013 MapReduce八股文的wordcount应用
一:Mapreduce编程模型
1.介绍
解决海量数据的计算问题。
》map:映射
处理不同机器上的块的数据,一个map处理一个块。
》reduce:汇总
将map的结果进行汇总合并
2.一个简单的MR程序
map
reduce
input
output
3.在处理中,格式的流向
《key,value》
4.需要思考的问题
处理的数据是什么样的
map的输出格式
reduce的输出数据格式
二:完成Wordcount的程序
1.数据的输入格式说明(默认方式)
Hadoop Yarn
》key:代表偏移量
》value:这一行的值
》<0,Hadoop Yarn>
2.map处理的数据格式
Hadoop Yarn
Hadoop Spark
分割单词
每出现一次就这样处理一下
<Hadoop,1> <Yarn,1>
<Hadoop,1> <Spark,1>
3.reduce处理的数据格式
将相同key的value值加在一起就是单词出现的次数
4.新建包以及类

5.将程序分成三块的框架
Mapper类,Reducer类,Driver的run方法
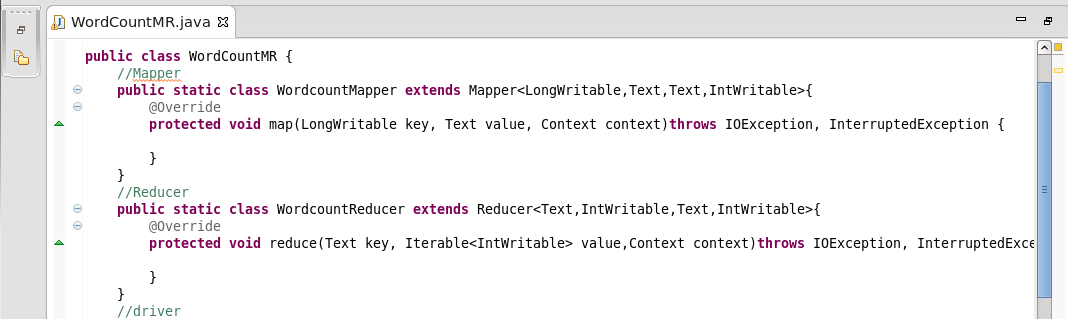
3.将map与reduce相结合,并在main中运行
分为四大部分:input,output,mapper,reducer
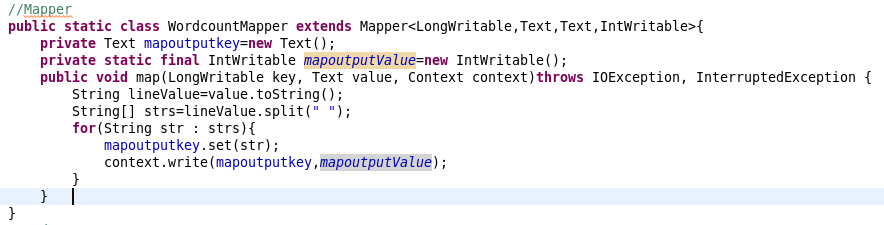
4.Mapper类
将value转化为字符串
使用空格分隔
使用context输出键值对。
5.Reducer类

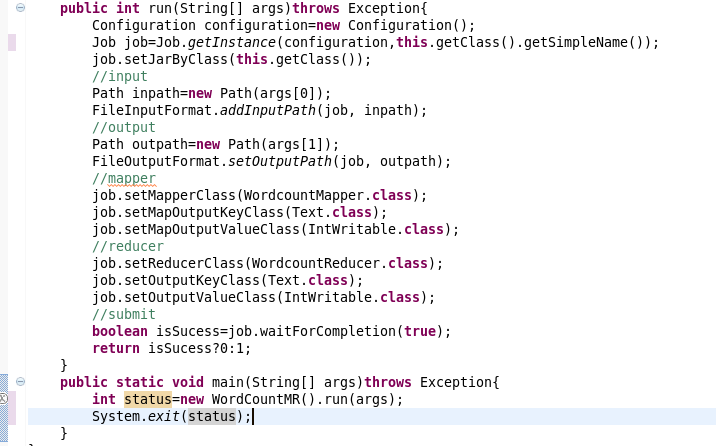
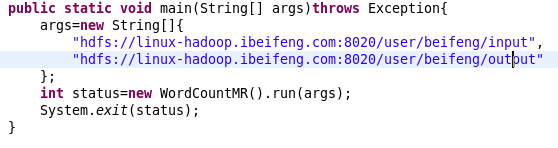
6.在main()中写入文件操作系统的路径。
7.结果
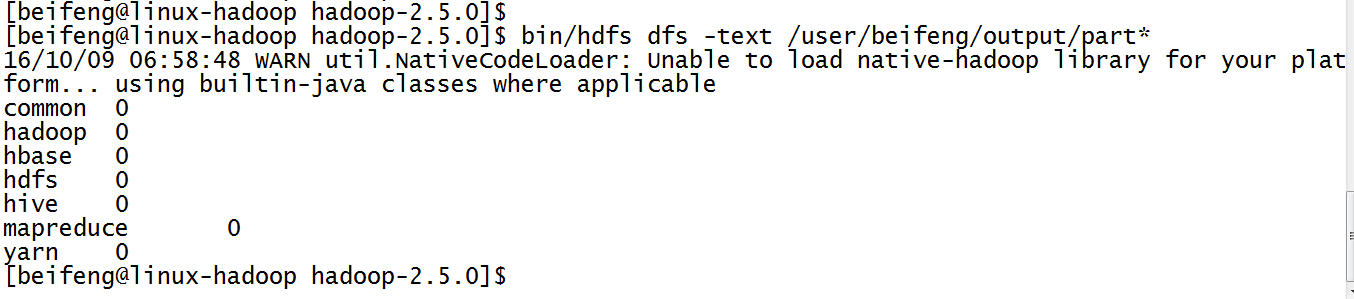
8.出现的结果有些问题,因为没有计数。

IntWritable(1),其参数为1.表示每出现一次就记录一次。
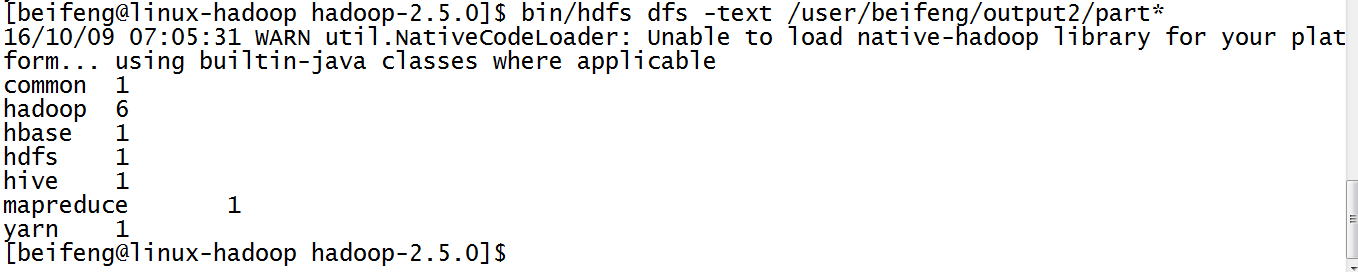
