从RDD创建DataFrame
0.前次作业:从文件创建DataFrame
1.pandas df 与 spark df的相互转换 df_s=spark.createDataFrame(df_p) df_p=df_s.toPandas()
# 从数组创建pandas dataframe
import pandas as pd
import numpy as np
arr = np.arange(6).reshape(-1,3)
arr
df_p = pd.DataFrame(arr)
df_p
df_p.columns = ['a','b','c']
df_p

# pandas df 转为spark df
df_s = spark.createDataFrame(df_p)
df_s.show()
df_s.collect()

# spark df 转为pandas df
df_s.show()
df_s.toPandas()

2. Spark与Pandas中DataFrame对比
http://www.lining0806.com/spark%E4%B8%8Epandas%E4%B8%ADdataframe%E5%AF%B9%E6%AF%94/
3.1 利用反射机制推断RDD模式
- sc创建RDD
spark.sparkContext.textFile("file:///D:/Spark/spark-2.4.7-bin-hadoop2.7/examples/src/main/resources/people.txt").first()
spark.sparkContext.textFile("file:///D:/Spark/spark-2.4.7-bin-hadoop2.7/examples/src/main/resources/people.txt")\
.map(lambda line:line.split(',')).first()

- 转换成Row元素,列名=值
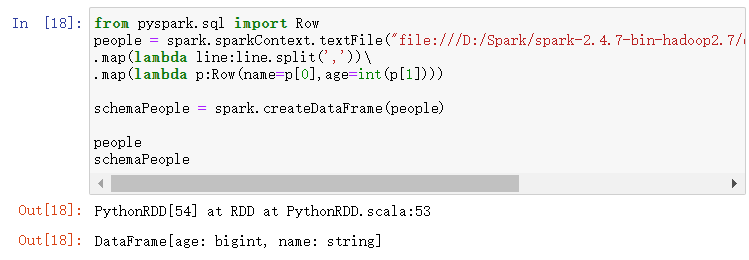
from pyspark.sql import Row
people = spark.sparkContext.textFile("file:///D:/Spark/spark-2.4.7-bin-hadoop2.7/examples/src/main/resources/people.txt")\
.map(lambda line:line.split(','))\
.map(lambda p:Row(name=p[0],age=int(p[1])))
- spark.createDataFrame生成df
schemaPeople = spark.createDataFrame(people)
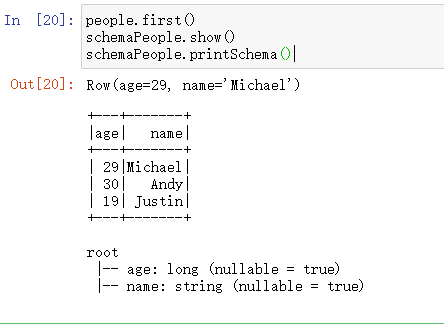
- df.show(), df.printSchema()
schemaPeople.show()
schemaPeople.printSchema()
3.2 使用编程方式定义RDD模式
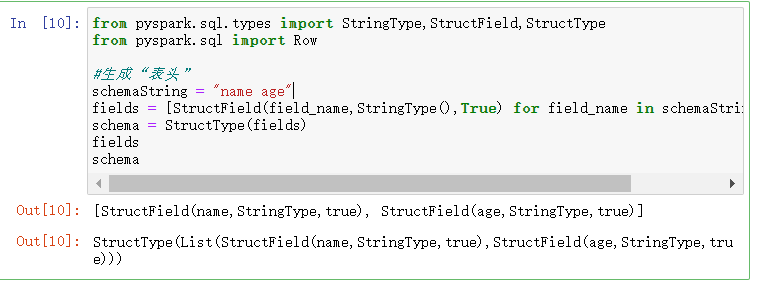
- 生成“表头”
- fields = [StructField(field_name, StringType(), True) ,...]
- schema = StructType(fields)
from pyspark.sql.types import StringType,StructField,StructType
from pyspark.sql import Row #生成“表头”
schemaString = "name age"
fields = [StructField(field_name,StringType(),True) for field_name in schemaString.split(" ")]
schema = StructType(fields)
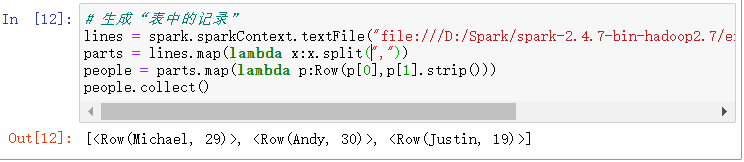
- 生成“表中的记录”
- 创建RDD
- 转换成Row元素,列名=值
# 生成“表中的记录”
lines = spark.sparkContext.textFile("file:///D:/Spark/spark-2.4.7-bin-hadoop2.7/examples/src/main/resources/people.txt")
parts = lines.map(lambda x:x.split(","))
people = parts.map(lambda p:Row(p[0],p[1].strip()))
people.collect()
- 把“表头”和“表中的记录”拼装在一起
- = spark.createDataFrame(RDD, schema)
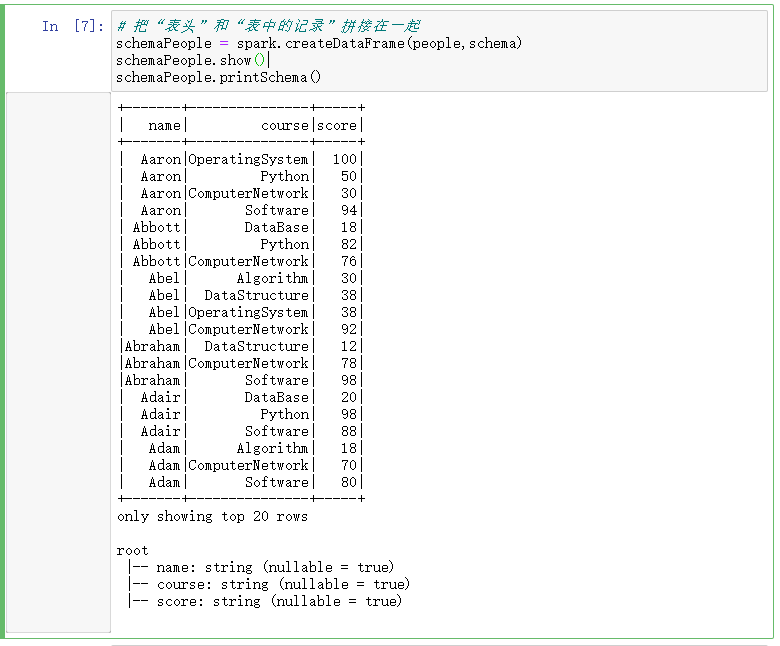
# 把“表头”和“表中的记录”拼接在一起
schemaPeople = spark.createDataFrame(people,schema)
schemaPeople.show()
schemaPeople.printSchema()

