【算法设计与分析基础】25、单起点最短路径的dijkstra算法
首先看看这换个数据图

邻接矩阵
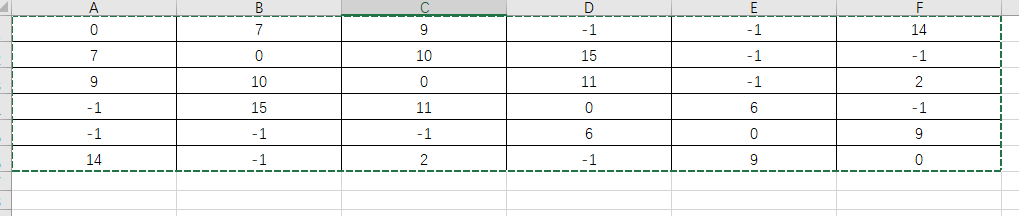
dijkstra算法的寻找最短路径的核心就是对于这个节点的数据结构的设计
1、节点中保存有已经加入最短路径的集合中到当前节点的最短路径的节点
2、从起点经过或者不经过 被选中节点到当前节点的最短路径
以这个思路开始,就可以根据贪心算法,获取每一步需要设置的值,每一步加入路径的节点

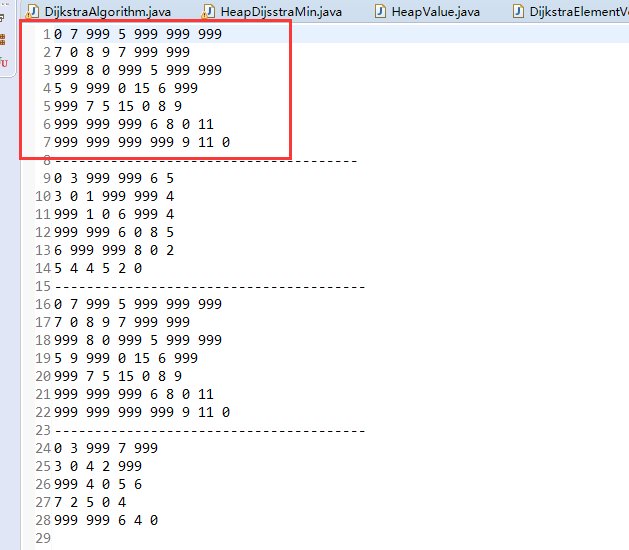
对于这个算法,我采用:小顶堆 + 邻接矩阵(数组)
1、邻接矩阵的初始化
package cn.xf.algorithm.ch09Greedy.vo; import java.io.BufferedInputStream;
import java.io.BufferedReader;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List; import org.junit.Test; public class MGraph {
private int eleSize;
private int nums[][];
private List<KruskalBianVo> kruskalBianVos = new ArrayList<KruskalBianVo>(); public MGraph() {
// TODO Auto-generated constructor stub
} public MGraph(int eleSize, int[][] nums) {
this.eleSize = eleSize;
this.nums = nums;
} public MGraph(File file) throws Exception {
if(file.exists()) {
//读取数据流,获取数据源
FileInputStream fis;
BufferedInputStream bis;
try {
fis = new FileInputStream(file);
//缓冲
bis = new BufferedInputStream(fis);
byte buffer[] = new byte[1024];
while(bis.read(buffer) != -1) {
String allData = new String(buffer);
String lines[] = allData.split("\r\n");
int allLines = lines.length;
int allColumns = lines[0].split(" ").length;
if(allLines < allColumns) {
//如果行比较小
eleSize = allLines;
} else {
//否则以列为准
eleSize = allColumns;
}
nums = new int[eleSize][eleSize];
for(int i = 0; i < eleSize; ++i) {
//对每一行数据进行入库处理
String everyNums[] = lines[i].split(" ");
for(int j = 0; j < eleSize; ++j) {
nums[i][j] = Integer.parseInt(everyNums[j]);
}
}
} //获取这个矩阵的所有边 kruskalBianVos
for(int i = 0; i < eleSize; ++i) {
for(int j = i + 1; j < eleSize; ++j) {
if(nums[i][j] < 999) {
KruskalBianVo kruskalBianVo = new KruskalBianVo();
kruskalBianVo.setBeginNode(i);
kruskalBianVo.setEndNode(j);
kruskalBianVo.setLength(nums[i][j]);
kruskalBianVos.add(kruskalBianVo);
}
}
} } catch (FileNotFoundException e) {
e.printStackTrace();
}
} else {
System.out.println("文件不存在");
}
} public int getEleSize() {
return eleSize;
}
public void setEleSize(int eleSize) {
this.eleSize = eleSize;
}
public int[][] getNums() {
return nums;
}
public void setNums(int[][] nums) {
