Spark_总结一
Spark_总结一
1.Spark介绍
2.Spark运行模式(四种 )
| Local | 多用于测试 |
| Standalone | Spark自带的资源调度器(默认情况下就跑在这里面) |
| MeSOS | 资源调度器,同Hadoop中的YARN |
| YARN | 最具前景,公司里大部分都是 Spark on YRAN |
3.Spark内核之RDD的五大特性
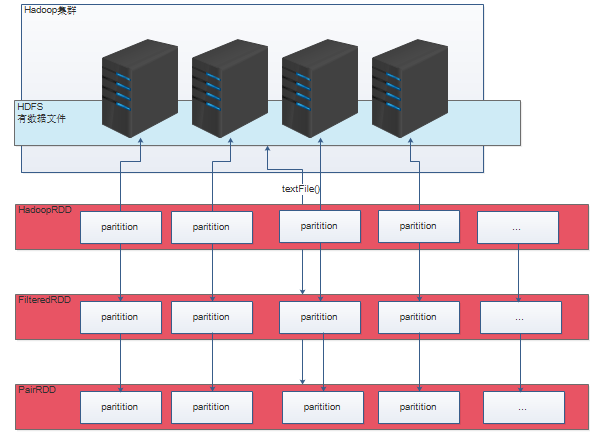
4.Spark运行机制
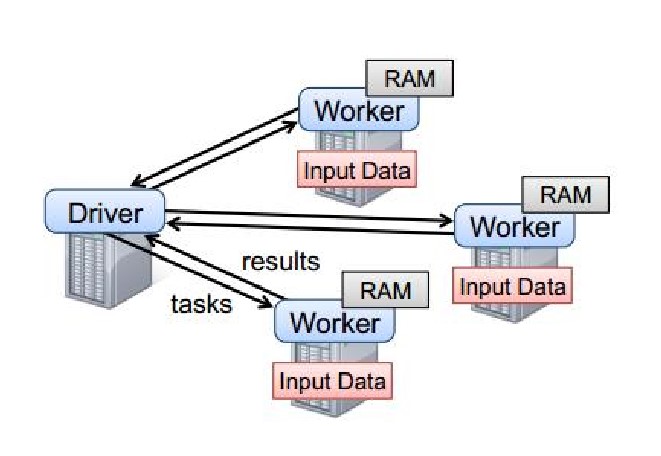
5.Spark运行时
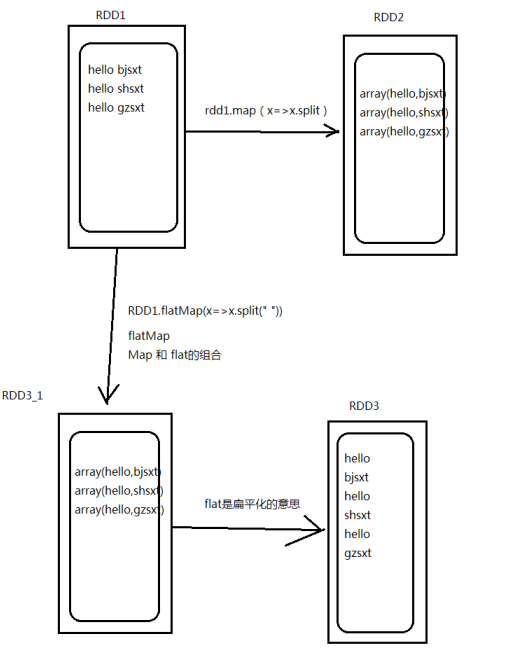
6.Spark算子--Transformations || Actions
|
Transformations || Actions 这两类算子的区别
|
||
|
Transformations
|
Transformations类的算子会返回一个新的RDD,懒执行 | |
|
Actions
|
Actions类的算子会返回基本类型或者一个集合,能够触发一个job的 执行,代码里面有多少个action类算子,那么就有多少个job | |
| Transformation类算子 | map | 输入一条,输出一条 将原来 RDD 的每个数据项通过 map 中的用户自定义函数映射转变为一个新的 元素。输入一条输出一条; |
| flatMap | 输入一条输出多条 先进行map后进行flat |
|
| mapPartitions | 与 map 函数类似,只不过映射函数的参数由 RDD 中的每一个元素变成了 RDD 中每一个分区的迭代器。将 RDD 中的所有数据通过 JDBC 连接写入数据库,如果使 用 map 函数,可能要为每一个元素都创建一个 connection,这样开销很大,如果使用 mapPartitions,那么只需要针对每一个分区建立一个 connection。 | |
| mapPartitionsWithIndex | ||
| filter | 依据条件过滤的算子 | |
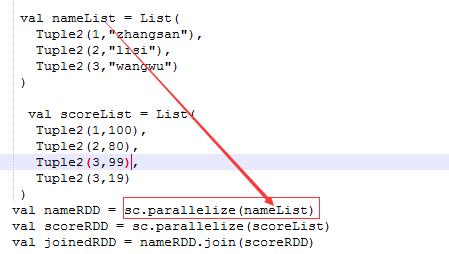
| join | 聚合类的函数,会产生shuffle,必须作用在KV格式的数据上 join 是将两个 RDD 按照 Key 相同做一次聚合;而 leftouterjoin 是依 据左边的 RDD 的 Key 进行聚 |
|
