[读书笔记] R语言实战 (十三) 广义线性模型
广义线性模型扩展了线性模型的框架,它包含了非正态的因变量分析
广义线性模型拟合形式:
$$g(\mu_\lambda) = \beta_0 + \sum_{j=1}^m\beta_jX_j$$
$g(\mu_\lambda)为连接函数$. 假设响应变量服从指数分布族中某个分布(不仅仅是正态分布),极大扩展了标准线性模型,模型参数估计的推导依据是极大似然估计,而非最小二乘法.
可以放松Y为正态分布的假设,改为Y服从指数分布族中的一种分布即可
glm()函数:glm(formula,family=family(link=function), data = )

Logistic regression:响应变量为二值(0,1), 模型假设Y服从二项分布,线性模型拟合形式:
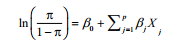
可用以下代码拟合Logistic回归:glm(Y~X1+X2+X3, family = binomial(link='logit',data=mydata)
#通过婚外情数据来预测婚外情情况
#每个参与者身上有9个变量:性别,年龄,婚龄,是否有小孩,宗教信仰程度,
#学历,职业,婚姻自我评分
library(AER)
data(Affairs,package = 'AER')
#查看描述性统计信息
summary(Affairs)
#将affairs转化Wie二值因子ynaaffair
Affairs$ynaffair[Affairs$affairs > 0] <-1
Affairs$ynaffair[Affairs$affairs == 0] <-0
Affairs$ynaaffair <- factor(Affairs$ynaffair,levels=c(0,1),labels=c("NO","Yes"))
table(Affairs$ynaffair)
#因子化之后的值可以作为Logistic回归的结果变量
fit.full <- glm(ynaffair~gender+age+yearsmarried+children+religiousness+education+occupation+rating,data=Affairs,family=binomial())
#描述模型
summary(fit.full)
#由P值得出性别,孩子,学历,职业对方程的贡献不显著,去除这些变量重新拟合
fit.reduced <- glm(ynaffair~age+yearsmarried+religiousness+rating,data=Affairs,family=binomial())
summary(fit.reduced)
#由结果可以看出这次个每个回归系数都很显著
#由于两个模型嵌套,可以使用anova()对他们进行比较
#卡方值p=0.21,表明四个预测变量的新模型与九个预测变量的模拟拟合程度一样好
anova(fit.reduced,fit.full,test='Chisq')
#解释模型系数:对数优势
coef(fit.reduced)
#指数优势
exp(coef(fit.reduced))
#评价预测变量对结果概率的影响
#婚姻评分对婚外情概率的影响
#创建虚拟数据集,年龄,婚龄,宗教信仰均为均值,婚姻评分为1-5
testdata <- data.frame(rating=c(1,2,3,4,5),age=mean(Affairs$age),yearsmarried=mean(Affairs$yearsmarried),religiousness=mean(Affairs$religiousness))
testdata$prob = predict(fit.reduced,newdata = testdata,type="response")
testdata
Logistic 回归变种:
- 稳健Logistic regression: robust包中glmRob()函数可以拟合文件的广义线性模型,当拟合回归模型出现离群点的强影响点时,稳健logistic regression便可以派生用场.
- 多项布回归,若响应变量包含两个以上无序类比(已婚,寡居,离婚),便可以使用mlogit包中的mlogit()函数拟合多项Logistic回归
- 序数Logistic回归,若响应变量是一组有序类别(好,中,差),便可以使用rms()包中的mlogit()函数拟合多项logistic回归
Poisson regression:响应变量为计数型, 模型假设Y服从泊松分布, 线性模型拟合形式:
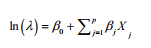
许多分析标准线性模型lm()连用的函数在glm()中都有对应的形式:


#使用robust包中的癫痫数据Breslow,来讨论癫痫数据对癫痫发病率的影响
library(robust)
data(breslow.dat,package = "robust")
names(breslow.dat)
#我们只关注,Trt治疗条件,Age:年龄,基础癫痫发病数Base, 响应变量为sumY随机化后八周内癫痫发病数
summary(breslow.dat[c(6,7,8,10)])
opar <- par(no.readonly = TRUE)
par(mfrow=c(1,2))
attach(breslow.dat)
#图中可以看到因变量的偏倚特性和可能的离群点
hist(sumY,breaks = 20,xlab = "Seizure count",main="Distribution of Seizures")
boxplot(sumY~Trt,xlab="Treatment",main="Group Comarisons")
par(opar)
#拟合泊松回归
fit <- glm(sumY~Base+Age+Trt,data=breslow.dat,family=poisson())
summary(fit)
#获取模型系数
coef(fit)
exp(coef(fit))
泊松回归的的变种:
- 时间段变化泊松回归
- 零膨胀泊松回归:logisitic regression + poisson regression
模型拟合和回归诊断:
1. 初始响应变量的预测值和残差的图形
2. 检验模型是否过度离势
[读书笔记] R语言实战 (十三) 广义线性模型的更多相关文章
- [读书笔记] R语言实战 (一) R语言介绍
典型数据分析的步骤: R语言:为统计计算和绘图而生的语言和环境 数据分析:统计学,机器学习 R的使用 1. 区分大小写的解释型语言 2. R语句赋值:<- 3. R注释: # 4. 创建向量 c ...