this.nums = nums;
} public List<KruskalBianVo> getKruskalBianVos() {
return kruskalBianVos;
} public void setKruskalBianVos(List<KruskalBianVo> kruskalBianVos) {
this.kruskalBianVos = kruskalBianVos;
} public static void main(String[] args) {
String path = MGraph.class.getResource("").getPath();
path = path.substring(0, path.indexOf("/vo"));
File f = new File(path + "/resource/test.txt");
try {
MGraph mg = new MGraph(f);
System.out.println(mg.getKruskalBianVos().size());
int rr[][] = mg.getNums();
System.out.println(rr);
} catch (Exception e) {
e.printStackTrace();
}
} }
2、小顶堆的结构
package cn.xf.algorithm.ch09Greedy.vo;
public interface HeapValue {
/**
* 当前对象小于,等于比较对象的时候,返回true
* @param heapValue
* @return
*/
public abstract Boolean compareMin(HeapValue heapValue);
public abstract Object getValue();
public Object getKey();
}
package cn.xf.algorithm.ch09Greedy.util; import java.util.ArrayList;
import java.util.List; import cn.xf.algorithm.ch09Greedy.vo.HeapValue; /**
* 堆构造以及排序
*
* .功能:堆的构造
* 1、堆可以定义为一颗二叉树,树的节点包含键,并且满足一下条件
* 1) 树的形状要求:这棵二叉树是基本完备的(完全二叉树),树的每一层都是满的,除了最后一层最右边的元素可能缺位
* 2) 父母优势,堆特性,每一个节点的键都要大于或者等于他子女的键(对于任何叶子我们认为这都是自动满足的)
*
* 对于堆:
* 只存在一颗n个节点的完全二叉树他的高度:取下界的 log2的n的对数
* 堆的根总是包含了堆的最大元素
* 堆的一个节点以及该节点的子孙也是一个堆
* 可以用数组的来实现堆,方法是从上到下,从左到右的方式来记录堆的元素。
*
* @author xiaof
* @version Revision 1.0.0
* @see:
* @创建日期:2017年8月25日
* @功能说明:
*
*/
public class HeapDijsstraMin {
private List<HeapValue> heap; //构造函数
public HeapDijsstraMin() {
//创建堆
heap = new ArrayList<HeapValue>();
} public HeapDijsstraMin(List<HeapValue> heap) {
//创建堆
this.heap = heap;
createHeadDownToUp(this.heap);
} /**
* 从小到大的堆
* @param heap
* @return
*/
private void createHeadDownToUp(List<HeapValue> heap){
//对数组进行堆排序
if(heap == null || heap.size() <= 0)
return;
int len = heap.size();
//从树的中间开始循环
for(int i = len / 2; i > 0; --i) {
//首先预存当前进行操作的节点‘
//索引和值
int selectIndex = i - 1;
HeapValue selectValue = heap.get(selectIndex);
boolean isHeap = false; //用来判断当前节点下是否已经没有其他节点比这个节点小了,作为是否成堆的标识
while(!isHeap && 2 * (selectIndex + 1) <= len) {
//当前节点的最大的孩子节点的位置,开始默认是第一个孩子节点的位置
int childIndex = 2 * i - 1;
//判断是否存在两个孩子节点,如果存在,那么就选出最大的那个
if(2 * i < len) {
