013 MapReduce八股文的wordcount应用
一:Mapreduce编程模型
1.介绍
解决海量数据的计算问题。
》map:映射
处理不同机器上的块的数据,一个map处理一个块。
》reduce:汇总
将map的结果进行汇总合并
2.一个简单的MR程序
map
reduce
input
output
3.在处理中,格式的流向
《key,value》
4.需要思考的问题
处理的数据是什么样的
map的输出格式
reduce的输出数据格式
二:完成Wordcount的程序
1.数据的输入格式说明(默认方式)
Hadoop Yarn
》key:代表偏移量
》value:这一行的值
》<0,Hadoop Yarn>
2.map处理的数据格式
Hadoop Yarn
Hadoop Spark
分割单词
每出现一次就这样处理一下
<Hadoop,1> <Yarn,1>
<Hadoop,1> <Spark,1>
3.reduce处理的数据格式
将相同key的value值加在一起就是单词出现的次数
4.新建包以及类

5.将程序分成三块的框架
Mapper类,Reducer类,Driver的run方法
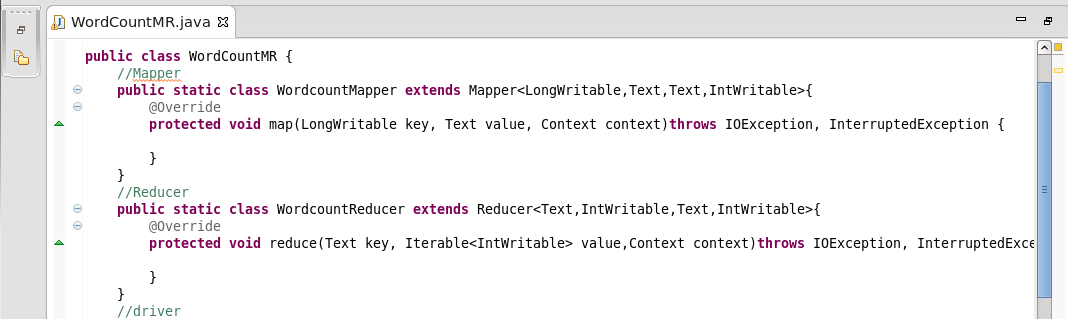
3.将map与reduce相结合,并在main中运行
分为四大部分:input,output,mapper,reducer
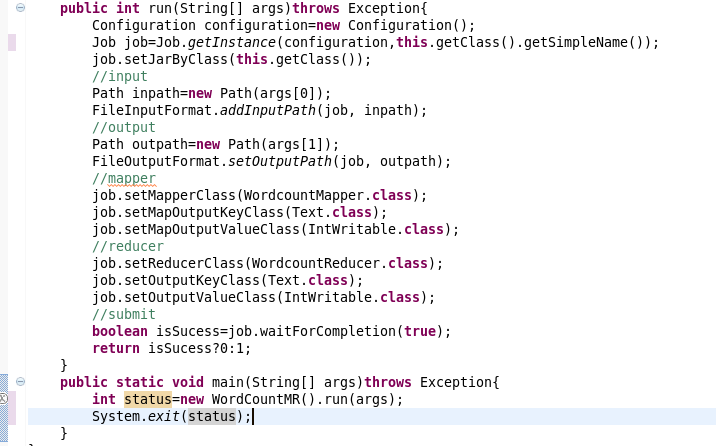
4.Mapper类
将value转化为字符串
使用空格分隔
使用context输出键值对。
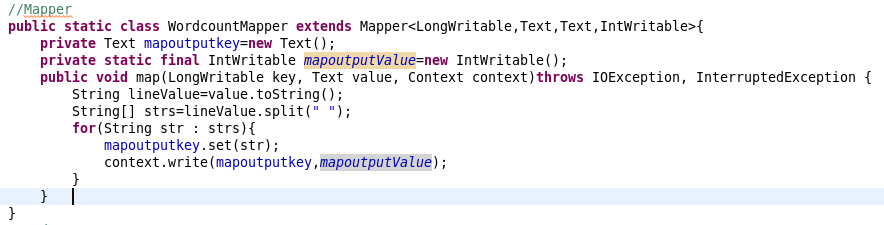
5.Reducer类

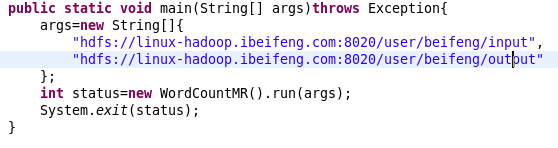
6.在main()中写入文件操作系统的路径。
7.结果
