大数据-业务数据采集-FlinkCDC 读取 MySQL 数据存入 Kafka
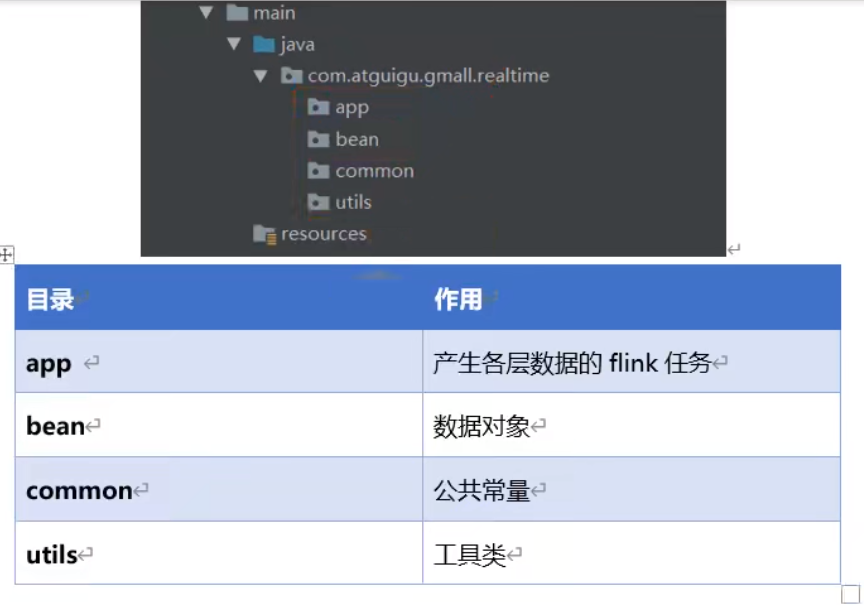
| 目录 | 作用 |
|---|---|
| app | 产生各层数据的 flink 任务 |
| bean | 数据对象 |
| common | 公共常量 |
| utils | 工具类 |
app.ods.FlinkCDC.java
package com.atguigu.app.ods;
import com.alibaba.ververica.cdc.connectors.mysql.MySQLSource;
import com.alibaba.ververica.cdc.connectors.mysql.table.StartupOptions;
import com.alibaba.ververica.cdc.debezium.DebeziumSourceFunction;
import com.atguigu.app.function.CustomerDeserialization;
import com.atguigu.utils.MyKafkaUtil;
import org.apache.flink.runtime.state.filesystem.FsStateBackend;
import org.apache.flink.streaming.api.CheckpointingMode;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class FlinkCDC {
public static void main(String[] args) throws Exception {
//1.获取执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
//1.1 设置CK&状态后端
//env.setStateBackend(new FsStateBackend("hdfs://hadoop102:8020/gmall-flink-210325/ck"));
//env.enableCheckpointing(5000L);
//env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
//env.getCheckpointConfig().setCheckpointTimeout(10000L);
//env.getCheckpointConfig().setMaxConcurrentCheckpoints(2);
//env.getCheckpointConfig().setMinPauseBetweenCheckpoints(3000);
//env.setRestartStrategy(RestartStrategies.fixedDelayRestart());
//2.通过FlinkCDC构建SourceFunction并读取数据
DebeziumSourceFunction<String> sourceFunction = MySQLSource.<String>builder()
.hostname("hadoop102")
.port(3306)
.username("root")
.password("000000")
.databaseList("gmall-210325-flink")
.deserializer(new CustomerDeserialization())
.startupOptions(StartupOptions.latest())
.build();
DataStreamSource<String> streamSource = env.addSource(sourceFunction);
//3.打印数据并将数据写入Kafka
streamSource.print();
String sinkTopic = "ods_base_db";
streamSource.addSink(MyKafkaUtil.getKafkaProducer(sinkTopic));
//4.启动任务
env.execute("FlinkCDC");
}
}
CustomerDeserialization
package com.atguigu.app.function;
import com.alibaba.fastjson.JSONObject;
import com.alibaba.ververica.cdc.debezium.DebeziumDeserializationSchema;
import io.debezium.data.Envelope;
import org.apache.flink.api.common.typeinfo.BasicTypeInfo;
import org.apache.flink.api.common.typeinfo.TypeInformation;
import org.apache.flink.util.Collector;
import org.apache.kafka.connect.data.Field;
import org.apache.kafka.connect.data.Schema;
import org.apache.kafka.connect.data.Struct;
import org.apache.kafka.connect.source.SourceRecord;
import java.util.List;
public class CustomerDeserialization implements DebeziumDeserializationSchema<String> {
/**
* 封装的数据格式
* {
* "database":"",
* "tableName":"",
* "before":{"id":"","tm_name":""....},
* "after":{"id":"","tm_name":""....},
* "type":"c u d",
* //"ts":156456135615
* }
*/
@Override
public void deserialize(SourceRecord sourceRecord, Collector<String> collector) throws Exception {
//1.创建JSON对象用于存储最终数据
JSONObject result = new JSONObject();
//2.获取库名&表名
String topic = sourceRecord.topic();
String[] fields = topic.split("\\.");
String database = fields[1];
String tableName = fields[2];
Struct value = (Struct) sourceRecord.value();
//3.获取"before"数据
Struct before = value.getStruct("before");
JSONObject beforeJson = new JSONObject();
if (before != null) {