//获取比较小的那个节点作为备选替换节点
childIndex = heap.get(childIndex).compareMin(heap.get(childIndex + 1)) ? childIndex : childIndex + 1;
}
//判断当前节点是不是比下面最小的那个节点还要小 heap.get(childIndex)
if(selectValue.compareMin(heap.get(childIndex))) {
//如果比下面最大的还大,那就表明这个节点为根的子树已经是一颗树了
isHeap = true;
} else {
//如果节点不是小的,那么更换掉
heap.set(selectIndex, heap.get(childIndex));
//并交换当前遍历交换的节点
selectIndex = childIndex;
//这个节点和子节点全部遍历结束之后,交换出最初用来交换的选中节点
heap.set(selectIndex, selectValue);
}
}
}
} /**
* 对堆的节点的单次变换
* @param i 第几个节点
*/
private void shifHeadDownToUp(int i) {
if(heap == null || heap.size() <= 0)
return;
int len = this.heap.size();
//索引i需要存在于这个节点中
if(i >= len)
return;
// 首先预存当前进行操作的节点‘
// 索引和值
int selectIndex = i - 1;
HeapValue selectValue = heap.get(selectIndex);
boolean isHeap = false; // 用来判断当前节点下是否已经没有其他节点比这个节点小了,作为是否成堆的标识
while (!isHeap && 2 * (selectIndex + 1) <= len) {
// 当前节点的最大的孩子节点的位置,开始默认是第一个孩子节点的位置
int childIndex = 2 * (selectIndex + 1) - 1;
// 判断是否存在两个孩子节点,如果存在,那么就选出最大的那个
if (2 * (selectIndex + 1) < len) {
// 获取比较小的那个节点作为备选替换节点
// childIndex = heap.get(childIndex) < heap.get(childIndex + 1) ? childIndex : childIndex + 1;
childIndex = heap.get(childIndex).compareMin(heap.get(childIndex + 1)) ? childIndex : childIndex + 1;
}
// 判断当前节点是不是比下面最小的那个节点还要小
if (selectValue.compareMin(heap.get(childIndex))) {
// 如果比下面最大的还大,那就表明这个节点为根的子树已经是一颗树了
isHeap = true;
} else {
// 如果节点不是小的,那么更换掉
heap.set(selectIndex, heap.get(childIndex));
// 并交换当前遍历交换的节点
selectIndex = childIndex;
// 这个节点和子节点全部遍历结束之后,交换出最初用来交换的选中节点
heap.set(selectIndex, selectValue);
}
} } //向堆添加元素
public void add(HeapValue element) {
// int oldLen = heap.size();
heap.add(element);
//然后从加入的位置的父节点开始,从下向上所有父节点,全部变换一次
for(int i = heap.size() / 2; i > 0; i = i / 2) {
this.shifHeadDownToUp(i);
}
} /**
* 移除堆中一个指定元素
* @param index
* @return
*/
// public int remove(int index) {
// int result = heap.get(index - 1);
// //思路是吧剩下的最后一个元素作为参照元素,填充进去
// int lastValue = heap.get(heap.size() - 1);
// heap.set(index - 1, lastValue);
// heap.remove(heap.size() - 1);
// //然后从下向上,吧这个节点对应的位置的数据进行递归
// for(int i = index; i > 0; i = i / 2) {
// this.shifHeadDownToUp(i);
// }