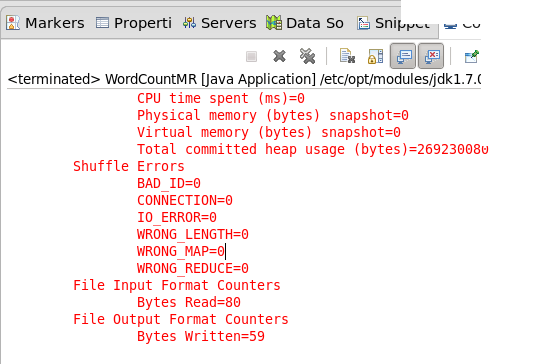
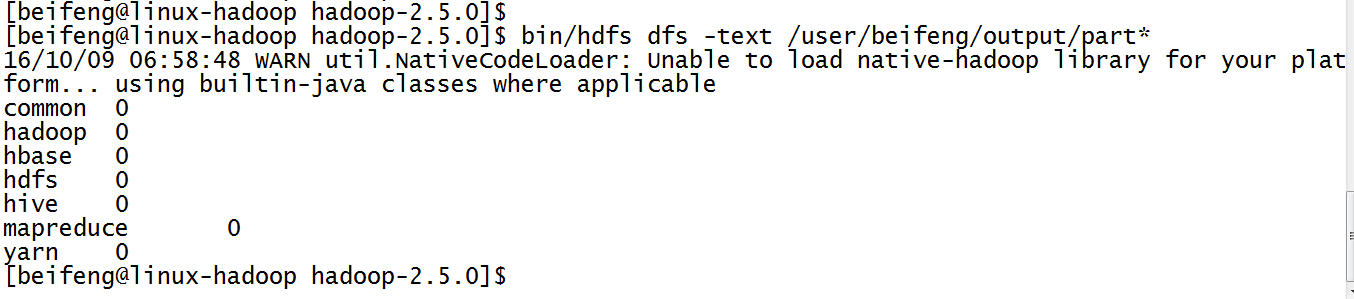
8.出现的结果有些问题,因为没有计数。

IntWritable(1),其参数为1.表示每出现一次就记录一次。
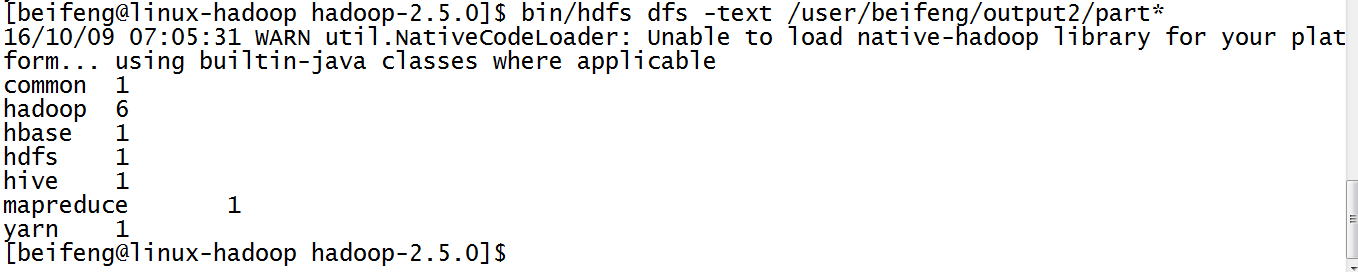
9.最新的结果
三:打包在yarn上运行
10.因为需要把jar分发到节点上,所以需要修改

11.打jar包
12.选择jar包的路径

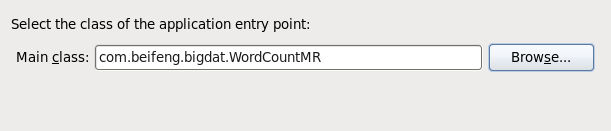
13.选择jar运行的主类
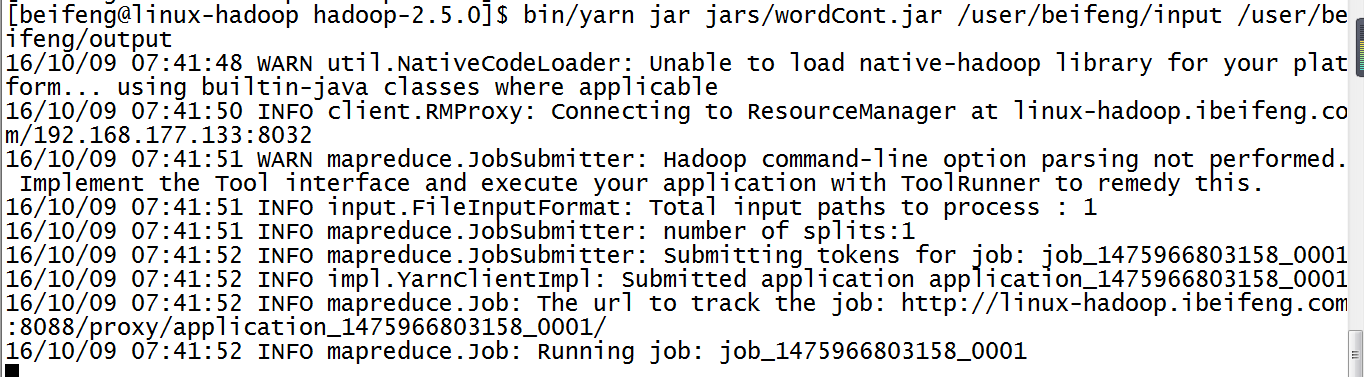
14.运行jar在yarn上
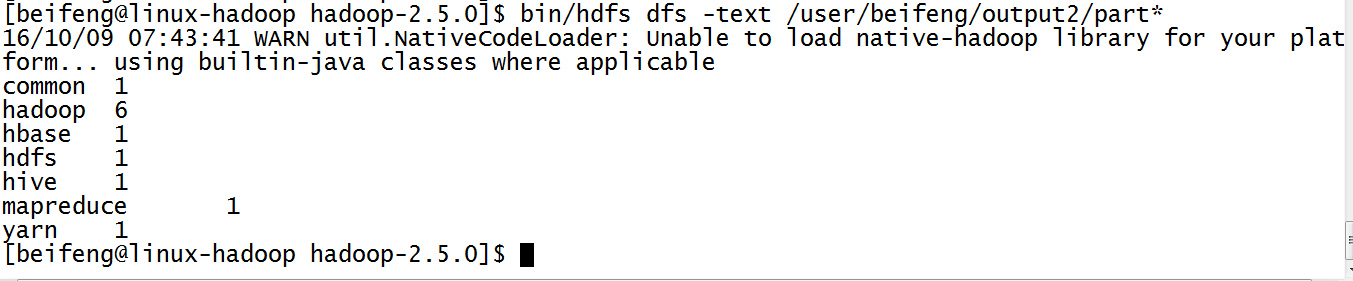
15.运行结果
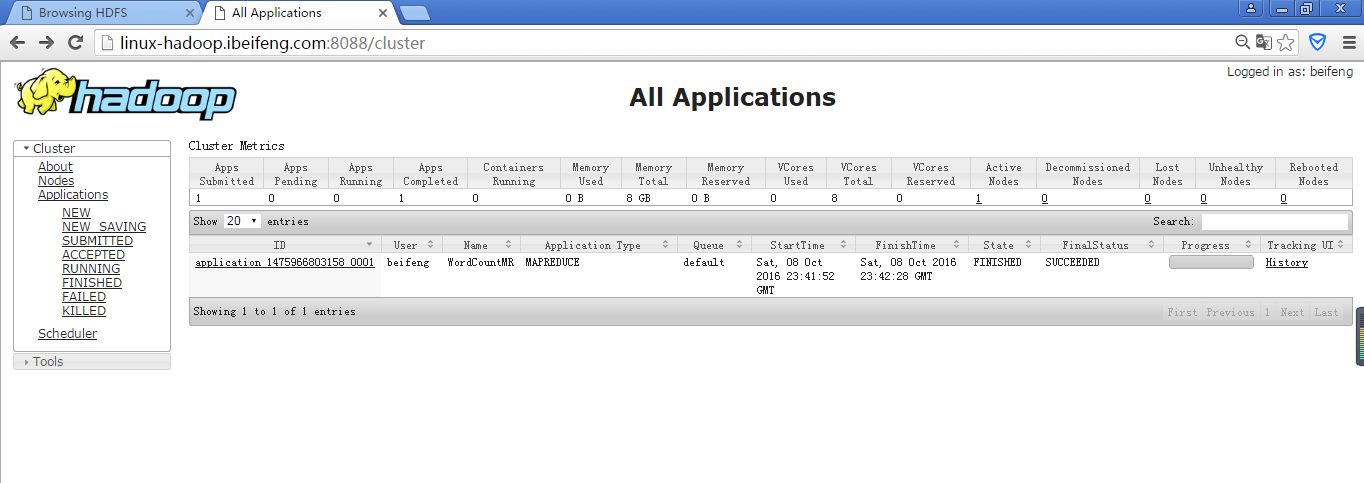