9.最新的结果
三:打包在yarn上运行
10.因为需要把jar分发到节点上,所以需要修改

11.打jar包
12.选择jar包的路径

13.选择jar运行的主类
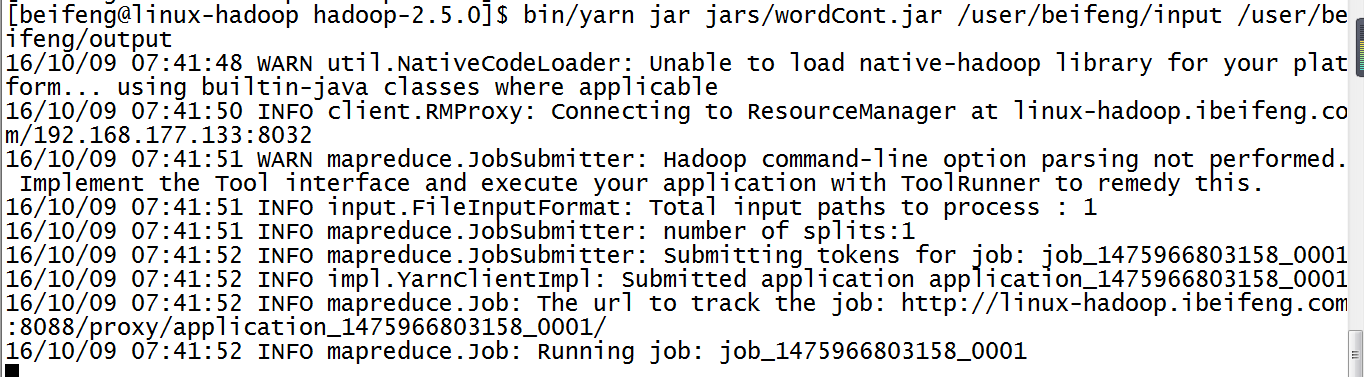
14.运行jar在yarn上
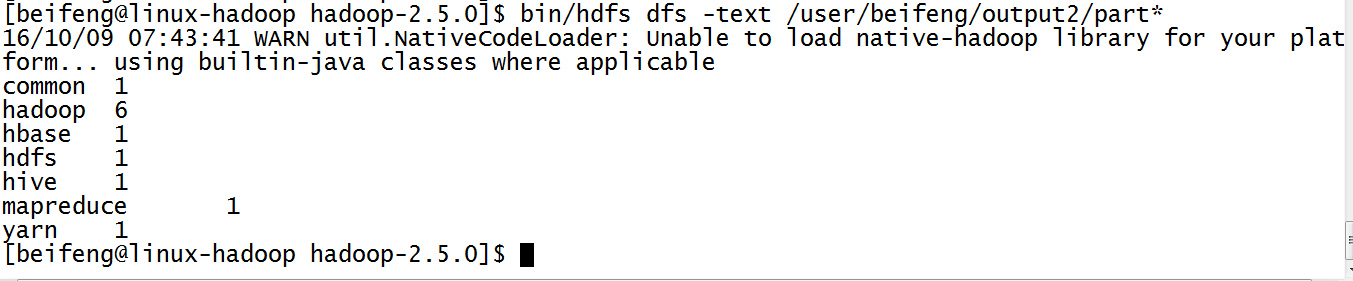
15.运行结果
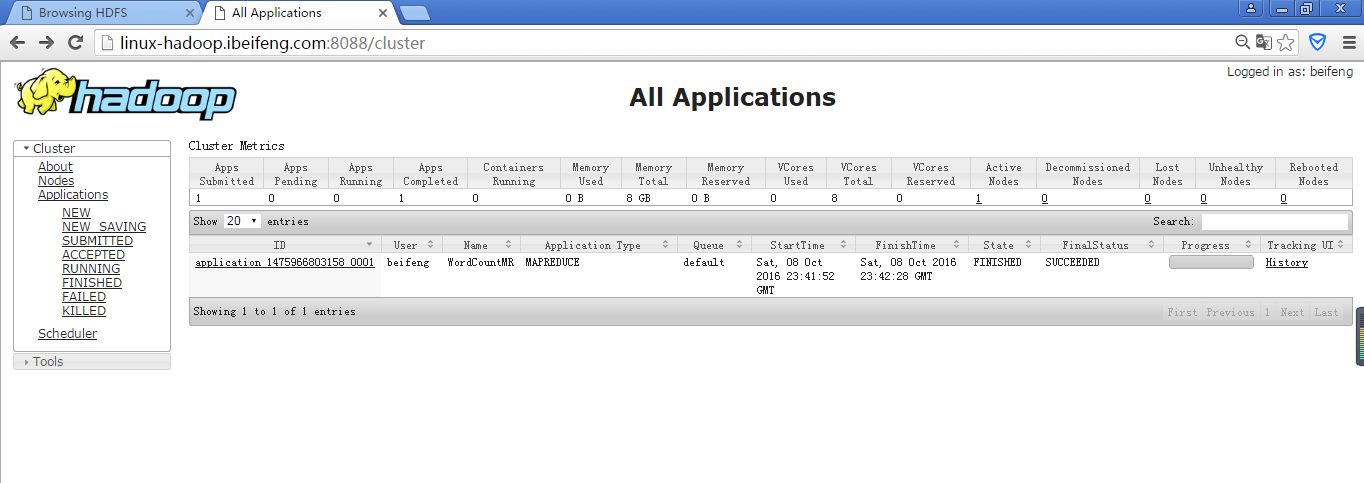
16.在yarn的管理界面上看
17.在Configuration中search一下mapper
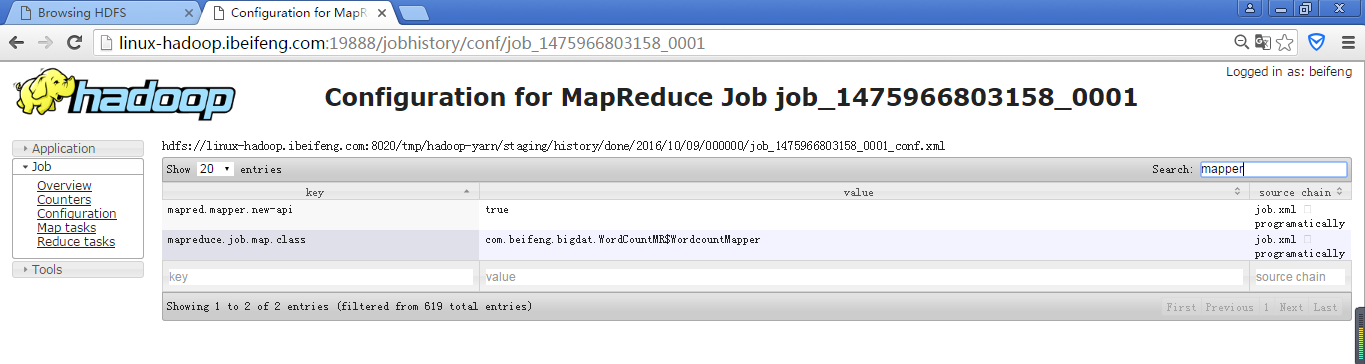
同样可以reduce,或者fileoutput等查阅一些参数。
013 MapReduce八股文的wordcount应用的更多相关文章
- MapReduce编程之wordcount
实践 MapReduce编程之wordcount import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Fi ...
- mapreduce入门之wordcount注释详解
mapreduce版本:0.2.0之前 说明: 该注释为之前学习时找到的一篇,现在只是在入门以后对该注释做了一些修正以及添加. 由于版本问题,该代码并没有在集群环境中运行,只将其做为理解mapredu ...
- mapreduce程序编写(WordCount)
折腾了半天.终于编写成功了第一个自己的mapreduce程序,并通过打jar包的方式运行起来了. 运行环境: windows 64bit eclipse 64bit jdk6.0 64bit 一.工程 ...
- 2 weekend110的mapreduce介绍及wordcount + wordcount的编写和提交集群运行 + mr程序的本地运行模式
把我们的简单运算逻辑,很方便地扩展到海量数据的场景下,分布式运算. Map作一些,数据的局部处理和打散工作. Reduce作一些,数据的汇总工作. 这是之前的,weekend110的hdfs输入流之源 ...
