ItemCF_基于物品的协同过滤_MapReduceJava代码实现思路
ItemCF_基于物品的协同过滤
1. 概念

2. 原理
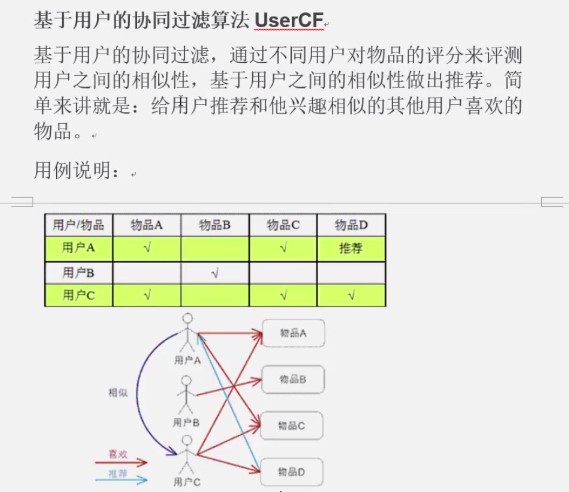
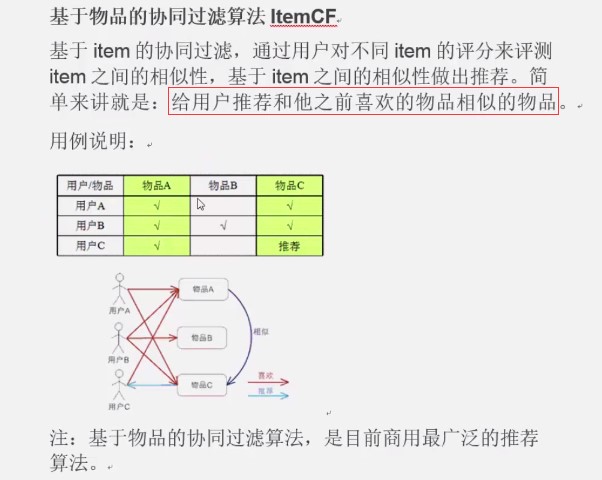
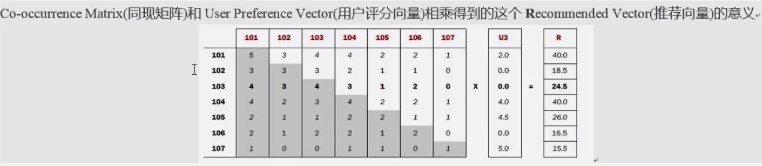

3. java代码实现思路
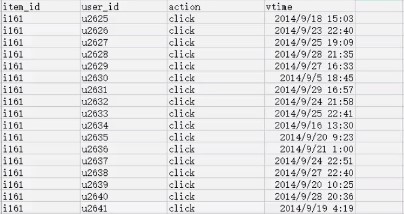
六个MapReduce
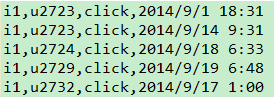
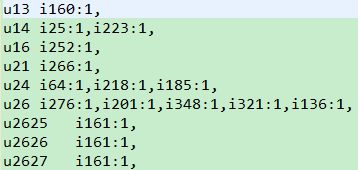
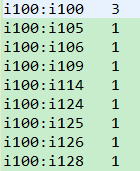
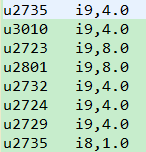