16.在yarn的管理界面上看
17.在Configuration中search一下mapper
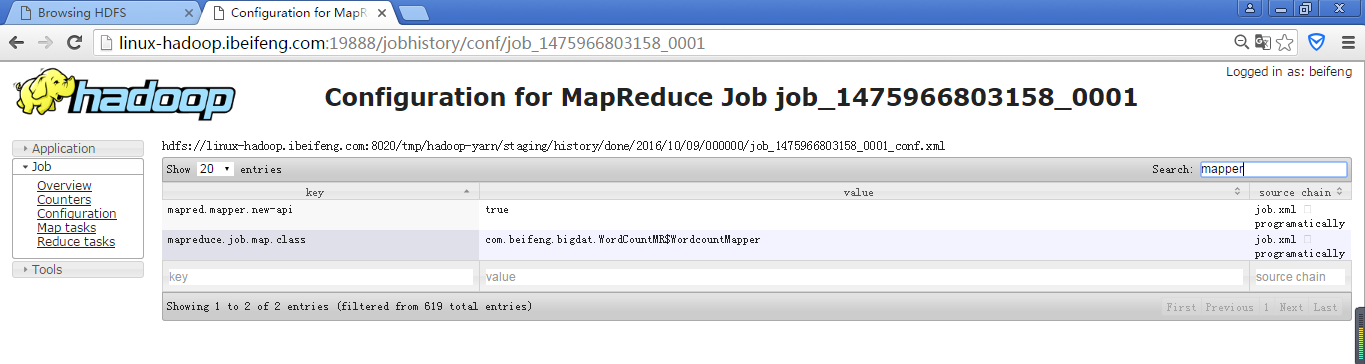
同样可以reduce,或者fileoutput等查阅一些参数。
013 MapReduce八股文的wordcount应用的更多相关文章
- MapReduce编程之wordcount
实践 MapReduce编程之wordcount import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Fi ...
- mapreduce入门之wordcount注释详解
mapreduce版本:0.2.0之前 说明: 该注释为之前学习时找到的一篇,现在只是在入门以后对该注释做了一些修正以及添加. 由于版本问题,该代码并没有在集群环境中运行,只将其做为理解mapredu ...
