从RDD创建DataFrame
0.前次作业:从文件创建DataFrame
1.pandas df 与 spark df的相互转换 df_s=spark.createDataFrame(df_p) df_p=df_s.toPandas()
# 从数组创建pandas dataframe
import pandas as pd
import numpy as np
arr = np.arange(6).reshape(-1,3)
arr
df_p = pd.DataFrame(arr)
df_p
df_p.columns = ['a','b','c']
df_p

# pandas df 转为spark df
df_s = spark.createDataFrame(df_p)
df_s.show()
df_s.collect()

# spark df 转为pandas df
df_s.show()
df_s.toPandas()

2. Spark与Pandas中DataFrame对比
http://www.lining0806.com/spark%E4%B8%8Epandas%E4%B8%ADdataframe%E5%AF%B9%E6%AF%94/
3.1 利用反射机制推断RDD模式
- sc创建RDD
spark.sparkContext.textFile("file:///D:/Spark/spark-2.4.7-bin-hadoop2.7/examples/src/main/resources/people.txt").first()
spark.sparkContext.textFile("file:///D:/Spark/spark-2.4.7-bin-hadoop2.7/examples/src/main/resources/people.txt")\
.map(lambda line:line.split(',')).first()

- 转换成Row元素,列名=值
from pyspark.sql import Row
people = spark.sparkContext.textFile("file:///D:/Spark/spark-2.4.7-bin-hadoop2.7/examples/src/main/resources/people.txt")\
.map(lambda line:line.split(','))\
.map(lambda p:Row(name=p[0],age=int(p[1])))
- spark.createDataFrame生成df
schemaPeople = spark.createDataFrame(people)
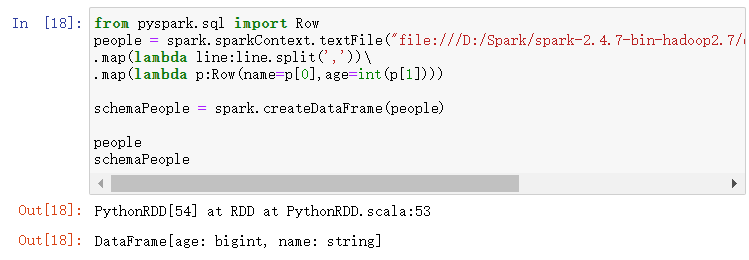
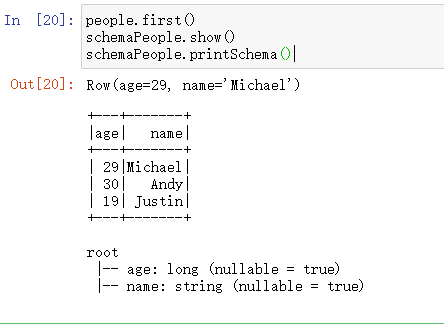
- df.show(), df.printSchema()
schemaPeople.show()
schemaPeople.printSchema()
3.2 使用编程方式定义RDD模式
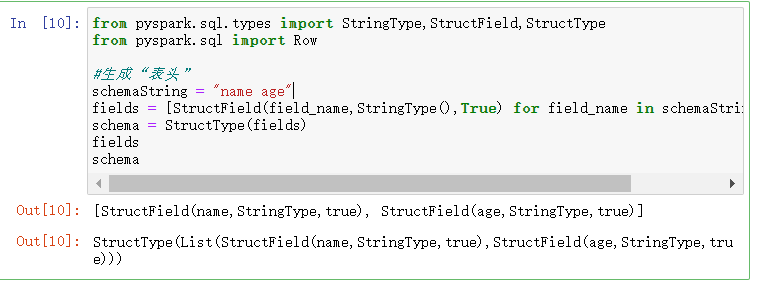
- 生成“表头”
- fields = [StructField(field_name, StringType(), True) ,...]
- schema = StructType(fields)
from pyspark.sql.types import StringType,StructField,StructType
from pyspark.sql import Row #生成“表头”
schemaString = "name age"
fields = [StructField(field_name,StringType(),True) for field_name in schemaString.split(" ")]
schema = StructType(fields)
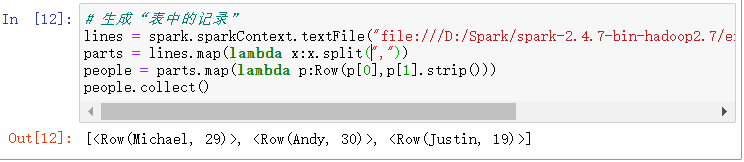
- 生成“表中的记录”
- 创建RDD
- 转换成Row元素,列名=值
# 生成“表中的记录”
lines = spark.sparkContext.textFile("file:///D:/Spark/spark-2.4.7-bin-hadoop2.7/examples/src/main/resources/people.txt")
parts = lines.map(lambda x:x.split(","))
people = parts.map(lambda p:Row(p[0],p[1].strip()))
people.collect()
- 把“表头”和“表中的记录”拼装在一起
- = spark.createDataFrame(RDD, schema)
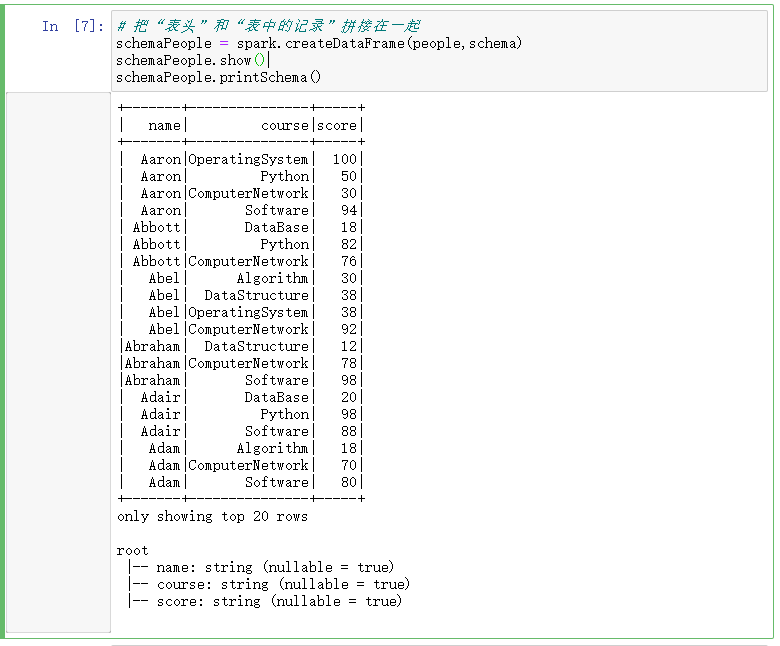
# 把“表头”和“表中的记录”拼接在一起
schemaPeople = spark.createDataFrame(people,schema)
schemaPeople.show()
schemaPeople.printSchema()

