MySQL(八)哈希索引、AVL树、B树与B+树的比较
Hash索引
简介
这部分略了
Hash索引效率高,为什么还要设计索引结构为树形结构?
- Hash索引仅能满足 =、<>和IN查询,如果进行
范围查询,哈希的索引会退化成O(n);而树型的有序特性,仍然能够保持O(log2n)的效率 - Hash索引存储的数据是没有顺序的,如果使用order by语句,还需要对索引重新排序
- 对于联合索引的情况,哈希需要计算两个索引列合并和哈希值,这样就无法针对单个索引进行查询
- 对于等值查询,如果索引列的重复度较高,则哈希的效率也会降低,这是由于哈希发生冲突的可能性高,当遇到冲突的时候,需要遍历桶中的行指针来进行比较,找到查询的关键字,非常耗时。比如,列为年龄或者性别的情况就不适合建立哈希索引
Hash索引的适用性
在一些键值数据库都应用较多,如Redis
InnoDB和MyISAM都不支持Hash索引,只有Memory存储引擎支持,Memory存储引擎在把某个字段设置为Hash索引的时候,通过Hash计算可以进行缩短。
当键值的重复读较低,并且多为等值查询的时候,Hash索引较为适用
InnoDB虽然不支持哈希索引,但是提供了一个
自适应哈希索引,是指对于一些字段的等值查询达到一定的条件的时候,会为这个字段添加自适应哈希索引,再次查询的时候就不需要通过树型索引去获取记录,相当于一个查询缓存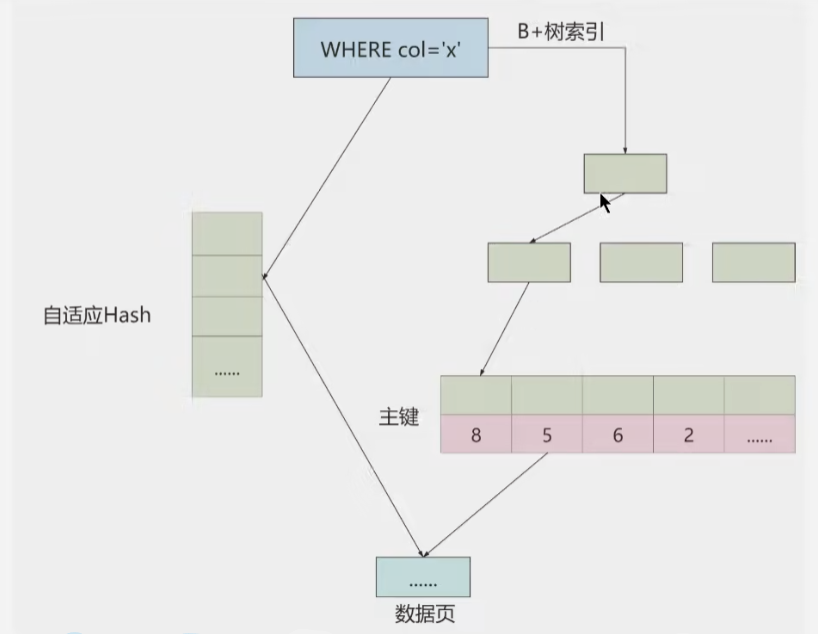
可以通过adaptive_hash_index变量查看是否开启了自适应Hash
mysql> show variables like '%adaptive_hash_index'
-> ;
+----------------------------+-------+
| Variable_name | Value |
+----------------------------+-------+
| innodb_adaptive_hash_index | ON |
+----------------------------+-------+
1 row in set (0.01 sec)
AVL
数据结构就不多介绍了,就是平衡因子为-1 0 1 的二叉搜索树,目的是为了降低平均查找的路径长度

B-Tree
B-Tree即多路平衡查找树,进一步降低了平衡二叉树的树高度
- B树的节点最多有M个子节点,M称作是B树的
阶 - 每个节点中存放着
关键字和子节点的指针,关键字升序排列 - 一个M阶的B树的特性有:
- 根节点的子节点范围为[2,M]
- 每个中间节点包含k个子节点和k-1个关键字,k的范围为[ceil(M/2), M]