- mapreduce程序编写(WordCount)
折腾了半天.终于编写成功了第一个自己的mapreduce程序,并通过打jar包的方式运行起来了. 运行环境: windows 64bit eclipse 64bit jdk6.0 64bit 一.工程 ...
- 2 weekend110的mapreduce介绍及wordcount + wordcount的编写和提交集群运行 + mr程序的本地运行模式
把我们的简单运算逻辑,很方便地扩展到海量数据的场景下,分布式运算. Map作一些,数据的局部处理和打散工作. Reduce作一些,数据的汇总工作. 这是之前的,weekend110的hdfs输入流之源 ...
- Mapreduce概述和WordCount程序
一.Mapreduce概述 Mapreduce是分布式程序编程框架,也是分布式计算框架,它简化了开发! Mapreduce将用户编写的业务逻辑代码和自带默认组合整合成一个完整的分布式运算程序,并发的运 ...
- 运行第一个MapReduce程序,WordCount
1.安装Eclipse 安装后如果无法启动重新配置Java路径(如果之前配置了Java) 2.下载安装eclipse的hadoop插件 注意版本对应,放到/uer/lib/eclipse/plugin ...
- MapReduce 编程模型 & WordCount 示例
学习大数据接触到的第一个编程思想 MapReduce. 前言 之前在学习大数据的时候,很多东西很零散的做了一些笔记,但是都没有好好去整理它们,这篇文章也是对之前的笔记的整理,或者叫输出吧.一来是加 ...
- Hadoop学习之路(5)Mapreduce程序完成wordcount
程序使用的测试文本数据: Dear River Dear River Bear Spark Car Dear Car Bear Car Dear Car River Car Spark Spark D ...
- 用python写MapReduce函数——以WordCount为例
尽管Hadoop框架是用java写的,但是Hadoop程序不限于java,可以用python.C++.ruby等.本例子中直接用python写一个MapReduce实例,而不是用Jython把pyth ...
随机推荐
- SQL——sql年龄段查询
select * from 表 p where p.gender <> '男' ) ) select * ) ) 查询出所有年龄在15~49岁的非男性的信息
- 设置PHPStorm 注释
/** * Desc: xxx#if (${NAME}) * Class: ${NAME}#end#if (${NAMESPACE}) * Package: ${NAMESPACE}#end * Us ...
- ubuntu16.10安装docker17.03.0-ce并配置国内源和加速器
说明:这个针对docker-ce安装,ce和ee的区别是前者是社区版,后者是企业版 1. 配置Ubuntu的源,不然慢的去哭吧.参考http://cn.archive.ubuntu.com/help ...
- MFC创建线程示例
MFC创建线程示例 AfxBeginThread() 创建现场的方法是AfxBeginThread()函数. 在[.CPP]文件定义一个全局变量,决定什么时候退出这个线程. BOOL g_bWillE ...
- Hard Negative Mning
对于hard negative mining的解释,引用一波知乎: 链接:https://www.zhihu.com/question/46292829/answer/235112564来源:知乎 先 ...
- ARMV8 datasheet学习笔记3:AArch64应用级体系结构
1.前言 本文主要从应用的角度介绍ARMV8的编程模型和存储模型 2. AArch64应用级编程模型 从应用的角度看到的ARM处理器元素: 可见的元素(寄存器/指令) 说明 可见的寄存器 R0-R30 ...
- spring session使用小记
在并发量大的WEB系统中,Session一般不使用容器Session,而通常使用Redis作为Session的存储.如果为了保持Servlet规范中的Session接口继续可用,往往需要重新实现Ses ...
- git命令行工作环境配置【转】
转自:http://www.cocoachina.com/ios/20171115/21163.html 本文为CocoaChina网友whf5566投稿 前言 笔者一直使用git的图形化工具sour ...
- ubuntu 禁用 guest 账户
第一步: run the command(s) below: (编辑如下文件) sudo vi /usr/share/lightdm/lightdm.conf.d/50-ubuntu.c ...
- 如何交叉编译 linux kernel 内核
Compilation We first need to move the config file by running cp arch/arm/configs/bcmrpi_cutdown_defc ...