hdfs存储与数据同步
两个hadoop集群之间同步数据
实例为dws的 store_wt_d表
一 文件拷贝
hadoop distcp -update -skipcrccheck hdfs://10.8.31.14:8020/user/hive/warehouse/dws.db/store_wt_d/ hdfs://10.8.22.40:8020/user/hive/warehouse/dws.db/store_wt_d/
-skipcrccheck 跳过检验
二 找到源地址对应的文件的数据库以及表的结构
use dws
show create table store_wt_d;
三 在新的集群上面创建对应的库表
辅助刚刚那台语句 修改对应集群的存储地址
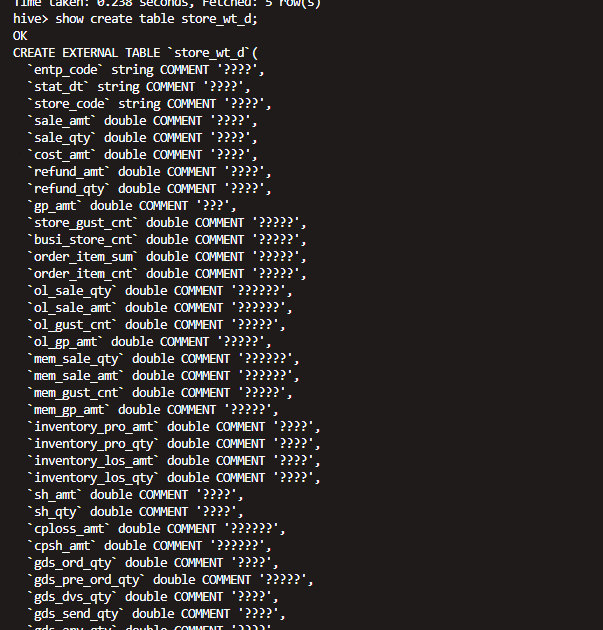
CREATE EXTERNAL TABLE `store_wt_d`(
`entp_code` string COMMENT '????',
`stat_dt` string COMMENT '????',
`store_code` string COMMENT '????',
`sale_amt` double COMMENT '????',
`sale_qty` double COMMENT '????',
`cost_amt` double COMMENT '????',
`refund_amt` double COMMENT '????',
`refund_qty` double COMMENT '????',
`gp_amt` double COMMENT '???',
`store_gust_cnt` double COMMENT '?????',
`busi_store_cnt` double COMMENT '?????',
`order_item_sum` double COMMENT '?????',
`order_item_cnt` double COMMENT '?????',
`ol_sale_qty` double COMMENT '??????',
`ol_sale_amt` double COMMENT '??????',
`ol_gust_cnt` double COMMENT '?????',
`ol_gp_amt` double COMMENT '?????',
`mem_sale_qty` double COMMENT '??????',
`mem_sale_amt` double COMMENT '??????',
`mem_gust_cnt` double COMMENT '?????',
`mem_gp_amt` double COMMENT '?????',
`inventory_pro_amt` double COMMENT '????',
`inventory_pro_qty` double COMMENT '????',
`inventory_los_amt` double COMMENT '????',
`inventory_los_qty` double COMMENT '????',
`sh_amt` double COMMENT '????',
`sh_qty` double COMMENT '????',
`cploss_amt` double COMMENT '??????',
`cpsh_amt` double COMMENT '??????',
`gds_ord_qty` double COMMENT '????',
`gds_pre_ord_qty` double COMMENT '?????',
`gds_dvs_qty` double COMMENT '????',
`gds_send_qty` double COMMENT '????',
`gds_arv_qty` double COMMENT '????',
`gds_arv_amt` double COMMENT '????',
`gds_take_qty` double COMMENT '????',
`rtn_bk_ps_qty` double COMMENT '??????',
`gds_need_qty` double COMMENT '????',
`stk_amt` double COMMENT '????',
`stk_qty` double COMMENT '????',
`ini_stk_qty` double COMMENT '??????',