// return result;
// } public int remove(Object key) {
int index = getKeyIndex(key);
//遍历这个key
if(index == -1) {
return -1;
}
//思路是吧剩下的最后一个元素作为参照元素,填充进去
HeapValue lastValue = heap.get(heap.size() - 1);
heap.set(index, lastValue);
heap.remove(heap.size() - 1);
//然后从下向上,吧这个节点对应的位置的数据进行递归
for(int i = index + 1; i > 0; i = i / 2) {
this.shifHeadDownToUp(i);
}
return index;
} private int getKeyIndex (Object keyName) {
int index = -1;
for(int i = 0; i < heap.size(); ++i) {
if(keyName.equals(heap.get(i).getKey())) {
index = i;
break;
}
}
return index;
} private HeapValue getKeyValue (Object keyName) {
int index = -1;
for(int i = 0; i < heap.size(); ++i) {
if(keyName.equals(heap.get(i).getKey())) {
index = i;
break;
}
}
return heap.get(index);
} /**
* 默认删除根节点
* @return
*/
public HeapValue remove() {
HeapValue result = heap.get(0);
//思路是吧剩下的最后一个元素作为参照元素,填充进去
HeapValue lastValue = heap.get(heap.size() - 1);
heap.set(0, lastValue);
heap.remove(heap.size() - 1);
//然后从下向上,吧这个节点对应的位置的数据进行递归
for(int i = 1; i > 0; i = i / 2) {
this.shifHeadDownToUp(i);
}
return result;
} @Override
public String toString() {
String result = "";
for(int i = 0; i < heap.size(); ++i) {
HeapValue hv = heap.get(i);
result += hv.getValue().toString() +"\t";
// System.out.print(hv.getValue().toString() + "\t");
}
return result;
} public int size() {
return heap.size();
} public HeapValue getIndex(int i) {
return heap.get(i);
} public static void main(String[] args) { }
}
3、标识各个节点的数据结构
package cn.xf.algorithm.ch09Greedy.vo; /**
*
* 存放节点信息
* .
*
* @author xiaof
* @version Revision 1.0.0
* @see:
* @创建日期:2017年8月30日
* @功能说明:
*
*/
public class DijkstraElementVo implements HeapValue {
private String elementName; //节点名字 private DijkstraElementVo preDijkstraElementVo; //最短路径的上一个节点 private int minLength; //当前节点的从开始起点到当前节点的最短路径 public String getElementName() {
return elementName;
} public void setElementName(String elementName) {
this.elementName = elementName;
} public DijkstraElementVo getPreDijkstraElementVo() {
return preDijkstraElementVo;
} public void setPreDijkstraElementVo(DijkstraElementVo preDijkstraElementVo) {