4. DataFrame保存为文件
df.write.json(dir)
schemaPeople.write.json("file:///D:/Demo/schemaPeople")
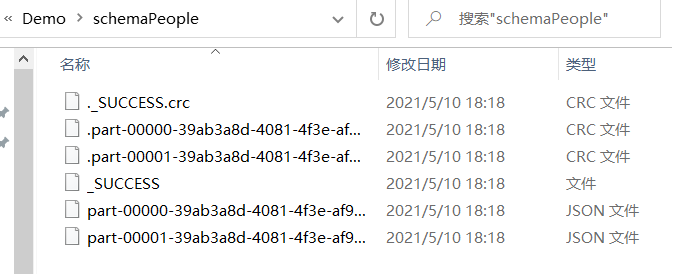
预练习:
读 学生课程分数文件chapter4-data01.txt,创建DataFrame。并尝试用DataFrame的操作完成实验三的数据分析要求。
1.利用反射机制推断RDD模式
from pyspark.sql import Row
people = spark.sparkContext.textFile("file:///D:/chapter4-data01.txt")\
.map(lambda line:line.split(','))\
.map(lambda p:Row(name=p[0],course=p[1],score=int(p[2]))) df = spark.createDataFrame(people)
people
df
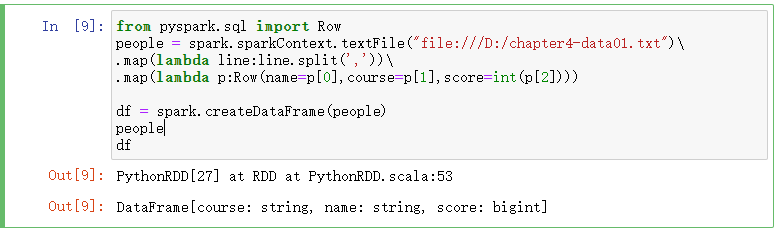
people.first()
df.show()
df.printSchema()

