hadoop 3.x 配置历史服务器
修改$HADOOP_HOME/etc/hadoop/mapred-site.xml,加入以下配置(修改主机名为你自己的主机或IP,尽量不要使用中文注释)
<!--history address-->
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop002:10020</value>
</property>
<!--history web address-->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop002:19888</value>
</property>
依次执行start-dfs.sh,start-yarn.sh后jps查看namenode,datanode等是否启动,成功启动后启动history服务进程,执行mr-jobhistory-daemon.sh start historyserver,之后jps查看进程
(停止:mr-jobhistory-daemon.sh stop historyserver)
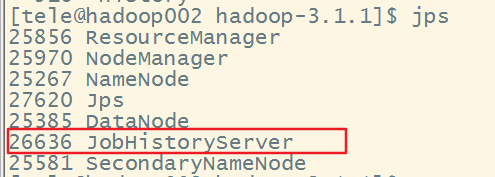
接下来执行MapReduce程序
hadoop fs -rm -r -f /usr/tele/hadoop/wcoutput
hadoop jar /opt/module/hadoop-3.1.1/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.1.jar wordcount /usr/tele/hadoop/wcinput /usr/tele/hadoop/wcoutput
执行完毕后进入mapreduce管理界面(主机号/ip:8088),点击history

如果无法连接,可以把防火墙关闭,或者修改/etc/sysconfig/iptables,开放我们上面配置的19888端口
-I INPUT -m state --state NEW -m tcp -p tcp --dport 19888 -j ACCEPT
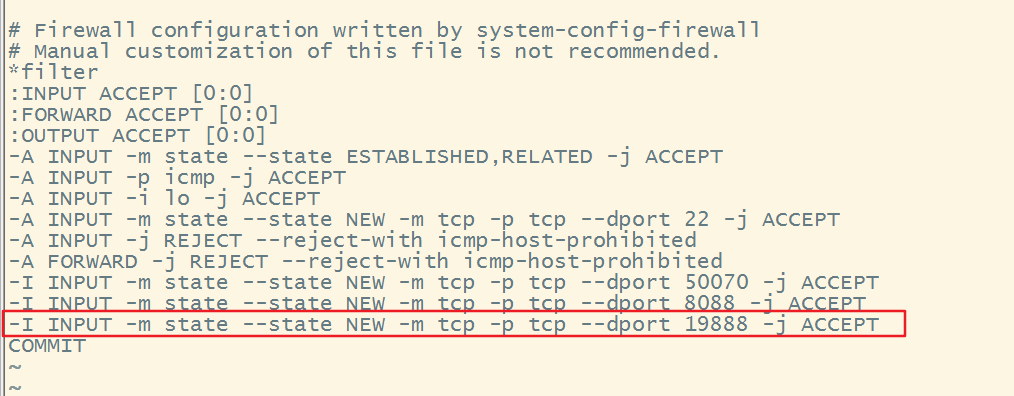
之后重启下防火墙服务sudo service iptables restart,此时就可以访问了

hadoop 3.x 配置历史服务器的更多相关文章
- Hadoop基础-配置历史服务器
Hadoop基础-配置历史服务器 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. Hadoop自带了一个历史服务器,可以通过历史服务器查看已经运行完的Mapreduce作业记录,比 ...
- hadoop配置历史服务器&&配置日志聚集
配置历史服务器 1.在mapred-site.xml中写入一下配置 <property> <name>mapreduce.jobhistory.address</name ...
- hadoop配置历史服务器
此文档不建议当教程,仅供参考 配置历史服务器 我是在hadoop1机器上配置的 配置mapred-site.xml <property> <name>mapreduce.job ...
- hadoop中的Jobhistory历史服务器
1. 启动脚本 mr-jobhistory-daemon.sh start historyserver 2. 配置说明 jobhistory用于查询每个job运行完以后的历史日志信息,是作为一台单独 ...
- Hadoop jobhistory历史服务器
Hadoop自带了一个历史服务器,可以通过历史服务器查看已经运行完的Mapreduce作业记录,比如用了多少个Map.用了多少个Reduce.作业提交时间.作业启动时间.作业完成时间等信息.默认情况下 ...
- 【转载】Hadoop历史服务器详解
免责声明: 本文转自网络文章,转载此文章仅为个人收藏,分享知识,如有侵权,请联系博主进行删除. 原文作者:过往记忆(http://www.iteblog.com/) 原文地址: ...
- Hadoop(一)阿里云hadoop集群配置
集群配置 三台ECS云服务器 配置步骤 1.准备工作 1.1 创建/bigdata目录 mkdir /bigdatacd /bigdatamkdir /app 1.2修改主机名为node01.node ...
- 初识Hadoop一,配置及启动服务
一.Hadoop简介: Hadoop是由Apache基金会所开发的分布式系统基础架构,实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS:Hadoo ...
- [Hadoop入门] - 2 ubuntu安装与配置 hadoop安装与配置
ubuntu安装(这里我就不一一捉图了,只引用一个网址, 相信大家能力) ubuntu安装参考教程: http://jingyan.baidu.com/article/14bd256e0ca52eb ...
随机推荐
- SpringMVC之类型转换Converter
(转载:http://blog.csdn.net/renhui999/article/details/9837897) 1.1 目录 1.1 目录 1.2 前言 1.3 ...
- Qt Creator 源码学习 03:qtcreator.pro
当我们准备好 Qt Creator 的源代码之后,首先进入到它的目录,来看一下它的源代码目录有什么奥秘. 这里一共有 9 个文件夹和 9 个文件.我们来一一看看它们都是干什么用的. .git: 版本控 ...
- Android 快速下载 Android framework 源码
官网 Android framework源码git地址 github: https://github.com/android/platform_frameworks_base google 官方: h ...
- UVA 11584 - Partitioning by Palindromes DP
http://uva.onlinejudge.org/index.php?option=com_onlinejudge&Itemid=8&page=show_problem&p ...
- 11.5 Android显示系统框架_Vsync机制_代码分析
5.5 surfaceflinger对vsync的处理buffer状态图画得不错:http://ju.outofmemory.cn/entry/146313 android设备可能连有多个显示器,AP ...
- Java基础学习总结(51)——JAVA分层理解
service是业务层 action层即作为控制器 DAO (Data Access Object) 数据访问 1.JAVA中Action层, Service层 ,modle层 和 Dao层的功 ...
- Linux下的lds链接脚本简介(二)
七. SECTIONS命令 SECTIONS命令告诉ld如何把输入文件的sections映射到输出文件的各个section: 如何将输入section合为输出section; 如何把输出section ...
- 35、在JZ2440上使用3G上网卡
1. 简单使用:1.1 选型:中国联通:E网时空 EW65 (64元), ZTE中兴 MF637U (160多)中国电信:Benton/本腾 EQ10B (35元)中国移动:华为 ET128 (99元 ...
- https://www.cyberciti.biz/faq/howto-change-rename-user-name-id/
https://www.cyberciti.biz/faq/howto-change-rename-user-name-id/
- JS生成一个种子随机数(伪随机数)
原文链接:https://geniuspeng.github.io/2016/09/12/js-random/ 最近有一个需求,需要生成一个随机数,但是又不能完全随机,就是说需要一个种子seed,se ...