Schema beforeSchema = before.schema();
List<Field> beforeFields = beforeSchema.fields();
for (Field field : beforeFields) {
Object beforeValue = before.get(field);
beforeJson.put(field.name(), beforeValue);
}
}
//4.获取"after"数据
Struct after = value.getStruct("after");
JSONObject afterJson = new JSONObject();
if (after != null) {
Schema afterSchema = after.schema();
List<Field> afterFields = afterSchema.fields();
for (Field field : afterFields) {
Object afterValue = after.get(field);
afterJson.put(field.name(), afterValue);
}
}
//5.获取操作类型 CREATE UPDATE DELETE
Envelope.Operation operation = Envelope.operationFor(sourceRecord);
String type = operation.toString().toLowerCase();
if ("create".equals(type)) {
type = "insert";
}
//6.将字段写入JSON对象
result.put("database", database);
result.put("tableName", tableName);
result.put("before", beforeJson);
result.put("after", afterJson);
result.put("type", type);
//7.输出数据
collector.collect(result.toJSONString());
}
@Override
public TypeInformation<String> getProducedType() {
return BasicTypeInfo.STRING_TYPE_INFO;
}
}
MyKafkaUtil
package com.atguigu.utils;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer;
import org.apache.flink.streaming.connectors.kafka.KafkaSerializationSchema;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import javax.annotation.Nullable;
import java.util.Properties;
public class MyKafkaUtil {
private static String brokers = "hadoop102:9092,hadoop103:9092,hadoop104:9092";
private static String default_topic = "DWD_DEFAULT_TOPIC";
public static FlinkKafkaProducer<String> getKafkaProducer(String topic) {
return new FlinkKafkaProducer<String>(brokers,
topic,
new SimpleStringSchema());
}
public static <T> FlinkKafkaProducer<T> getKafkaProducer(KafkaSerializationSchema<T> kafkaSerializationSchema) {
Properties properties = new Properties();
properties.setProperty(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, brokers);
return new FlinkKafkaProducer<T>(default_topic,
kafkaSerializationSchema,
properties,
FlinkKafkaProducer.Semantic.EXACTLY_ONCE);
}
public static FlinkKafkaConsumer<String> getKafkaConsumer(String topic, String groupId) {
Properties properties = new Properties();
properties.put(ConsumerConfig.GROUP_ID_CONFIG, groupId);
properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, brokers);
return new FlinkKafkaConsumer<String>(topic,
new SimpleStringSchema(),
properties);
}
//拼接Kafka相关属性到DDL
public static String getKafkaDDL(String topic, String groupId) {
return " 'connector' = 'kafka', " +
" 'topic' = '" + topic + "'," +
" 'properties.bootstrap.servers' = '" + brokers + "', " +
" 'properties.group.id' = '" + groupId + "', " +
" 'format' = 'json', " +
" 'scan.startup.mode' = 'latest-offset' ";
}
}
尚硅谷 源代码
https://gitee.com/wh-alex/gmall-flink-210325
大数据-业务数据采集-FlinkCDC 读取 MySQL 数据存入 Kafka的更多相关文章
- 大数据-业务数据采集-FlinkCDC
CDC CDC 是 Change Data Capture(变更数据获取)的简称.核心思想是,监测并捕获数据库的变动(包括数据或数据表的插入.更新以及删除等),将这些变更按发生的顺序完整记录下来,写入 ...
- Web自动化框架之五一套完整demo的点点滴滴(excel功能案例参数化+业务功能分层设计+mysql数据存储封装+截图+日志+测试报告+对接缺陷管理系统+自动编译部署环境+自动验证false、error案例)
标题很大,想说的很多,不知道从那开始~~直接步入正题吧 个人也是由于公司的人员的现状和项目的特殊情况,今年年中后开始折腾web自动化这块:整这个原因很简单,就是想能让自己偷点懒.也让减轻一点同事的苦力 ...