2.使用编程方式定义RDD模式
url = "file:///D:/chapter4-data01.txt"
rdd = sc.textFile(url).map(lambda line:line.split(','))
rdd.take(3)

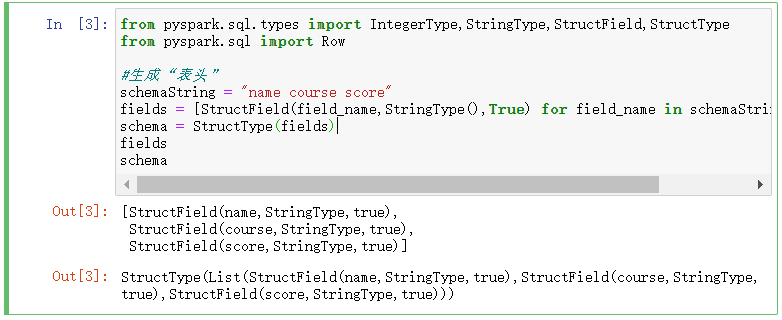
from pyspark.sql.types import IntegerType,StringType,StructField,StructType
from pyspark.sql import Row #生成“表头”
schemaString = "name course score"
fields = [StructField(field_name,StringType(),True) for field_name in schemaString.split(" ")]
schema = StructType(fields)
fields
schema
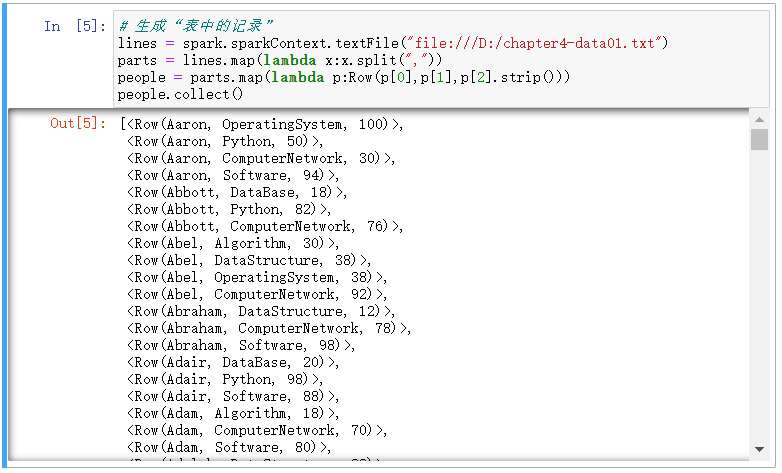
# 生成“表中的记录”
lines = spark.sparkContext.textFile("file:///D:/chapter4-data01.txt")
parts = lines.map(lambda x:x.split(","))
people = parts.map(lambda p:Row(p[0],p[1],p[2].strip()))
people.collect()
# 把“表头”和“表中的记录”拼接在一起
schemaPeople = spark.createDataFrame(people,schema)
schemaPeople.show()
schemaPeople.printSchema()
从RDD创建DataFrame的更多相关文章
- 07 从RDD创建DataFrame
1.pandas df 与 spark df的相互转换 df_s=spark.createDataFrame(df_p) df_p=df_s.toPandas() 2. Spark与Pandas中Da ...
- 【Spark篇】---SparkSQL初始和创建DataFrame的几种方式
一.前述 1.SparkSQL介绍 Hive是Shark的前身,Shark是SparkSQL的前身,SparkSQL产生的根本原因是其完全脱离了Hive的限制. SparkSQL支持查询原 ...
- Spark SQL初始化和创建DataFrame的几种方式
一.前述 1.SparkSQL介绍 Hive是Shark的前身,Shark是SparkSQL的前身,SparkSQL产生的根本原因是其完全脱离了Hive的限制. SparkSQL支持查询原 ...
- JAVA SparkSQL初始和创建DataFrame的几种方式
建议参考SparkSQL官方文档:http://spark.apache.org/docs/latest/sql-programming-guide.html 一.前述 1.SparkSQ ...
- 大数据学习day25------spark08-----1. 读取数据库的形式创建DataFrame 2. Parquet格式的数据源 3. Orc格式的数据源 4.spark_sql整合hive 5.在IDEA中编写spark程序(用来操作hive) 6. SQL风格和DSL风格以及RDD的形式计算连续登陆三天的用户
1. 读取数据库的形式创建DataFrame DataFrameFromJDBC object DataFrameFromJDBC { def main(args: Array[String]): U ...
- RDD、DataFrame和DataSet的区别
原文链接:http://www.jianshu.com/p/c0181667daa0 RDD.DataFrame和DataSet是容易产生混淆的概念,必须对其相互之间对比,才可以知道其中异同. RDD ...
- RDD与DataFrame的转换