4. DataFrame保存为文件
df.write.json(dir)
schemaPeople.write.json("file:///D:/Demo/schemaPeople")
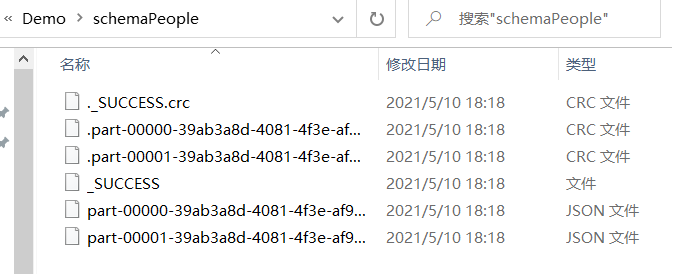
预练习:
读 学生课程分数文件chapter4-data01.txt,创建DataFrame。并尝试用DataFrame的操作完成实验三的数据分析要求。
1.利用反射机制推断RDD模式
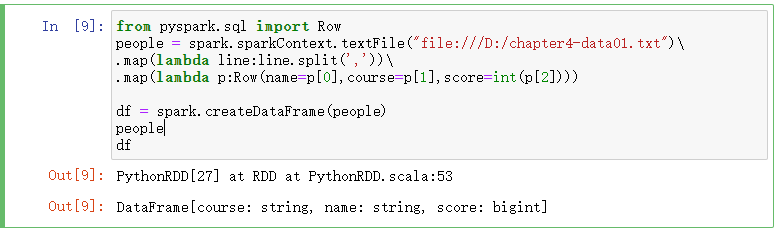
from pyspark.sql import Row
people = spark.sparkContext.textFile("file:///D:/chapter4-data01.txt")\
.map(lambda line:line.split(','))\
.map(lambda p:Row(name=p[0],course=p[1],score=int(p[2]))) df = spark.createDataFrame(people)
people
df
people.first()
df.show()
df.printSchema()