- [读书笔记] R语言实战 (二) 创建数据集
R中的数据结构:标量,向量,数组,数据框,列表 1. 向量:储存数值型,字符型,或者逻辑型数据的一维数组,用c()创建 ** R中没有标量,标量以单元素向量的形式出现 2. 矩阵:二维数组,和向量一 ...
- [读书笔记] R语言实战 (四) 基本数据管理
1. 创建新的变量 mydata<-data.frame(x1=c(2,2,6,4),x2=c(3,4,2,8)) #方法一 mydata$sumx<-mydata$x1+mydata$x ...
- [读书笔记] R语言实战 (六) 基本图形方法
1. 条形图 barplot() #载入vcd包 library(vcd) #table函数提取各个维度计数 counts <- table(Arthritis$Improved) count ...
- [读书笔记] R语言实战 (十四) 主成分和因子分析
主成分分析和探索性因子分析是用来探索和简化多变量复杂关系的常用方法,能解决信息过度复杂的多变量数据问题. 主成分分析PCA:一种数据降维技巧,将大量相关变量转化为一组很少的不相关变量,这些无关变量称为 ...
- [读书笔记] R语言实战 (三) 图形初阶
创建图形,保存图形,修改特征:标题,坐标轴,标签,颜色,线条,符号,文本标注. 1. 一个简单的例子 #输出到图形到pdf文件 pdf("mygrapg.pdf") attach( ...
- [读书笔记] R语言实战 (五) 高级数据管理
1. 数值函数 1) 数学函数 2) 统计函数 3. 数据标准化 scale() 函数对矩阵或者数据框的指定列进行均值为0,标准化为1的标准化 mydata <- data.frame(c1=c ...
- R语言实战(八)广义线性模型
本文对应<R语言实战>第13章:广义线性模型 广义线性模型扩展了线性模型的框架,包含了非正态因变量的分析. 两种流行模型:Logistic回归(因变量为类别型)和泊松回归(因变量为计数型) ...
- 《R语言实战》读书笔记--为什么要学
本人最近在某咨询公司实习,涉及到了一些数据分析的工作,用的是R语言来处理数据.但是在应用的过程中,发现用R很不熟练,所以再打算学一遍R.曾经花一个月的时间看过一遍<R语言编程艺术>,还用R ...
随机推荐
- C# XML 反序列化解析
自己用.记录一下! 用于配置文件的解析,可以用来设置配置.不用修改程序里参数. 用微软的XML 解析器来解析的. 1. Xml文件 文件名称:TestConfig.xml <?xml versi ...
- 可序列化serializable的作用是什么
什么情况下需要序列化:a)当你想把的内存中的对象写入到硬盘的时候:b)当你想用套接字在网络上传送对象的时候: 为什么要序列化: 为了将对象可以以流的方式传输到其他位置,就必须要将该对象定义为可序列化的 ...
- 在magento的eav模型中如何在更新记录时只在value表的原值上更新
1,一般情况下,当我们在调用getModel在load某条实体接着更新对应实体上的值是,都不会覆盖原来的实体value表上的值,而是保留原来的,并在value表上重新创建一条值记录,比如初始表如下: ...
- Eclipse开发C/C++程序的MinGw配置
环境变量设置: a.鼠标右击桌面"计算机"(WindowsXp是"我的电脑")->"属性" b.WindowsXP时,在新弹出的属性窗 ...
- 鸟哥Linux私房菜知识点总结3到5章
感觉自己对Linux的理解一直不够,所以近期翻看了一本<鸟哥的Linux私房菜>.这是一本基础的书,万丈高楼平地起,会的不多但能够学.这是我整理的一些知识点,尽管非常基础.希望和大家共同交 ...
- Apache Kylin高级部分之使用Hive视图
本章节我们将介绍为什么须要在Kylin创建Cube过程中使用Hive视图.而假设使用Hive视图.能够带来什么优点.解决什么样的问题.以及须要学会怎样使用视图.使用视图有什么限制等等. 1. ...
- android帧动画,移动位置,缩放,改变透明度等动画解说
1.苦逼的需求又来了,须要实现一些动画效果,第一个想到的是播放gif图片,可是这样会占包的资源,而且清晰度不高,于是想着程序实现,自己用帧动画+缩放+移动+透明度 实现了一些想要的效果,这里跟大家分享 ...
- Sqoop_具体总结 使用Sqoop将HDFS/Hive/HBase与MySQL/Oracle中的数据相互导入、导出
一.使用Sqoop将MySQL中的数据导入到HDFS/Hive/HBase watermark/2/text/aHR0cDovL2Jsb2cuY3Nkbi5uZXQvYWFyb25oYWRvb3A=/ ...
- DOM基础----DOM(一)
DOM(Document Object Model),中文名称为文档对象模型.是处理可扩展标识语言的标准编程接口,主要针对HTML和XML.DOM描绘了一个层次化的节点树,开发者能够加入.改动和移除页 ...
- Android圆角Tag控件的另类实现
一般的圆角标签控件都是用xml设置shape做实现.可是假设我们想要做一个更加强大通用的的圆角控件,不须要使用者去关心圆角,仅仅设置背景就能够了. 应该怎么实现呢?这个就须要把背景先设置成图片,然后再 ...