- Spark使用Java读取mysql数据和保存数据到mysql
原文引自:http://blog.csdn.net/fengzhimohan/article/details/78471952 项目应用需要利用Spark读取mysql数据进行数据分析,然后将分析结果 ...
- flink-cdc同步mysql数据到hive
本文首发于我的个人博客网站 等待下一个秋-Flink 什么是CDC? CDC是(Change Data Capture 变更数据获取)的简称.核心思想是,监测并捕获数据库的变动(包括数据 或 数据表的 ...
- 关于C#读取MySql数据时,返回DataTable中某字段数据是System.Array[]形式
我在使用C#(VS2008)读取MySql数据库(5.1版本)时,返回的DataTable数据中arrivalDate字段数据显示为System.Array[]形式(程序中没有对返回的数据进行任何加工 ...
- Spark:读取mysql数据作为DataFrame
在日常工作中,有时候需要读取mysql的数据作为DataFrame数据源进行后期的Spark处理,Spark自带了一些方法供我们使用,读取mysql我们可以直接使用表的结构信息,而不需要自己再去定义每 ...
- Django读取Mysql数据并显示在前端
一.首先按添加网页的步骤添加网页,我的网页名为table.html, app名为web table.html放到相应目录下, froms文件提前写好 修改views.py ? 1 2 3 4 5 6 ...
- R语言读取MySQL数据表
1.R中安装RODBC包 install.packages("RODBC") 2.在Windows系统下安装MySQL的ODBC驱动 注意区分32位和64位版本: http://d ...
- Flume-自定义 Source 读取 MySQL 数据
开源实现:https://github.com/keedio/flume-ng-sql-source 这里记录的是自己手动实现. 测试中要读取的表 CREATE TABLE `student` ( ` ...
- wcf序列化大对象时报错:读取 XML 数据时,超出最大
错误为: 访问服务异常:格式化程序尝试对消息反序列化时引发异常: 尝试对参数 http://tempuri.org/ 进行反序列化时出 错: request.InnerException 消息是“反序 ...
随机推荐
- AtCoder Beginner Contest 240 F - Sum Sum Max
原题链接F - Sum Sum Max 首先令\(z_i = \sum\limits_{k = 1}^i y_k\),\(z_0 = 0\),\(z_i\)就是第\(i\)段相同的个数的前缀和. 对于 ...
- 这些新项目一定不要错过「GitHub 热点速览」
本周 GitHub 热点上榜的项目有不少的新面孔,比如搞电子商务的 eShop,还有处理表数据的 onetable.还有用来方便处理数据同步问题的 loro,以及网易新开源的 tts 项目 Emoti ...
- 手撕Vue-Router-提取路由信息
前言 好了经过上一篇的学习,我们已经知道了如何监听 Hash 的变化,如何监听路径的一个变化,本篇我们就可以来实现我们自己的 VueRouter 了, 那么怎么实现呢,在实现之前我们先来回顾一下官方的 ...
- 文心一言 VS 讯飞星火 VS chatgpt (140)-- 算法导论11.4 5题
五.用go语言,考虑一个装载因子为a的开放寻址散列表.找出一个非零的a值,使得一次不成功查找的探查期望数是一次成功查找的探查期望数的 2 倍.这两个探查期望数可以使用定理11.6 和定理 11.8 中 ...
- 在ASP.NET Core 中使用 .NET Aspire 消息传递组件
前言 云原生应用程序通常需要可扩展的消息传递解决方案,以提供消息队列.主题和订阅等功能..NET Aspire 组件简化了连接到各种消息传递提供程序(例如 Azure 服务总线)的过程.在本教程中,小 ...
- Google Colab 现已支持直接使用 🤗 transformers 库
Google Colab,全称 Colaboratory,是 Google Research 团队开发的一款产品.在 Colab 中,任何人都可以通过浏览器编写和执行任意 Python 代码.它尤其适 ...
- [ABC261A] Intersection
Problem Statement We have a number line. Takahashi painted some parts of this line, as follows: Firs ...
- Apache POI 操作Excel简单入门使用
Apache POI简介 开发中经常会涉及到excel的处理,如导出Excel,导入Excel到数据库中,操作Excel目前有两个框架,一个是apache 的poi, 另一个是 Java Excel ...
- 如何 使 Java、C# md5 加密的值保持一致
Java C# md5 加密值保持一致,一般是编码不一致造成的值不同 JAVA (加密:123456) C#(加密:123456) UTF-8 e10adc3949ba59abbe56e057f20f ...
- Linux 485驱动通信异常
背景 前段时间接到一个项目,要求用主控用485和MCU通信.将代码调试好之后,验证没问题就发给测试了.测试测的也没问题. 但是,到设备量产时,发现有几台设备功能异常.将设备拿回来排查,发现是485通信 ...