`ini_stk_amt` double COMMENT '??????',
`fnl_stk_qty` double COMMENT '??????',
`fnl_stk_amt` double COMMENT '??????',
`iwh_as_qty` double COMMENT '????????',
`iwh_as_amt` double COMMENT '????????',
`iwh_as_gp_amt` double COMMENT '?????????',
`gds_arv_iwh_qty` double COMMENT '??????',
`gds_arv_iwh_amt` double COMMENT '??????',
`gds_arv_iwh_gp_amt` double COMMENT '???????',
`transfer_iwh_qty` double COMMENT '??????',
`transfer_iwh_amt` double COMMENT '??????',
`transfer_iwh_gp_amt` double COMMENT '???????',
`iwh_io_qty` double COMMENT '??????',
`iwh_io_amt` double COMMENT '??????',
`iwh_io_gp_amt` double COMMENT '???????',
`iwh_tot_sum_qty` double COMMENT '???????',
`iwh_tot_sum_amt` double COMMENT '???????',
`iwh_tot_sum_gp_amt` double COMMENT '????????',
`owh_as_qty` double COMMENT '????????',
`owh_as_amt` double COMMENT '????????',
`owh_as_gp_amt` double COMMENT '?????????',
`stk_bs_qty` double COMMENT '??????',
`stk_bs_amt` double COMMENT '??????',
`stk_bs_gp_amt` double COMMENT '???????',
`owh_pos_qty` double COMMENT '??????',
`owh_pos_amt` double COMMENT '??????',
`owh_pos_gp_amt` double COMMENT '???????',
`owh_rs_qty` double COMMENT '????????',
`owh_rs_amt` double COMMENT '????????',
`owh_rs_gp_amt` double COMMENT '?????????',
`transfer_owh_qty` double COMMENT '??????',
`transfer_owh_amt` double COMMENT '??????',
`transfer_owh_gp_amt` double COMMENT '???????',
`owh_ly_qty` double COMMENT '??????',
`owh_ly_amt` double COMMENT '??????',
`owh_ly_gp_amt` double COMMENT '???????',
`owh_sc_qty` double COMMENT '??????',
`owh_sc_amt` double COMMENT '??????',
`owh_sc_gp_amt` double COMMENT '???????',
`owh_tot_sum_qty` double COMMENT '???????',
`owh_tot_sum_amt` double COMMENT '???????',
`owh_tot_sum_gp_amt` double COMMENT '????????',
`pk_qty` double COMMENT '????',
`pk_amt` double COMMENT '????',
`pk_gp_amt` double COMMENT '?????',
`pk_tot_sum_qty` double COMMENT '???????',
`pk_tot_sum_amt` double COMMENT '???????',