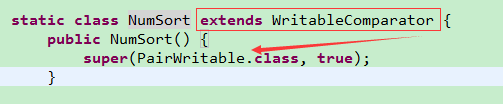
PairWritable,

ItemCF_基于物品的协同过滤_MapReduceJava代码实现思路的更多相关文章
- ItemCF_基于物品的协同过滤
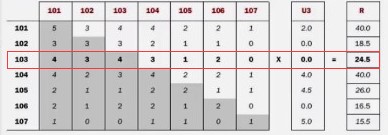
ItemCF_基于物品的协同过滤 1. 概念 2. 原理 如何给用户推荐? 给用户推荐他没有买过的物品--103 3. java代码实现思路 数据集: 第一步:构建物品的同现矩阵 第 ...
- 转】Mahout分步式程序开发 基于物品的协同过滤ItemCF
原博文出自于: http://blog.fens.me/hadoop-mahout-mapreduce-itemcf/ 感谢! Posted: Oct 14, 2013 Tags: Hadoopite ...
- 基于物品的协同过滤item-CF 之电影推荐 python
推荐算法有基于协同的Collaboration Filtering:包括 user Based和item Based:基于内容 : Content Based 协同过滤包括基于物品的协同过滤和基于用户 ...
- Mahout分步式程序开发 基于物品的协同过滤ItemCF
http://blog.fens.me/hadoop-mahout-mapreduce-itemcf/ Hadoop家族系列文章,主要介绍Hadoop家族产品,常用的项目包括Hadoop, Hive, ...
- 基于物品的协同过滤推荐算法——读“Item-Based Collaborative Filtering Recommendation Algorithms” .
ligh@local-host$ ssh-copy-id -i ~/.ssh/id_rsa.pub root@192.168.0.3 基于物品的协同过滤推荐算法--读"Item-Based ...
- Music Recommendation System with User-based and Item-based Collaborative Filtering Technique(使用基于用户及基于物品的协同过滤技术的音乐推荐系统)【更新】
摘要: 大数据催生了互联网,电子商务,也导致了信息过载.信息过载的问题可以由推荐系统来解决.推荐系统可以提供选择新产品(电影,音乐等)的建议.这篇论文介绍了一个音乐推荐系统,它会根据用户的历史行为和口 ...
- Spark 基于物品的协同过滤算法实现
J由于 Spark MLlib 中协同过滤算法只提供了基于模型的协同过滤算法,在网上也没有找到有很好的实现,所以尝试自己实现基于物品的协同过滤算法(使用余弦相似度距离) 算法介绍 基于物品的协同过滤算 ...
- 基于物品的协同过滤算法(ItemCF)
最近在学习使用阿里云的推荐引擎时,在使用的过程中用到很多推荐算法,所以就研究了一下,这里主要介绍一种推荐算法—基于物品的协同过滤算法.ItemCF算法不是根据物品内容的属性计算物品之间的相似度,而是通 ...
- 基于物品的协同过滤ItemCF的mapreduce实现
文章的UML图比较好看..... 原文链接:www.cnblogs.com/anny-1980/articles/3519555.html 基于物品的协同过滤ItemCF 数据集字段: 1. Use ...
随机推荐
- MySQL 权限与用户表
1.授权时创建用户 grant all privileges on *.* to zhengwenqiang@localhost identified by 'zhengwenqiang'; 2.收回 ...
- Linux(CentOS6.5)下Nginx注册系统服务(启动、停止、重启、重载等)&设置开机自启
本文地址http://comexchan.cnblogs.com/ ,作者Comex Chan,尊重知识产权,转载请注明出处,谢谢! 完成了Nginx的编译安装后,仅仅是能支持Nginx最基本的功能, ...
- JS 中 cookie 的使用
1.cookie 是什么? ①.cookie 是存储于访问者计算机中的变量.每当一台计算机通过浏览器来访问某个页面时,那么就可以通过 JavaScript 来创建和读取 cookie. ②.实际上 c ...
- linux系统中,文件的三种特殊权限
背景介绍 在linux系统中,我们熟知有rwx三种权限,对应所有者,同组用户,其他用户三种用户的权限,一共9个位来指定一个文件的权限情况,通过chmod xxx 来更改权限属性,其中xxx是已八进制表 ...
- java多线程(四)-自定义线程池
当我们使用 线程池的时候,可以使用 newCachedThreadPool()或者 newFixedThreadPool(int)等方法,其实我们深入到这些方法里面,就可以看到它们的是实现方式是这样的 ...
- git强制push
Git 如何强制push? $ git push -u origin master –f 文章来源:刘俊涛的博客 地址:http://www.cnblogs.com/lovebing 欢迎关注,有 ...
- COM学习(二)——COM的注册和卸载
COM组件是跨语言的,组件被注册到注册表中,在加载时由加载函数在注册表中查找到对应模块的路径并进行相关加载.它的存储规则如下: 1. 在注册表的HKEY_CLASSES_ROOT中以模块名的方式保存着 ...
- 优雅的处理Redis访问超时
很长一段时间以来,一直在项目中使用Redis作为辅助存储,确切来说是利用Redis的内存存储,而不是将其作为缓存.比如常见的利用Set集合来判断某个数值是否存在,或者将来自不同请求的数据放在Redis ...
- 6.while loop
while 循环 有时候我们不确定需要循环几次.就像一个司机不知道自己需要什么时候加油一样.程序可以这样写: while petrol_filling: increase price show ...
- SQLAlchemy表操作和增删改查
一.SQLAlchemy介绍 SQLAlchemy是一个基于Python实现的ORM框架.该框架建立在 DB API之上,使用关系对象映射进行数据库操作,简言之便是:将类和对象转换成SQL,然后使用数 ...