2.使用编程方式定义RDD模式
url = "file:///D:/chapter4-data01.txt"
rdd = sc.textFile(url).map(lambda line:line.split(','))
rdd.take(3)

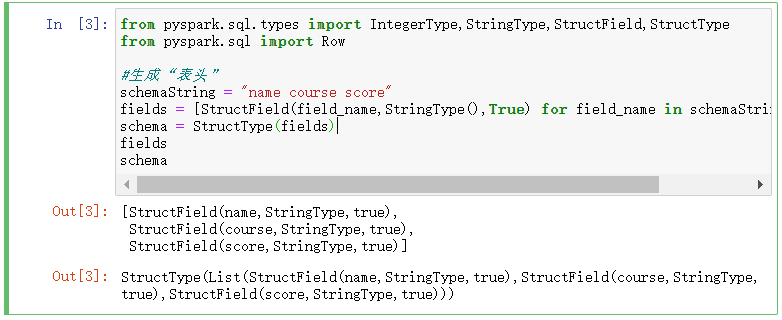
from pyspark.sql.types import IntegerType,StringType,StructField,StructType
from pyspark.sql import Row #生成“表头”
schemaString = "name course score"
fields = [StructField(field_name,StringType(),True) for field_name in schemaString.split(" ")]
schema = StructType(fields)
fields
schema
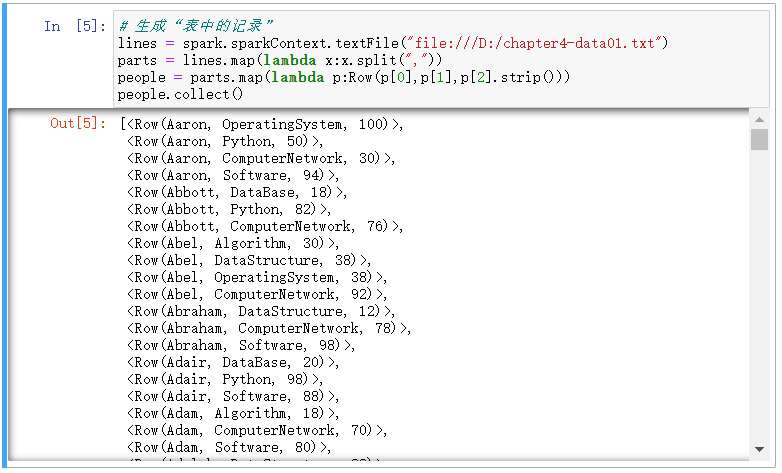
# 生成“表中的记录”
lines = spark.sparkContext.textFile("file:///D:/chapter4-data01.txt")
parts = lines.map(lambda x:x.split(","))
people = parts.map(lambda p:Row(p[0],p[1],p[2].strip()))
people.collect()
# 把“表头”和“表中的记录”拼接在一起
schemaPeople = spark.createDataFrame(people,schema)
schemaPeople.show()
schemaPeople.printSchema()
从RDD创建DataFrame的更多相关文章
- 07 从RDD创建DataFrame
1.pandas df 与 spark df的相互转换 df_s=spark.createDataFrame(df_p) df_p=df_s.toPandas() 2. Spark与Pandas中Da ...
- 【Spark篇】---SparkSQL初始和创建DataFrame的几种方式
一.前述 1.SparkSQL介绍 Hive是Shark的前身,Shark是SparkSQL的前身,SparkSQL产生的根本原因是其完全脱离了Hive的限制. SparkSQL支持查询原 ...
- Spark SQL初始化和创建DataFrame的几种方式
一.前述 1.SparkSQL介绍 Hive是Shark的前身,Shark是SparkSQL的前身,SparkSQL产生的根本原因是其完全脱离了Hive的限制. SparkSQL支持查询原 ...
- JAVA SparkSQL初始和创建DataFrame的几种方式
建议参考SparkSQL官方文档:http://spark.apache.org/docs/latest/sql-programming-guide.html 一.前述 1.SparkSQ ...
- 大数据学习day25------spark08-----1. 读取数据库的形式创建DataFrame 2. Parquet格式的数据源 3. Orc格式的数据源 4.spark_sql整合hive 5.在IDEA中编写spark程序(用来操作hive) 6. SQL风格和DSL风格以及RDD的形式计算连续登陆三天的用户
1. 读取数据库的形式创建DataFrame DataFrameFromJDBC object DataFrameFromJDBC { def main(args: Array[String]): U ...
- RDD、DataFrame和DataSet的区别
原文链接:http://www.jianshu.com/p/c0181667daa0 RDD.DataFrame和DataSet是容易产生混淆的概念,必须对其相互之间对比,才可以知道其中异同. RDD ...
- RDD与DataFrame的转换
