Google三驾马车:GFS、MapReduce和Bigtable
谈到分布式系统,就不得不提Google的三驾马车:Google fs[1],Mapreduce[2],Bigtable[3]。
虽然Google没有公布这三个产品的源码,但是他发布了这三个产品的详细设计论文。而且,Yahoo资助的Hadoop也有按照这三篇论文的开源Java实现:Hadoop对应Mapreduce, Hadoop Distributed File System (HDFS)对应Google fs,Hbase对应Bigtable。不过在性能上Hadoop比Google要差很多,参见表1。
|
Experiment |
HBase20070916 |
BigTable |
|
random reads |
272 |
1212 |
|
random reads (mem) |
Not implemented |
10811 |
|
random writes |
1460 |
8850 |
|
sequential reads |
267 |
4425 |
|
sequential writes |
1278 |
8547 |
|
Scans |
3692 |
15385 |
表1。Hbase和BigTable性能比较(来源于http://wiki.apache.org/lucene-hadoop/Hbase/PerformanceEvaluation)
以下分别介绍这三个产品:
Google fs
GFS是一个可扩展的分布式文件系统,用于大型的、分布式的、对大量数据进行访问的应用。它运行于廉价的普通硬件上,提供容错功能
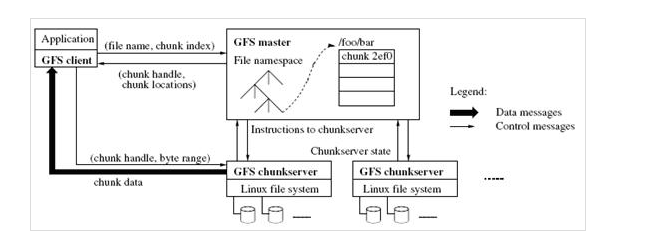
图1 GFS Architecture
(1)GFS的结构
1. GFS的结构图见图1,由一个master和大量的chunkserver构成,
2. 不像Amazon Dynamo的没有主的设计,Google设置一个主来保存目录和索引信息,这是为了简化系统结果,提高性能来考虑的,但是这就会造成主成为单点故障或者瓶颈。为了消除主的单点故障Google把每个chunk设置的很大(64M),这样,由于代码访问数据的本地性,application端和master的交互会减少,而主要数据流量都是Application和chunkserver之间的访问。
3. 另外,master所有信息都存储在内存里,启动时信息从chunkserver中获取。提高了master的性能和吞吐量,也有利于master当掉后,很容易把后备j机器切换成master。
4. 客户端和chunkserver都不对文件数据单独做缓存,只是用linux文件系统自己的缓存
“The master stores three major types of metadata: the file and chunk namespaces, the mapping from files to chunks, and the locations of each chunk’s replicas.”
“Having a single master vastly simplifies our design and enables the master to make sophisticated chunk placement and replication decisions using global knowledge. However,we must minimize its involvement in reads and writes so that it does not become a bottleneck. Clients never read and write file data through the master. Instead, a client asks the master which chunkservers it should contact. It caches this information for a limited time and interacts with the chunkservers directly for many subsequent operations.”
“Neither the client nor the chunkserver caches file data.Client caches offer little benefit because most applications stream through huge files or have working sets too large to be cached. Not having them simplifies the client and the overall system by eliminating cache coherence issues.(Clients do cache metadata, however.) Chunkservers need not cache file data because chunks are stored as local files and so Linux’s buffer cache already keeps frequently accessed data in memory.”
(2)GFS的复制
GFS典型的复制到3台机器上,参看图2
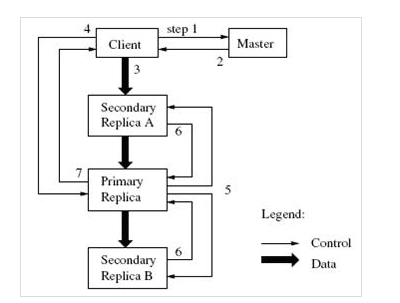
图2 一次写操作的控制流和数据流
(3) 对外的接口
和文件系统类似,GFS对外提供create, delete,open, close, read, 和 write 操作。另外,GFS还新增了两个接口snapshot and record append,snapshot。有关snapshot的解释:
“Moreover, GFS has snapshot and record append operations. Snapshot creates a copy of a file or a directory tree at low cost.