- Mapreduce概述和WordCount程序
一.Mapreduce概述 Mapreduce是分布式程序编程框架,也是分布式计算框架,它简化了开发! Mapreduce将用户编写的业务逻辑代码和自带默认组合整合成一个完整的分布式运算程序,并发的运 ...
- 运行第一个MapReduce程序,WordCount
1.安装Eclipse 安装后如果无法启动重新配置Java路径(如果之前配置了Java) 2.下载安装eclipse的hadoop插件 注意版本对应,放到/uer/lib/eclipse/plugin ...
- MapReduce 编程模型 & WordCount 示例
学习大数据接触到的第一个编程思想 MapReduce. 前言 之前在学习大数据的时候,很多东西很零散的做了一些笔记,但是都没有好好去整理它们,这篇文章也是对之前的笔记的整理,或者叫输出吧.一来是加 ...
- Hadoop学习之路(5)Mapreduce程序完成wordcount
程序使用的测试文本数据: Dear River Dear River Bear Spark Car Dear Car Bear Car Dear Car River Car Spark Spark D ...
- 用python写MapReduce函数——以WordCount为例
尽管Hadoop框架是用java写的,但是Hadoop程序不限于java,可以用python.C++.ruby等.本例子中直接用python写一个MapReduce实例,而不是用Jython把pyth ...
随机推荐
- ettercap 模块使用
Ettercap的过滤规则只能经过编译之后才能由-F参数载入到ettercap中使用. 编译过滤规则命令是:etterfilter filter.ecf -o filter.ef. 过滤规则的语法与C ...
- mysql案例-sysbench安装测试
一 地址 githup地址https://github.com/akopytov/sysbench二 版本 sysbench 1.0.15 curl -s https://packagecloud.i ...
- 使用sqlmap中tamper脚本绕过waf
使用sqlmap中tamper脚本绕过waf 刘海哥 · 2015/02/02 11:26 0x00 背景 sqlmap中的tamper脚本来对目标进行更高效的攻击. 由于乌云知识库少了sqlmap- ...
- OKVIS 代码框架
1. okvis_app_synchronous.cpp 在此文件中 okvis 对象为 okvis_estimator,是类 okvis::ThreadedKFVio 的实例化对象. 数据输入接口是 ...
- jquery菜单插件
原理很简单. 涉及到知识点: 1.jquery的position注意这里是jquery的position,不是css的position offset的概念 2.>的概念. 3..ulh>l ...
- C++学习8-面向对象编程基础(模板)
模板 模板是一种工具,模板可以使程序员能建立具有通用类型的函数库与类库: 模板具有两种不同的形式: 函数模板 类模板 函数模板 当一个add()函数接收两个参数,因为某种特定情况,所传入的实参数据类型 ...
- 【转】Shell编程进阶篇(完结)
[转]Shell编程进阶篇(完结) 1.1 for循环语句 在计算机科学中,for循环(英语:for loop)是一种编程语言的迭代陈述,能够让程式码反复的执行. 它跟其他的循环,如while循环,最 ...
- c语言的重构、清理与代码分析图形化浏览工具: CScout
网址: https://www.spinellis.gr/cscout/ https://www2.dmst.aueb.gr/dds/cscout/index.html https://github. ...
- python调用win32com.client的GetObject查找进程信息及服务信息
为何不用wmi呢?因为执行很慢,为啥不用winreg?因为winreg在批量获取及遍历服务方面很不方便,于是采用这方法 该方法同命令行下的wmic执行 获取服务信息 #coding=utf8 from ...
- 【转】OpenCV对图片中的RotatedRect进行填充
函数名:full_rotated_rect 函数参数: image输入图像,rect希望在图像中填充的RotatedRect,color填充的颜色 主要的思路是:先找到RotatedRect的四个顶点 ...