RDD与DataFrame转换1. 通过反射的方式来推断RDD元素中的元数据.因为RDD本身一条数据本身是没有元数据的,例如Person,而Person有name,id等,而record是不知道这些的 ...
- 谈谈RDD、DataFrame、Dataset的区别和各自的优势
在spark中,RDD.DataFrame.Dataset是最常用的数据类型,本博文给出笔者在使用的过程中体会到的区别和各自的优势 共性: 1.RDD.DataFrame.Dataset全都是spar ...
- spark RDD,DataFrame,DataSet 介绍
弹性分布式数据集(Resilient Distributed Dataset,RDD) RDD是Spark一开始就提供的主要API,从根本上来说,一个RDD就是你的数据的一个不可变的分布式元素集合,在 ...
- Spark提高篇——RDD/DataSet/DataFrame(二)
该部分分为两篇,分别介绍RDD与Dataset/DataFrame: 一.RDD 二.DataSet/DataFrame 该篇主要介绍DataSet与DataFrame. 一.生成DataFrame ...
随机推荐
- js循环中reduce的用法简单介绍
reduce() 方法接收一个函数作为累加器,reduce 为数组中的每一个元素依次执行回调函数,不包括数组中被删除或从未被赋值的元素,接受四个参数:初始值(上一次回调的返回值),当前元素值,当前索引 ...
- ICMP隐蔽隧道攻击分析与检测(二)
• ICMP协议流量特征分析 一.ASCII与HEX对照转换表 二.ICMP正常流量分析 经常使用的ping命令就是基于ICMP协议,Windows系统下ping默认传输的是:"abcdef ...
- mysql数据库的登录脚本
######################## ku脚本: 可以使用以下ku脚本,它可以根据提供的参数登录到MySQL数据库: #!/bin/bash # Check for correct num ...
- (一)pyahocorasick和marisa_trie,字符串快速查找的python包,自然语言处理,命名实体识别可用的高效包
Pyahocorasick Pyahocorasick是一个基于AC自动机算法的字符串匹配工具.它可以用于快速查找多个短字符串在一个长字符串中的所有出现位置.Pyahocorasick可以在构建状态机 ...
- vmware-ubuntu 设置共享目录
VMware可以通过右上方菜单,管理-虚拟机设置,进入共享文件夹设置界面: vmware设置共享目录,重新启动windows,偶尔会失效.可以按下面步骤重新设置下,copy就行 查询是否存在已挂载的文 ...
- [OpenCV-Python] 10 图像上的算术运算
文章目录 OpenCV-Python: 核心操作 10 图像上的算术运算 10.1 图像加法 10.2 图像混合 10.3 按位运算 OpenCV-Python: 核心操作 10 图像上的算术运算 目 ...
- [OpenCV-Python] 5 视频
文章目录 OpenCV-Python: II OpenCV 中的 Gui 特性 5 视频 5.1 用摄像头捕获视频 5.2 从文件中播放视频 5.3 保存视频 OpenCV-Python: II Op ...
- Java中数字相关的类有哪些?Nuber数字类和Math数学类详解
前言 我们在解决实际问题时,会经常对数字.日期和系统设置进行处理,比如在我们的代码中,经常会遇到一些数字&数学问题.随机数问题.日期问题和系统设置问题等. 为了解决这些问题,Java给我们提供 ...
- JavaScript中的四种枚举方式
字符串和数字具有无数个值,而其他类型如布尔值则是有限的集合. 一周的日子(星期一,星期二,...,星期日),一年的季节(冬季,春季,夏季,秋季)和基本方向(北,东,南,西)都是具有有限值集合的例子. ...
- 2021-04-04:给定一个非负数组arr,和一个正数m。 返回arr的所有子序列中累加和%m之后的最大值。
2021-04-04:给定一个非负数组arr,和一个正数m. 返回arr的所有子序列中累加和%m之后的最大值. 福大大 答案2021-04-04: 自然智慧即可. 1.递归,累加和. 2.动态规划,累 ...