分比较有意思于是就打算整理下来233.窝萌现在有一个整数\(A = ...
- iOS:WKWebView(19-01-31更)
以前用得不多,先开一篇,以后有遇到再补充. 1.返回 2.JS 调用 OC 3.获取.修改.添加网页信息 1.返回 if (self.mWebView.canGoBack == YES) { [sel ...
- Go语言连接Oracle(就我这个最全)
综合参考了网上挺多的方案 倒腾了半天终于连接好了 Go都出来这么多年了 还没有个Oracle的官方驱动... 过程真的很蛋疼..一度想放弃直接连ODBC 首先交代一下运行环境和工具版本: WIN10 ...
- 20155234 2016-2017-2 《Java程序设计》第7周学习总结
20155234 2016-2017-2 <Java程序设计>第7周学习总结 教材学习内容总结 第十二章 Lambda Lambda表达式会使程序更加地简洁,在平行设计的时候,能够进行并行 ...
- 确定有限自动机 valid number
原题地址:http://oj.leetcode.com/problems/valid-number/ 题意:判断输入的字符串是否是合法的数. 解题思路:这题只能用确定有穷状态自动机(DFA)来写会比较 ...
- PPAS可以安装分区表
磨砺技术珠矶,践行数据之道,追求卓越价值 回到上一级页面: PostgreSQL基础知识与基本操作索引页 回到顶级页面:PostgreSQL索引页 [作者 高健@博客园 luckyjackg ...
- [Qt扒手2] PyQt5 路径绘画例子
[说明] 此例扒自 Qt 官网,原例是 C++ 代码,我把它改写成了 Python + PyQt5 版本. 有了前一个例子的成功,这个例子改写的非常之快.记得第一个例子花了我几天的时间,而这个例子只花 ...