Record append allows multiple clients to append data to the same file concurrently while guaranteeing the atomicity of each individual client’s append.”
2. MapReduce
MapReduce是针对分布式并行计算的一套编程模型。
讲到并行计算,就不能不谈到微软的Herb Sutter在2005年发表的文章” The Free Lunch Is Over: A Fundamental Turn Toward Concurrency in Software”[6],主要意思是通过提高cpu主频的方式来提高程序的性能很快就要过去了,cpu的设计方向也主要是多核,超线程等并发上。但是以前的程序并不能自动的得到多核的好处,只有编写并发程序,才能真正获得多核的好处。分布式计算也是一样。
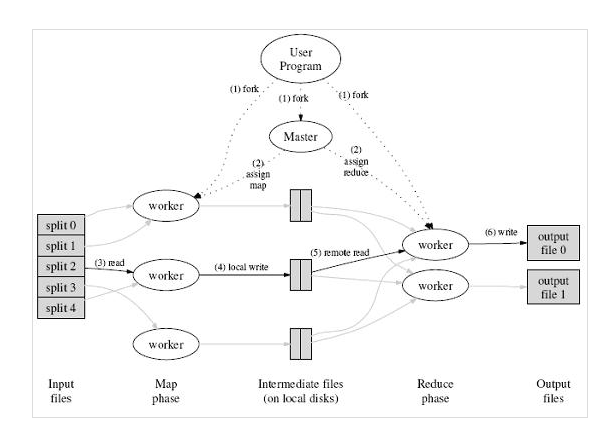
图3 MapReduce Execution overview
1)MapReduce是由Map和reduce组成,来自于Lisp,Map是影射,把指令分发到多个worker上去,Reduce是规约,把Map的worker计算出来的结果合并。(参见图3)
2)Google的MapReduce实现使用GFS存储数据。
3)MapReduce可用于Distributed Grep,Count of URL Access Frequency,ReverseWeb-Link Graph,Distributed Sort,Inverted Index
3. Bigtable
就像文件系统需要数据库来存储结构化数据一样,GFS也需要Bigtable来存储结构化数据。
1)BigTable 是建立在 GFS ,Scheduler ,Lock Service 和 MapReduce 之上的。
2)每个Table都是一个多维的稀疏图
3)为了管理巨大的Table,把Table根据行分割,这些分割后的数据统称为:Tablets。每个Tablets大概有 100-200 MB,每个机器存储100个左右的 Tablets。底层的架构是:GFS。由于GFS是一种分布式的文件系统,采用Tablets的机制后,可以获得很好的负载均衡。比如:可以把经常响应的表移动到其他空闲机器上,然后快速重建。
参考文献
[1]The Google File System; http://labs.google.com/papers/gfs-sosp2003.pdf
[2]MapReduce: Simplifed Data Processing on Large Clusters; http://labs.google.com/papers/mapreduce-osdi04.pdf
[3]Bigtable: A Distributed Storage System for Structured Data;http://labs.google.com/papers/bigtable-osdi06.pdf
[4]Hadoop ; http://lucene.apache.org/hadoop/
[5]Hbase: Bigtable-like structured storage for Hadoop HDFS;http://wiki.apache.org/lucene-hadoop/Hbase
[6]The Free Lunch Is Over: A Fundamental Turn Toward Concurrency in Software;http://www.gotw.ca/publications/concurrency-ddj.htm
Google三驾马车:GFS、MapReduce和Bigtable的更多相关文章
- 分布式系统漫谈一 —— Google三驾马车: GFS,mapreduce,Bigtable
分布式系统学习必读文章!!!! 原文:http://blog.sina.com.cn/s/blog_4ed630e801000bi3.html 分布式系统漫谈一 —— Google三驾马车: GFS, ...
- Google三驾马车
Google旧三驾马车: GFS,mapreduce,Bigtable http://blog.sina.com.cn/s/blog_4ed630e801000bi3.html Google新三驾马车 ...
- [MapReduce] Google三驾马车:GFS、MapReduce和Bigtable
声明:此文转载自博客开发团队的博客,尊重原创工作.该文适合学分布式系统之前,作为背景介绍来读. 谈到分布式系统,就不得不提Google的三驾马车:Google FS[1],MapReduce[2],B ...