this.preDijkstraElementVo = preDijkstraElementVo;
} public int getMinLength() {
return minLength;
} public void setMinLength(int minLength) {
this.minLength = minLength;
} @Override
public Boolean compareMin(HeapValue heapValue) {
int value = (Integer) heapValue.getValue();
Boolean result = false;
if(this.minLength <= value)
result = true;
return result;
} @Override
public Object getValue() {
return minLength;
} @Override
public Object getKey() {
return elementName;
} @Override
public String toString() {
//a[b,lenght]
String preName = "null";
if(preDijkstraElementVo != null) {
// preName = preDijkstraElementVo.getElementName();
preName = preDijkstraElementVo == null ? "null" : preDijkstraElementVo.getElementName();
}
return elementName + "[" + preName + ", " + minLength + "]";
// return elementName + "[" + preDijkstraElementVo != null ? "null" : preDijkstraElementVo.getElementName() + ", " + minLength + "]";
}
}
4、算法的核心实现
package cn.xf.algorithm.ch09Greedy.dijkstra; import cn.xf.algorithm.ch09Greedy.util.HeapDijsstraMin;
import cn.xf.algorithm.ch09Greedy.vo.DijkstraElementVo;
import cn.xf.algorithm.ch09Greedy.vo.HeapValue;
import cn.xf.algorithm.ch09Greedy.vo.MGraph; /**
* 单起点最短路径的dijkstra算法
* 功能:输入:具非负权重加权连通图G = <V, E> 以及它的顶点s
* 输出:对于V中每个顶点v来说,从s到v的最短路径的长度dv
* 以及路径上的倒数第二个顶点pv
* @author xiaofeng
* @date 2017年8月31日
* @fileName DijkstraAlgorithm.java
*
*/
public class DijkstraAlgorithm { /**
*
* @param mg 图邻接矩阵
* @param start 初始起点
*/
public void dijkstra(MGraph mg, DijkstraElementVo start) {
if(mg == null)
return;
//获取邻接矩阵
int juzhen[][] = mg.getNums(); //先初始化小顶堆的所有节点
HeapDijsstraMin heapDijsstraMin = new HeapDijsstraMin(); for(int i = 0; i < mg.getEleSize(); ++i) {
DijkstraElementVo dijkstraElementVo = new DijkstraElementVo();
char cur = (char) ('A' + i);
dijkstraElementVo.setElementName(String.valueOf(cur));
//路径长度,初始都为无穷大,用999来虚拟
dijkstraElementVo.setMinLength(999);
//路径的上一个节点
dijkstraElementVo.setPreDijkstraElementVo(null);
heapDijsstraMin.add(dijkstraElementVo);
} //更新初始节点,就是先删除,然后新增进去
heapDijsstraMin.remove(start.getKey());
start.setMinLength(0);
start.setPreDijkstraElementVo(null);
heapDijsstraMin.add(start);