| union | 不会进行数据的传输,只不过将这两个的RDD标识一下 (代表属于一个RDD) |
|
| reduceByKey | 先分组groupByKey,后聚合根据传入的匿名函数聚合,适合在 map 端进行 combiner | |
| sortByKey | 依据 Key 进行排序,默认升序,参数设为 false 为降序 | |
| mapToPair | 进行一次 map 操作,然后返回一个键值对的 RDD。(所有的带 Pair 的算子返回值均为键值对) | |
| sortBy | 根据后面设置的参数排序 | |
| distinct | 对这个 RDD 的元素或对象进行去重操作 | |
| Actions类算子 | foreach | foreach 对 RDD 中的每个元素都应用函数操作,传入一条处理一条数据,返回值为空 |
| collect | 返回一个集合(RDD[T] => Seq[T]) collect 相当于 toArray, collect 将分布式的 RDD 返回为一个单机的 Array 数组。 |
|
| count | 一个 action 算子,计数功能,返回一个 Long 类型的对象 | |
| take(n) | 取前N条数据 | |
| save | 将RDD的数据存入磁盘或者HDFS | |
| reduce | 返回T和原来的类型一致(RDD[T] => T) | |
| foreachPartition | foreachPartition 也是根据传入的 function 进行处理,但不 同处在于 function 的传入参数是一个 partition 对应数据的 iterator,而不是直接使用 iterator 的 foreach。 |
7.Spark中WordCount演变流程图_Scala和Java代码
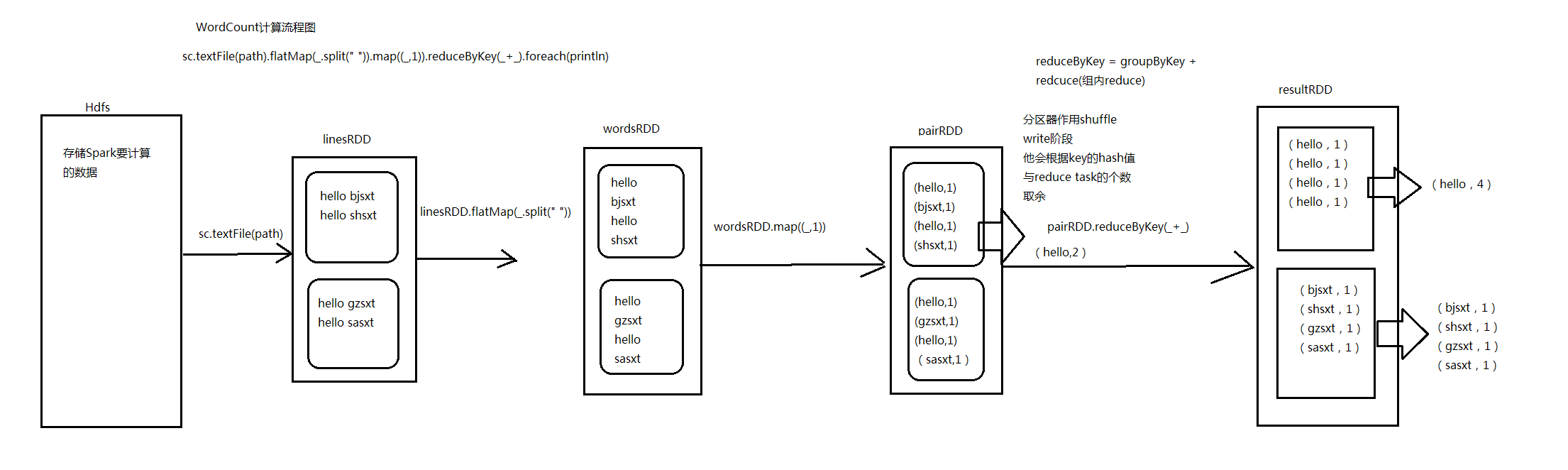
package com.hzf.spark.exerciseimport org.apache.spark.SparkConfimport org.apache.spark.SparkContext/*** 统计每一个单词出现的次数*/object WordCount{def main(args:Array[String]):Unit={/*** 设置Spark运行时候环境参数 ,可以在SparkConf对象里面设置* 我这个应用程序使用多少资源 appname 运行模式*/val conf =newSparkConf().setAppName("WordCount").setMaster("local")/*** 创建Spark的上下文 SparkContext** SparkContext是通往集群的唯一通道。