- 叶子节点都在同一层
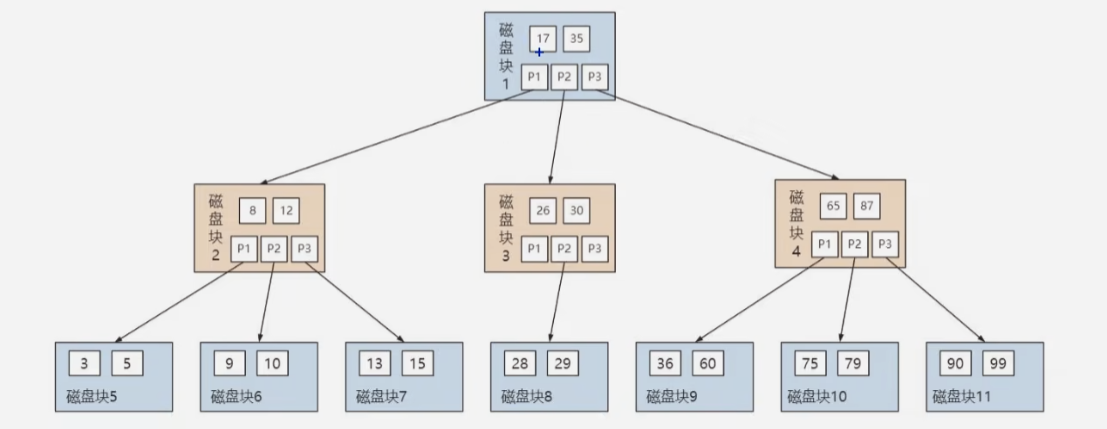
假设想查找关键字9,则依次会查找磁盘块1、2、6最终找到9
小结
- B树在插入或者删除节点导致的页分裂和合并的不平衡,会通过自动调整节点的位置来保持树的平衡
- 关键字分布在整棵树中,即叶子节点和非叶子节点中都存放着数据,查找可能在非叶子节点结束
- 其搜索性能相当于在整个关键字全集中做一次二分查找
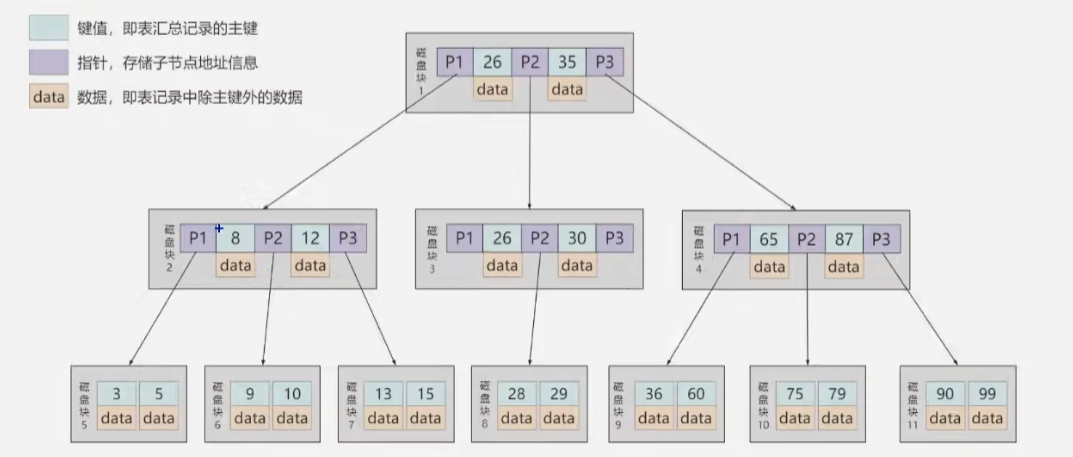
B+Tree
B+Tree也是一种多路搜索树,基于B+Tree进行了改进,主流的DBMS都支持B+树的索引方式,B+树更适合文件系统。
1 和B-Tree的差异
- 有K个孩子就有K个关键字,即孩子数量等于关键字数量
- 非叶子节点存放的是孩子节点关键字的最大值
- 非叶子节点仅仅用于索引,不保存数据记录,所有的数据记录都保存在叶子结点中
- 所有关键字都保存在叶子节点中,页内的关键字以单链表形式链接,页之间以双向链表方式进行链接
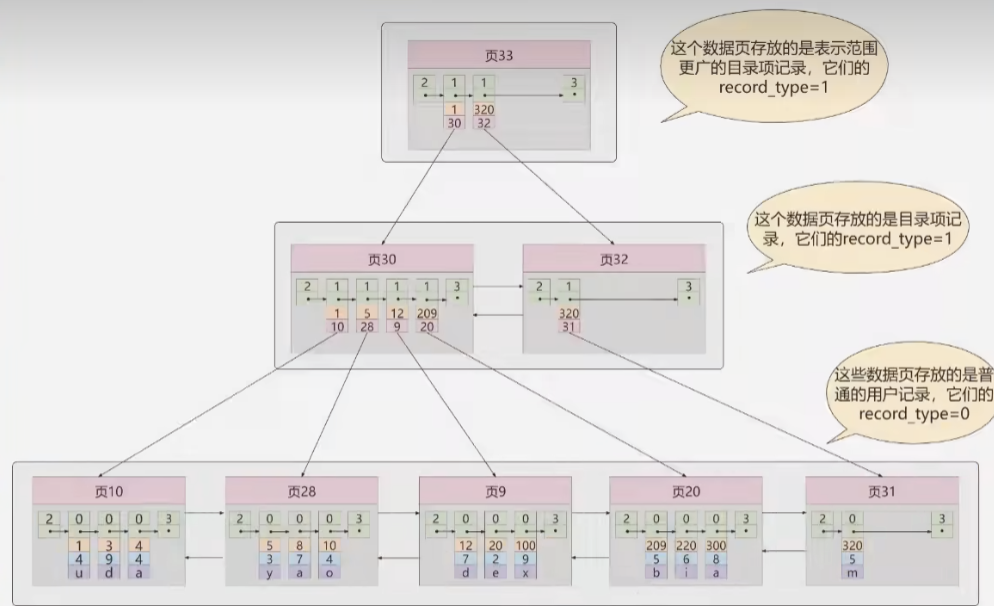
2 B+树的中间节点不存放数据的优点?
- 查询效率更加稳定:B树有时访问非叶子节点就找到关键字,而有时需要访问到叶子节点才能,而B+树只有访问到叶子节点才能访问到关键字,比较稳定
- 查询效率更高:B+树比B树更加矮胖(阶数更大,深度更低),这是因为B+树的中间节点不存放数据,因此一个页能够存放更多的关键字
- 不仅在对单个关键字的查询,在查询范围上,B+树的效率也要比B树高。这是因为B+树的叶子节点的数据通过链表连接,范围查询可以直接通过指针查找,而B树需要通过中序遍历完成范围查找,效率较低。
3 为了减少IO,索引树会一次加载吗
- 数据库索引是存放在磁盘上的,数据文件很大的时候,索引也会很大,甚至超过几个G
- 在利用索引进行查询的时候,只是逐一加载每一个磁盘页,因为磁盘页对应索引树的节点
4 B+树的存储能力如何,为什么说一般查找行记录,最多需要1-3次IO
InnoDB的页的大小为16kb,一般表的主键为int(4个字节)或者bigInt(8个字节),指针类型也为4-8个字节,也就是说一个页中大概存储16kb/(8B+8B)=1k个键值,则三层索引对应10^9,即1亿条数据