RDD与DataFrame转换1. 通过反射的方式来推断RDD元素中的元数据.因为RDD本身一条数据本身是没有元数据的,例如Person,而Person有name,id等,而record是不知道这些的 ...
- 谈谈RDD、DataFrame、Dataset的区别和各自的优势
在spark中,RDD.DataFrame.Dataset是最常用的数据类型,本博文给出笔者在使用的过程中体会到的区别和各自的优势 共性: 1.RDD.DataFrame.Dataset全都是spar ...
- spark RDD,DataFrame,DataSet 介绍
弹性分布式数据集(Resilient Distributed Dataset,RDD) RDD是Spark一开始就提供的主要API,从根本上来说,一个RDD就是你的数据的一个不可变的分布式元素集合,在 ...
- Spark提高篇——RDD/DataSet/DataFrame(二)
该部分分为两篇,分别介绍RDD与Dataset/DataFrame: 一.RDD 二.DataSet/DataFrame 该篇主要介绍DataSet与DataFrame. 一.生成DataFrame ...
随机推荐
- Teamcenter_SOA开发:使用SOA登录Teamcenter
本文Teamcenter SOA使用C++参考SOA的例子进行编写,以下代码为登录Teamcenter,代码工程在Teamcenter四层环境下运行. SOA的库文件.样例文件.帮助文件在Teamce ...
- 集合-LinkedList 源码分析(JDK 1.8)
1.概述 LinkedList 是 Java 集合框架中一个重要的实现,其底层采用的双向链表结构.和 ArrayList 一样,LinkedList 也支持空值和重复值.由于 LinkedList 基 ...
- 高尔顿钉板的统计意义—R实现
提到高尔顿,人们总是把他和钉板实验联系在一起,偶尔也会有人提及他是达尔文的表弟.实际上,作为维多利亚时代的人类学家.统计学家.心理学家和遗传学家,同时又是热带探险家.地理学家.发明家.气象学家,高尔顿 ...
- python 启动外部程序四种方法
在Python中,可以方便地使用os模块来运行其他脚本或者程序,这样就可以在脚本中直接使用其他脚本或程序提供的功能,而不必再次编写实现该功能的代码.为了更好地控制运行的进程,可以使用win32proc ...
- ChatGPT,我彻彻底底沦陷了!
当谈到人工智能技术的时候,我们会经常听到GPT这个术语.它代表"Generative Pre-trained Transformer",是一种机器学习模型,采用了神经网络来模拟人类 ...
- mysql锁及锁出现总结
转载请注明出处: 1.按锁粒度分类: 行锁:锁某行数据,锁粒度最小,并发度高:: 行锁是指加锁的时候锁住的是表的某一行或多行记录,多个事务访问同一张表时,只有被锁住的记录不能访问,其他的记录可正常访问 ...
- MySQL(十二)索引使用的情况分析
索引使用的情况分析 数据准备 创建表student_info.course CREATE TABLE `student_info` ( `id` int NOT NULL AUTO_INCREMENT ...
- 【Java SE】网络编程
1. 网络编程概述 网络编程的目的:直接或者间接地通过网络协议与其他计算机实现数据交换,进行通讯. 网络编程两个主要的问题: ①如何精准地定位网络上的一台或多台主机,并定位主机上的特定应用 ②找到主机 ...
- 轻量级Web框架Flask(二)
Flask-SQLAlchemy MySQL是免费开源软件,大家可以自行搜索其官网(https://www.MySQL.com/downloads/) 测试MySQL是否安装成功 在所有程序中,找到M ...
- PWN 学习日志(1): pwntools简单使用与栈溢出实践
常用的模块 模块 功能 asm 汇编与反汇编 dynelf 远程符号泄漏 elf 对elf文件进行操作 memleak 用于内存泄漏 shellcraft shellcode生成器 gdb 配合gdb ...