* Driver*/val sc =newSparkContext(conf)//将文本中数据加载到linesRDD中val linesRDD = sc.textFile("userLog")//对linesRDD中每一行数据进行切割val wordsRDD = linesRDD.flatMap(_.split(" "))val pairRDD = wordsRDD.map{(_,1)}/*** reduceByKey是一个聚合类的算子,实际上是由两步组成** 1、groupByKey* 2、recuce*/val resultRDD = pairRDD.reduceByKey(_+_)/*(you,2)(Hello,2)(B,2)(a,1)(SQL,2)(A,3)(how,2)(core,2)(apple,1)(H,1)(C,1)(E,1)(what,2)(D,2)(world,2)*/resultRDD.foreach(println)/*(Spark,5)(A,3)(are,2)(you,2)(Hello,2)*/val sortRDD = resultRDD.map(x=>(x._2,x._1))val topN = sortRDD.sortByKey(false).map(x=>(x._2,x._1)).take(5)topN.foreach(println)}}

Spark_总结一的更多相关文章
- Spark_总结四
Spark_总结四 1.Spark SQL Spark SQL 和 Hive on Spark 两者的区别? spark on hive:hive只是作为元数据存储的角色,解析 ...
- Spark_总结五
Spark_总结五 1.Storm 和 SparkStreaming区别 Storm 纯实时的流式处理,来一条数据就立即进行处理 SparkStreaming ...
- Spark_总结七_troubleshooting
转载标明出处 http://www.cnblogs.com/haozhengfei/p/07ef4bda071b1519f404f26503fcba44.html Spark_总结七_troubles ...
- 创建spark_读取数据
在2.0版本之前,使用Spark必须先创建SparkConf和SparkContext,不过在Spark2.0中只要创建一个SparkSession就够了,SparkConf.SparkContext ...