一般情况下每个节点可能不能填满,因此在数据库中B+Tree的高度一般是2-4层,MySQL一般将表的根节点常驻内存,因此一般需要1-3次磁盘IO查找数据。
5 为什么说B+树比B-树更适合实际应用中操作系统的文件搜素和数据库索引
- B+树的磁盘读写代价更低:B+树的节点内部没有实际指向关键字具体信息的指针,因此页容纳的关键字的个数也就更多,一次性读入内存中需要查找的关键字也就更多,相对来说磁盘的IO也就较小
- B+树的查询效率更加稳定:B树有时访问非叶子节点就找到关键字,而有时需要访问到叶子节点才能,而B+树只有访问到叶子节点才能访问到关键字,比较稳定
6 Hash索引与B+树索引的区别
- Hash索引不能进行
范围查询,Hash索引指向的数据是无序的,而B+树索引的叶子节点是个有序的链表 - Hash索引不支持联合索引的最左侧原则(即联合索引的部分索引无法使用),Hash索引会将索引键联合后一起计算Hash值,所以无法利用部分索引进行查询
- Hash索引不支持
Order by排序,Hash索引指向的数据是无序的;同时也不支持模糊查询 - InnoDB不支持哈希索引
Hash索引和B+树索引是在建立索引的时候手动指定的吗
- InnoDB和MyISAM存储引擎会默认采用B+树存储引擎,无法使用哈希索引
- InnoDB使用自适应哈希不需要手动指定,Memory引擎可以手动指定Hash索引
MySQL(八)哈希索引、AVL树、B树与B+树的比较的更多相关文章
- MySql 自适应哈希索引
一.介绍 哈希(hash)是一种非常快的查找方法,一般情况下查找的时间复杂度为O(1).常用于连接(join)操作,如Oracle中的哈希连接(hash join). InnoDB存储引擎会监控对表上 ...
- [日常] MySQL的哈希索引和原理研究测试
1.哈希索引 :(hash index)基于哈希表实现,只有精确匹配到索引列的查询,才会起到效果.对于每一行数据,存储引擎都会对所有的索引列计算出一个哈希码(hash code),哈希码是一个较小的整 ...
- B+树索引和哈希索引的区别——我在想全文搜索引擎为啥不用hash索引而非得使用B+呢?