`pk_tot_sum_gp_amt` double COMMENT '????????',
`stk_item_cnt` double COMMENT '?????',
`unsold_gds_cnt` double COMMENT '?????',
`trgt_sale_amt` double COMMENT '??????',
`trgt_gust_cnt` double COMMENT '?????',
`trgt_gp_amt` double COMMENT '?????',
`synctime` string COMMENT '????')
PARTITIONED BY (
`part_date` string)
ROW FORMAT SERDE
'org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe'
WITH SERDEPROPERTIES (
'field.delim'='-128',
'line.delim'='\n',
'serialization.format'='-128')
STORED AS INPUTFORMAT
'org.apache.hadoop.hive.ql.io.parquet.MapredParquetInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat'
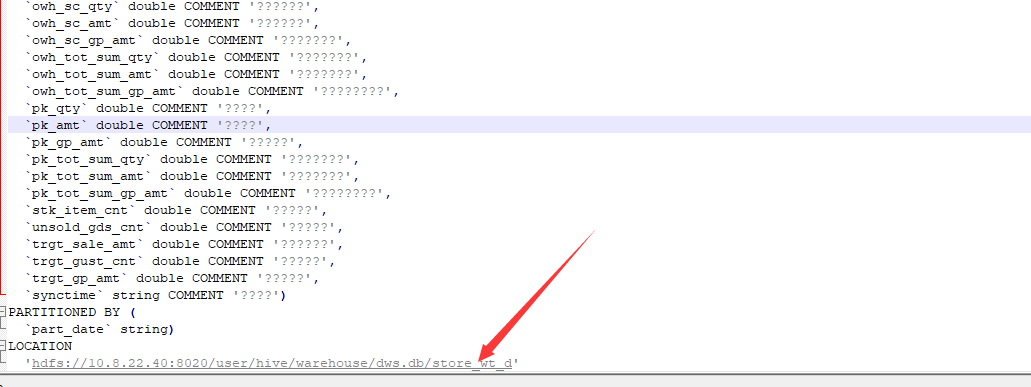
LOCATION
'hdfs://10.8.22.40:8020/user/hive/warehouse/dws.db/store_wt_d'
四 修复表
msck repair table store_wt_d;
五 查看表情况
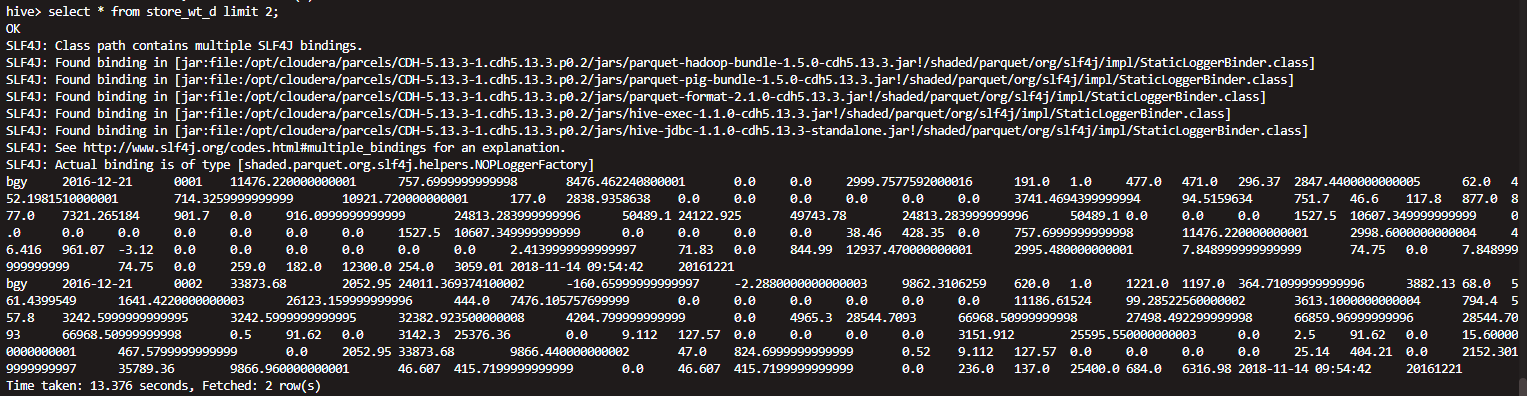
正常
hive--hdfs存储格式测试
hive默认的存储格式是text
测试 如果一个parquet格式的hive表数据导入到一个text的表之后会有什么情况
创建外表,默认为text格式 但是导入的数据为parquet格式

查看数据发现是乱码
另外如果数据的存储格式是parquet 直接去hdfs上查看也会乱码

如果是text格式存储的
正常

不同格式的相同数据之间的存储对比
上面为parquet压缩的,后面的为没有压缩的(text格式的)
使用压缩
CREATE TABLE `store_wt_d2` STORED AS PARQUET TBLPROPERTIES('parquet.compression'='SNAPPY') as select * from store_wt_d
再次查看 发现确实量小了不少
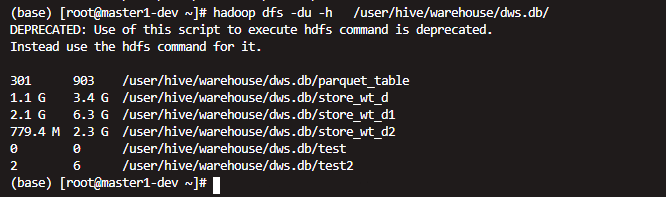
但是时间也明显更长了

创建parquet table :
create table mytable(a int,b int) STORED AS PARQUET;
创建带压缩的parquet table:
create table mytable(a int,b int) STORED AS PARQUET TBLPROPERTIES('parquet.compression'='SNAPPY');
如果原来创建表的时候没有指定压缩,后续可以通过修改表属性的方式添加压缩:
ALTER TABLE mytable SET TBLPROPERTIES ('parquet.compression'='SNAPPY');
或者在写入的时候set parquet.compression=SNAPPY;
不过只会影响后续入库的数据,原来的数据不会被压缩,需要重跑原来的数据。
采用压缩之后大概可以降低1/3的存储大小。
hdfs存储与数据同步的更多相关文章
- Windows下cwrsync客户端与rsync群辉存储客户端数据同步
cwRsync简介 cwRsync是Rsync在Windows上的实现版本,Rsync通过使用特定算法的文件传输技术,可以在网络上传输只修改了的文件. cwRsync主要用于Windows上的远程文件 ...
- 从 RAID 到 Hadoop Hdfs 『大数据存储的进化史』
我们都知道现在大数据存储用的基本都是 Hadoop Hdfs ,但在 Hadoop 诞生之前,我们都是如何存储大量数据的呢?这次我们不聊技术架构什么的,而是从技术演化的角度来看看 Hadoop Hdf ...