- Spark_安装配置_运行模式
一.Spark支持的安装模式: 1.伪分布式(一台机器即可) 2.全分布式(至少需要3台机器) 二.Spark的安装配置 1.准备工作 安装Linux和JDK1.8 配置Linux:关闭防火墙.主机名 ...
- spark_运行spark-shell报错_javax.jdo.JDOFatalDataStoreException: Unable to open a test connection to the given database.
error: # ./spark-shell Caused by: javax.jdo.JDOFatalDataStoreException: Unable to open a test connec ...
- Scala 中object和class的区别
Scala中没有静态类型,但是有有“伴侣对象”,起到类似的作用. Scala中类对象中不可有静态变量和静态方法,但是提供了“伴侣对象”的功能:在和类的同一个文件中定义同名的Object对象:(须在同一 ...
- 【原创】大数据基础之Benchmark(2)TPC-DS
tpc 官方:http://www.tpc.org/ 一 简介 The TPC is a non-profit corporation founded to define transaction pr ...
- Spark-Streaming总结
文章出处:http://www.cnblogs.com/haozhengfei/p/e353daff460b01a5be13688fe1f8c952.html Spark_总结五 1.Storm 和 ...
随机推荐
- Nginx (二) Nginx的反向代理负载均衡以及日志切割
Nginx是一个高并发,高性能的服务器,可以进行反向代理以及网站的负载均衡.这些功能的运用都在配置文件中,也就是Nginx安装目录下的conf/nginx.conf. nginx.conf 1. 先来 ...
- 面向对象 初级版 (Preview) 未完
概述: 面向过程:根据业务逻辑从上到下写垒代码 函数式:将某功能代码封装到函数里,日后使用无需重复编写,直接调用韩顺即可. 面向对象: 对函数进行分类和封装,让开发'更快更强' 面向对象和面向过程的通 ...
- Mongodb常规操作【一】
Mongodb是一种比较常见的NOSQL数据库,数据库排名第四,今天介绍一下Net Core 下,常规操作. 首先下C# 版的驱动程序 "MongoDB.Driver",相关依赖包 ...
- js 闭包的用法详解
一.闭包 实现可重用的局部变量,且保护其不受污染的机制. 外层函数包裹受保护的变量和内层函数. 内层函数专门负责操作外层函数的局部变量. 将内层函数返回到外层函数外部,反复调用. 二.作用域 子函数会 ...
- python并发编程之多进程
一同步与异步 同步执行:一个进程在执行任务时,另一个进程必须等待执行完毕,才能继续执行 异步执行:一个进程在执行任务时,另一个进程无需等待其执行完毕就可以执行,当有消息返回时,系统会提醒后者进行处理, ...
- Windows程序设计笔记(二) 关于编写简单窗口程序中的几点疑惑
在编写窗口程序时主要是5个步骤,创建窗口类.注册窗口类.创建窗口.显示窗口.消息环的编写.对于这5个步骤为何要这样写,当初我不是太理解,学习到现在有些问题我基本上已经找到了答案,同时对于Windows ...
- Redis 部署主从哨兵 C#使用,实现自动获取redis缓存 实例1
源码示例下载链接: https://pan.baidu.com/s/1eTA63T4 密码: un96 实现目标:windows 下安装 一台master服务 一台salve redis服务器 并且哨 ...
- 说说那些经典的web前端面试题
阅读目录 JavaScript部分 JQurey部分 HTML/CSS部分 正则表达式 开发及性能优化部分 本篇收录了一些面试中经常会遇到的经典面试题以及自己面试过程中遇到的一些问题,并且都给出了我在 ...
- 关于jmeter工具使用的总结
今天总结下jmeter工具如何使用 先从最简单的说起 如何打开jemter 配置环境变量 接下来我们只要在dos窗口中输入 jmeter就能打开,这也告诉了我们配置环境变量的方便性 接下来介绍一下线程 ...
- 一个标准的WebView示例
xml <?xml version="1.0" encoding="utf-8"?> <LinearLayout xmlns:android= ...