哈希文件也称为散列文件,是利用哈希存储方式组织的文件,亦称为直接存取文件.它类似于哈希表,即根据文件中关键字的特点,设计一个哈希函数和处理冲突的方法,将记录哈希到存储设备上. 在哈希文件中,是使用一个 ...
- mysql性能优化之索引优化
作为免费又高效的数据库,mysql基本是首选.良好的安全连接,自带查询解析.sql语句优化,使用读写锁(细化到行).事物隔离和多版本并发控制提高并发,完备的事务日志记录,强大的存储引擎提供高效查询(表 ...
- MySQL B+树索引和哈希索引的区别
导读 在MySQL里常用的索引数据结构有B+树索引和哈希索引两种,我们来看下这两种索引数据结构的区别及其不同的应用建议. 二者区别 备注:先说下,在MySQL文档里,实际上是把B+树索引写成了BT ...
- MySQL B+树索引和哈希索引的区别(转 JD二面)
导读 在MySQL里常用的索引数据结构有B+树索引和哈希索引两种,我们来看下这两种索引数据结构的区别及其不同的应用建议. 二者区别 备注:先说下,在MySQL文档里,实际上是把B+树索引写成了BTRE ...
- mysql索引之一:索引基础(B-Tree索引、哈希索引、聚簇索引、全文(Full-text)索引区别)(唯一索引、最左前缀索引、前缀索引、多列索引)
没有索引时mysql是如何查询到数据的 索引对查询的速度有着至关重要的影响,理解索引也是进行数据库性能调优的起点.考虑如下情况,假设数据库中一个表有10^6条记录,DBMS的页面大小为4K,并存储10 ...
- MySQL中的自适应哈希索引
众所周知,InnoDB使用的索引结构是B+树,但其实它还支持另一种索引:自适应哈希索引. 哈希表是数组+链表的形式.通过哈希函数计算每个节点数据中键所对应的哈希桶位置,如果出现哈希冲突,就使用拉链法来 ...
- B+树索引和哈希索引的区别[转]
导读 在MySQL里常用的索引数据结构有B+树索引和哈希索引两种,我们来看下这两种索引数据结构的区别及其不同的应用建议. 二者区别 备注:先说下,在MySQL文档里,实际上是把B+树索引写成了BTRE ...
- B+树索引和哈希索引的明显区别是:
如果是等值查询,那么哈希索引明显有绝对优势,因为只需要经过一次算法即可找到相应的键值:当然了,这个前提是,键值都是唯一的.如果键值不是唯一的,就需要先找到该键所在位置,然后再根据链表往后扫描,直到找到 ...
随机推荐
- Java中int型数据类型对应MySQL数据库中哪种类型?
java类 mysql数据库 java.lang.Byte byte TINYINT java.lang.Short short SMALLINT java.lang.Integer intege ...
- Spring 笔记三 AOP
1.AOP 概述 AOP (Aspect-Oriented Programming,面向切面编程):是一种新的方法论,是对传统 OOP (Object-Oriented Programming,面 ...
- 盒子模型和CSS背景和列表
盒子模型(1)宽度-width:长度值 | 百分比 | auto-max-width:长度值 | 百分比 | auto-min-width:长度值 | 百分比 | auto(2)高度-height:长 ...
- mysql知识点二
1.mysql中的语言有哪些?分别代表什么意思1.DDL(Data Define Language) 数据定义语言2.DML(Data Manipulation Language) 数据操作语言3.D ...
- oracle数据库常用操作
1,调整显示格式 col username for a20 col DEFAULT_TABLESPACE for a30 2,查看表空间 select username,default_tablesp ...
- 安装mysql8.0
安装repo源 参考mysql官方文档 参考文章 redhat7通过yum安装mysql5.7.17教程:https://www.jb51.net/article/103676.htm mysql r ...
- springboot + mybatisplus出现was not registered for synchronization because synchronization is not active
原因一:缺少事务注解,底层mybatisplus的接口方法有事务 原因二:该服务器被限制访问要连接的数据库 原因三:乐观锁失效 乐观锁由@version注解标注,有以下使用要求 支持的数据类型只有:i ...
- U-Boot 常用命令介绍
U-Boot简介 U-Boot常用命令 帮助类 - help/?:该命令输出u-boot支持的所有命令及命令的功能 - help/? cmd:可以查看相应cmd的详细介绍及使用方法 查询类 - bdi ...
- k8sdeploy配置文件示例
apiVersion: extensions/v1beta1 kind: Deployment metadata: name: [k8s服务名] namespace: default labels: ...
- 使用float进行比较问题处理
float compare Abstract 使用float数据进行精确计算和比较,可能由于精度问题导致程序逻辑异常. Explanation 使用float数据进行比较,计算机表达double和fl ...