- 【技术与商业案例解读笔记】095:Google大数据三驾马车笔记
1.谷歌三驾马车地位 [关键词]开启时代,指明方向 聊起大数据,我们通常言必称谷歌,谷歌有“三驾马车”:谷歌文件系统(GFS).MapReduce和BigTable.谷歌的“三驾马车”开启了大数据时 ...
- Childlife旗下三驾马车
Childlife旗下,尤其以 “提高免疫力”为口号的“三驾马车”:第一防御液.VC.紫雏菊,是相当热门的海淘产品.据说这是一系列“成分天然.有效治愈感冒提升免疫力.由美国著名儿科医生研发”的药物.
- Ubuntu 安装 k8s 三驾马车 kubelet kubeadm kubectl
Ubuntu 版本是 18.04 ,用的是阿里云服务器,记录一下自己实际安装过程的操作步骤. 安装 docker 安装所需的软件 apt-get update apt-get install -y a ...
- 更强、更稳、更高效:解读 etcd 技术升级的三驾马车
点击下载<不一样的 双11 技术:阿里巴巴经济体云原生实践> 本文节选自<不一样的 双11 技术:阿里巴巴经济体云原生实践>一书,点击上方图片即可下载! 作者 | 陈星宇(宇慕 ...
- Google 云计算中的 GFS 体系结构
google 公司的很多业务具有数据量巨大的特点,为此,google 公司研发了云计算技术.google 云计 算结构中的 google 文件系统是其云计算技术中的三大法宝之一.本文主要介 ...
- Google的三大马车
Google的三大马车Google fs + Map Reduce + Big Table 开源Java实现HDFS Hadoop Hbase 云盘实现用廉价的服务器提供与万级的数据库存储①廉价的服务 ...
随机推荐
- 集装箱set相关算法
set_union 算法set_union可构造S1.S2的并集.此集合内含S1或S2内的每个元素. S1.S2及其并集都是以排序区间表示.返回值是一个迭代器.指向输出区间的尾端. 因为S1和S ...
- 分位数和分位线(Quantiles and Percentiles)
分位数有种积分(累积)的含义在. 分位数(即将数据由低至高排列,小于该数的数据占总体的比例达到时最终落到的数): 10%:3000元 20%:5200元 50%:20000元 80%:41500元 9 ...
- vmware tools 的安装(Read-only file system 的解决)
安装 vmware tools 之后,才能将 vmware 创建的虚拟机以全屏的形式显示. 下载:在 vmware 软件的菜单栏点击[虚拟机],在[虚拟机]的主菜单中选择[安装 VMware Tool ...
- .net命名空间和程序集详解
命名空间是一种用于将逻辑上相似的类按层次结构分组的机制.这种机制防止了命名冲突.在这种结构化采用被点号"."分隔的单词来实现.通常最顶层的命名空间是System,例如System; ...
- WPF的两棵树与绑定
原文:WPF的两棵树与绑定 先建立测试基类 public class VisualPanel : FrameworkElement { protected VisualCollection Chi ...
- 11991 - Easy Problem from Rujia Liu?(的基础数据结构)
UVA 11991 - Easy Problem from Rujia Liu? 题目链接 题意:给一个长度n的序列,有m询问,每一个询问会问第k个出现的数字的下标是多少 思路:用map和vector ...
- 在vs code中使用dotnet watch run
只需要在csproj文件中加入一行: <ItemGroup> <PackageReference Include="Microsoft.AspNetCore.App&quo ...
- 编译wxWidgets —— windows、vc71、bcc32、MinGW与命令行
编译wxWidgets —— windows.vc71.bcc32.MinGW与命令行 http://www.diybl.com/course/3_program/vc/vc_js/20071226/ ...
- strlen, wcslen, _mbslen, _mbslen_l, _mbstrlen, _mbstrlen_l, setlocale(LC_CTYPE, "Japanese_Japan")(MSDN的官方示例)
// crt_strlen.c // Determine the length of a string. For the multi-byte character // example to work ...
- 读BeautifulSoup官方文档之html树的打印
prettify()能返回一个格式良好的html的Unicode字符串 : markup = '<a href="http://example.com/">I link ...