//输出验证一波
// System.out.print(start.toString() + "=>"); //依次遍历所有的节点,并更新对应的节点在堆中的数据
int selected[] = new int[mg.getEleSize()];
while(heapDijsstraMin.size() > 0) {
//当堆中还有节点没有被选中
HeapValue dijkstraHeapValue = (DijkstraElementVo) heapDijsstraMin.remove();
System.out.print(dijkstraHeapValue.toString() + "=>");
//遍历剩下所有,节点,并逐个更新一遍所有的数据
for(int i= 0; i < heapDijsstraMin.size(); ++i) {
//比较当前对象的最短路径,如果比用当前的这个节点到对应的节点的路径长,那么就更新为当前的最短路径
//说白了,就是把当前节点加入路径 中之后,后面节点可以通过这个节点或者不用这个节点和起点的最短距离
String curName = (String) dijkstraHeapValue.getKey();
int cur = curName.toCharArray()[0] - 'A';
int curValue = Integer.valueOf(String.valueOf(dijkstraHeapValue.getValue())); //获取下一个对象的节点
HeapValue dijkstraHeapValueNext = heapDijsstraMin.getIndex(i);
String nextName = (String) dijkstraHeapValueNext.getKey();
int next = nextName.toCharArray()[0] - 'A';
int nextValue = Integer.valueOf(String.valueOf(dijkstraHeapValueNext.getValue())); if(curValue + juzhen[cur][next] < nextValue) {
//如果是通过新节点的路径比通过原来的路径小,那么更新路径
DijkstraElementVo dijkstraElementVoNew = new DijkstraElementVo();
dijkstraElementVoNew.setElementName(nextName);
dijkstraElementVoNew.setMinLength(curValue + juzhen[cur][next]);
dijkstraElementVoNew.setPreDijkstraElementVo((DijkstraElementVo) dijkstraHeapValue);
//先移除这个节点,然后新增
heapDijsstraMin.remove(dijkstraHeapValueNext.getKey());
heapDijsstraMin.add(dijkstraElementVoNew);
} //判断是否更新
}
}
} }
5、结果显示
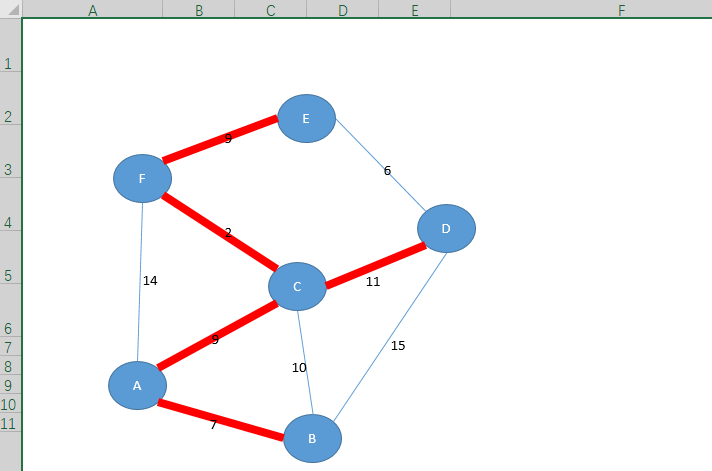
矩阵数据来源:
999代表不可到达

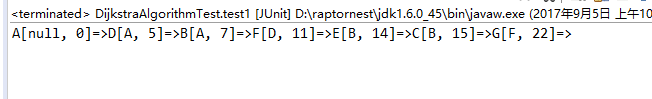
这个题的图解
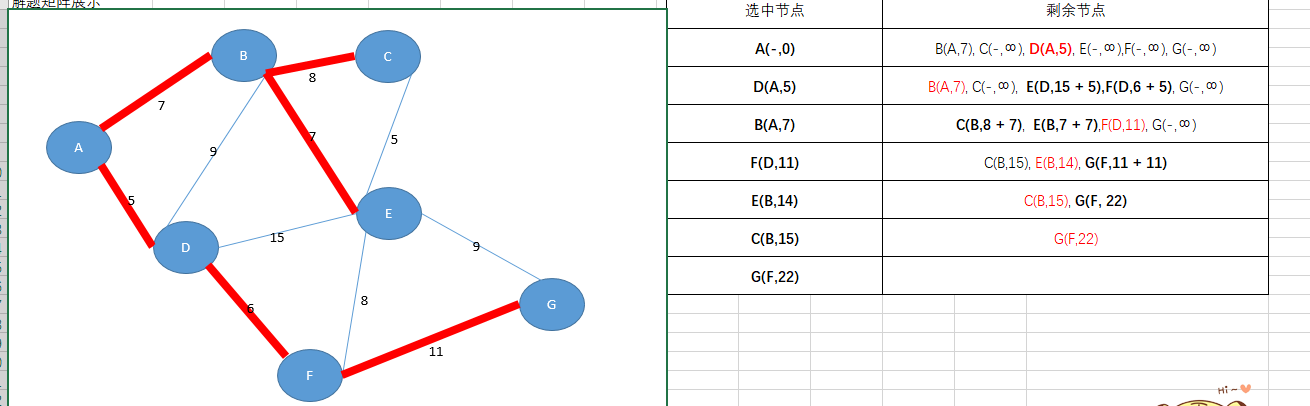
【算法设计与分析基础】25、单起点最短路径的dijkstra算法的更多相关文章
- 单源最短路径(dijkstra算法)php实现
做一个医学项目,当中在病例评分时会用到单源最短路径的算法.单源最短路径的dijkstra算法的思路例如以下: 如果存在一条从i到j的最短路径(Vi.....Vk,Vj),Vk是Vj前面的一顶点.那么( ...
- 算法设计与分析基础 (Anany Levitin 著)
第1章 绪论 1.1 什么是算法 1.2 算法问题求解基础 1.2.1 理解问题 1.2.2 了解计算设备的性能 1.2.3 在精确解法和近似解法之间做出选择 1.2.4 算法的设计技术 1.2.5 ...
- 单源最短路径:Dijkstra算法(堆优化)
前言:趁着对Dijkstra还有点印象,赶快写一篇笔记. 注意:本文章面向已有Dijkstra算法基础的童鞋. 简介 单源最短路径,在我的理解里就是求从一个源点(起点)到其它点的最短路径的长度. 当然 ...
- 0016:单源最短路径(dijkstra算法)
题目链接:https://www.luogu.com.cn/problem/P4779 题目描述:给定一个 n 个点,m 条有向边的带非负权图,计算从 s 出发,到每个点的距离. 这道题就是一个单源最 ...