- 用hdfs存储海量的视频数据的设计思路
用hdfs存储海量的视频数据 存储海量的视频数据,主要考虑两个因素:如何接收视频数据和如何存储视频数据. 我们要根据数据block在集群上的位置分配计算量,要充分利用带宽的优势. 1.接收视频数据 将 ...
- 美团DB数据同步到数据仓库的架构与实践
背景 在数据仓库建模中,未经任何加工处理的原始业务层数据,我们称之为ODS(Operational Data Store)数据.在互联网企业中,常见的ODS数据有业务日志数据(Log)和业务DB数据( ...
- DB 数据同步到数据仓库的架构与实践
背景 在数据仓库建模中,未经任何加工处理的原始业务层数据,我们称之为ODS(Operational Data Store)数据.在互联网企业中,常见的ODS数据有业务日志数据(Log)和业务DB数据( ...
- 增量数据同步中间件DataLink分享(已开源)
项目介绍 名称: DataLink['deitə liŋk]译意: 数据链路,数据(自动)传输器语言: 纯java开发(JDK1.8+)定位: 满足各种异构数据源之间的实时增量同步,一个分布式.可扩展 ...
- HDFS中的数据块(Block)
我们在分布式存储原理总结中了解了分布式存储的三大特点: 数据分块,分布式的存储在多台机器上 数据块冗余存储在多台机器以提高数据块的高可用性 遵从主/从(master/slave)结构的分布式存储集群 ...
- 环境篇:数据同步工具DataX
环境篇:数据同步工具DataX 1 概述 https://github.com/alibaba/DataX DataX是什么? DataX 是阿里巴巴集团内被广泛使用的离线数据同步工具/平台,实现包括 ...
- 使用Observer实现HBase到Elasticsearch的数据同步
最近在公司做统一日志收集处理平台,技术选型肯定要选择elasticsearch,因为可以快速检索系统日志,日志问题排查及功业务链调用可以被快速检索,公司各个应用的日志有些字段比如说content是不需 ...
随机推荐
- display:flex 布局详解(2)
1. flex设置元素垂直居中对齐 在之前的一篇文章中记载过如何垂直居中对齐,方法有很多,但是在学习了flex布局之后,垂直居中更加容易实现 HTML代码: <div class=" ...
- linux下编译安装ACE-6.4.2(adpative communication environment)
1.环境 CentOS-6.5-x86_64-bin-DVD1.iso VMware_workstation_full_12.5.2 (2).exe ACE-6.4.2.tar.gz 下载链接:htt ...
- SOA相关资料
http://www.cnblogs.com/mushroom/p/4369032.html
- 简单分析一下socket中的bind
[转自]守夜者 灵感来自于积累 的博客 [原文链接]http://www.cnblogs.com/nightwatcher/archive/2011/07/03/2096717.html在最开始接触b ...
- 【数学建模】线性规划各种问题的Python调包方法
关键词:Python.调包.线性规划.指派问题.运输问题.pulp.混合整数线性规划(MILP) 注:此文章是线性规划的调包实现,具体步骤原理请搜索具体解法. 本文章的各个问题可能会采用多种调用方 ...
- Sql 语句收集——行转列
SQL行转列汇总 PIVOT用于将列值旋转为列名(即行转列),在SQL Server 2000可以用聚合函数配合CASE语句实现 PIVOT的一般语法是:PIVOT(聚合函数(列) FOR 列 in ...
- 在Linux虚拟机里开启Apache服务
首先第一步我们配置环境:把yum与Linux ping通 1.我们来下载apache服务,输入:yum install httpd * 2.安装完毕之后默认是死的,要给他启动一下,输入命令:syste ...
- 一次JDBC支持表情存储的配置过程
公司的一个项目,一开始没有考虑到内容字段支持表情,有一个接入方的内容含有表情要支持下 项目是基于Springboot的. 方案1先尝试直接配置数据库连接 shardingsphere: datasou ...
- 服务器:消息18456,级别16,状态1 用户‘sa’登录失败解决方法
无法连接到服务器**: 服务器:消息18456,级别16,状态1 [Microsoft][ODBC SQL Server Driver][Sql server] 用户 'sa ...
- pyton 类(4) 静态方法
class Cat(): tag = ' 猫科动物 ' def __init__(self, name): self.name = name @staticmethod def breah(): pr ...