- 【算法导论】单源最短路径之Dijkstra算法
Dijkstra算法解决了有向图上带正权值的单源最短路径问题,其运行时间要比Bellman-Ford算法低,但适用范围比Bellman-Ford算法窄. 迪杰斯特拉提出的按路径长度递增次序来产生源点到 ...
- 单源最短路径问题-Dijkstra算法
同样是层序遍历,在每次迭代中挑出最小的设置为已知 ===================================== 2017年9月18日10:00:03 dijkstra并不是完全的层序遍历 ...
- 单源点最短路径的Dijkstra算法
在带权图(网)里,点A到点B所有路径中边的权值之和为最短的那一条路径,称为A,B两点之间的最短路径;并称路径上的第一个顶点为源点(Source),最后一个顶点为终点(Destination).在无权图 ...
- 【算法设计与分析基础】24、kruskal算法详解
首先我们获取这个图 根据这个图我们可以得到对应的二维矩阵图数据 根据kruskal算法的思想,首先提取所有的边,然后把所有的边进行排序 思路就是把这些边按照从小到大的顺序组装,至于如何组装 这里用到并 ...
- 单源最短路径问题(dijkstra算法 及其 优化算法(优先队列实现))
#define _CRT_SECURE_NO_WARNINGS /* 7 10 0 1 5 0 2 2 1 2 4 1 3 2 2 3 6 2 4 10 3 5 1 4 5 3 4 6 5 5 6 9 ...
随机推荐
- SQL SERVER Buffer Pool扩展
Buffer Pool扩展简介 Buffer Pool扩展是buffer pool 和非易失的SSD硬盘做连接.以SSD硬盘的特点来提高随机读性能. 在Buffer Pool 扩展之前,SQL Ser ...
- HDU 6043 KazaQ's Socks (规律)
Description KazaQ wears socks everyday. At the beginning, he has nn pairs of socks numbered from 11 ...
- 关于无法使用python执行进入百度页面的代码修改
前几天听了个坑爹的视频教学,按照你们的方法做了,但尼玛,执行下来各种问题啊: 首先进入页面,总是提示开发者模式,删了下次执行又挂了,于是乎我就找网上帖子解决问题,果然被我解决了 先装这两个文件,把浏览 ...
- 初识Java,猜字游戏
import java.util.*; public class caizi{ public static void main(String[] args){ Scanner in=new Scann ...
- Unity 发布的 WebGL 使用SendMessage传递多个参数
如果要实现Unity与浏览器的数据交互一般都会采用两种方式 方法一: Application.ExternalCall("SayHello","helloworld&qu ...
- pickle和json模块
json模块 json模块是实现序列化和反序列化的,主要用户不同程序之间的数据交换,首先来看一下: dumps()序列化 import json '''json模块是实现序列化和反序列话功能的''' ...
- ida和idr机制分析(盘符分配机制)
# ida和idr机制分析 ida和idr的机制在我个人看来,是内核管理整数资源的一种方法.在内核中,许多地方都用到了该结构(例如class的id,disk的id),更直观的说,硬盘的sda到sdz的 ...
- [BZOJ 3629][ JLOI2014 ]聪明的燕姿
这道题考试选择打表,完美爆零.. 算数基本定理: 任何一个大于1的自然数N,都可以唯一分解成有限个质数的乘积N=P₁^a₁ P₂^a₂…Pn^an,这里P₁<P₂<…<Pn均为质数, ...
- cornerstone 使用报错 working copy ... is too old(format 10 created by subversion 1.6)
1.....本来正常使用的cornerstone 突然出现这个问题 图片如下 2....解决方案,,,,也搜集了方法,,但是最后竟然就这样解决了,,完全搞不懂的解决方案啊 如图 3......如有错误 ...
- .NET Standard 2.0 特性介绍和使用指南
.NET Standard 2.0 发布日期:2017年8月14日 公告原文地址 前言 早上起来.NET社区沸腾了,期待已久的.NET Core 2.0终于发布!根据个人经验,微软的产品一般在2.0时 ...