urllib库的应用及简单爬虫的编写
1、urllib库基础
1.1爬虫的异常处理
常见状态码及含义
301 Moved Permanently:重定向到新的URL,永久性
302 Found:重定向到临时的URL,非永久性
304 Not Modified:请求的资源未更新
400 Bad Request:非法请求
401 Unauthorized:请求未经授权
403 Forbidden:禁止访问
404 Not Found:没有找到对应页面
500 Internal Server Error:服务器内部出现错误
501 Not Implemented:服务器不支持实现请求所需要的功能
URLError与HTTPError都是异常处理的类,HTTPError是URLError的子类,HTTPError有异常状态码与异常原因,URLError没有异常状态码。不能用URLError直接代替HTTPError,如果要代替,必须要判断是否有状态码属性。
URLError:
1、连不上服务器
2、远程的URL不存在
3、本地没有网络
4、触发了HTTPError(因为HTTPError是它的子类)

1.2爬虫的浏览器伪装技术
想要伪装成浏览器,必须为爬虫添加报头信息。打开浏览器进入网页,F12中network中找到user-agent及其后面的内容,然后创建opener对象,把opener添加为全局(urllib.request.install_opener(opener))。

1.3设置代理服务器

2、爬虫实战
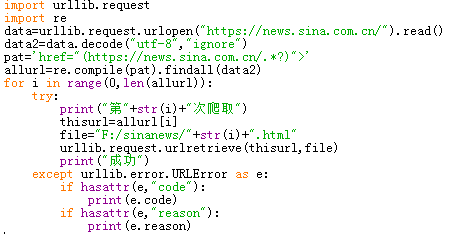
2.1将新浪新闻首页的所有新闻都爬到本地
进入新浪新闻首页,查看网页源代码,根据每个新闻链接的相似度,构造求新闻链接的正则表达式,接着再将网页全部写入到本地。
2.2爬取CSDN博客(http://blog.csdn.net/)首页显示的所有文章,每个文章内容单独生成一个本地网页存到本地中。
利用浏览器伪装技术,先爬首页,通过正则表达式筛选出所有文章的url,然后通过循环把这些url下载到本地。

3、爬取网站图片
3.1爬取淘宝网任意搜索目录下高清图
本次爬取淘宝的搜索关键词为“短裙”,在淘宝搜索短裙进入搜索结果页面。对该页面网址及下几页网址进行分析,找出url构造规律。对源代码中进行分析,注意找到图片的url,此时要特别注意图片必须要高清而不是略缩图,这同样需要注意图片地址。利用正则表达式对提取到的信息进行筛选,最后将得到的图片编号存储到本地。

由于是爬取多页的信息,如果对循环不太熟悉的话,可以先爬取一页的图片,然后找出循环的规律在对规定的页数进行循环爬取图片。
3.2对千图网任一类图片进行爬取
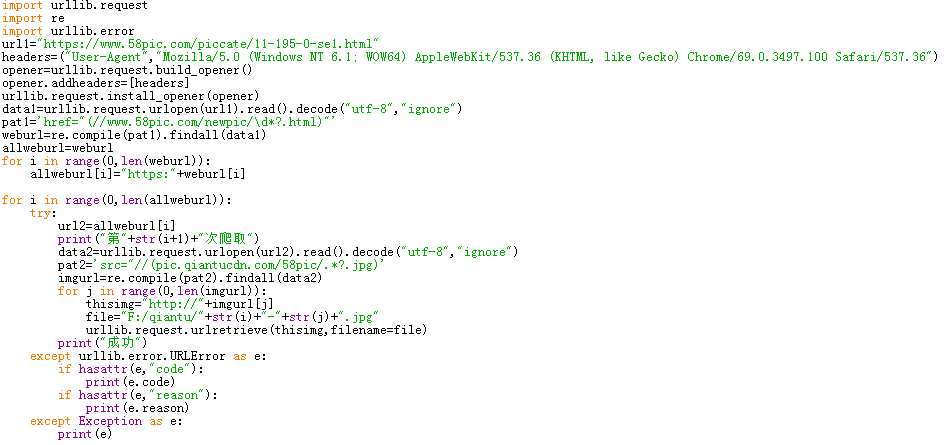
一定要进行异常处理,不然程序很容易崩。尽量每次爬取后都输出一些文字提示,以此来了解进度。
urllib库的应用及简单爬虫的编写的更多相关文章
- 对于python爬虫urllib库的一些理解(抽空更新)
urllib库是Python中一个最基本的网络请求库.可以模拟浏览器的行为,向指定的服务器发送一个请求,并可以保存服务器返回的数据. urlopen函数: 在Python3的urllib库中,所有和网 ...
- 爬虫之urllib库
一.urllib库简介 简介 Urllib是Python内置的HTTP请求库.其主要作用就是可以通过代码模拟浏览器发送请求.它包含四个模块: urllib.request :请求模块 urllib.e ...
- python爬虫 urllib库基本使用
以下内容均为python3.6.*代码 学习爬虫,首先有学会使用urllib库,这个库可以方便的使我们解析网页的内容,本篇讲一下它的基本用法 解析网页 #导入urllib from urllib im ...
- 第三百二十七节,web爬虫讲解2—urllib库爬虫—基础使用—超时设置—自动模拟http请求
第三百二十七节,web爬虫讲解2—urllib库爬虫 利用python系统自带的urllib库写简单爬虫 urlopen()获取一个URL的html源码read()读出html源码内容decode(& ...
- Python爬虫学习笔记-1.Urllib库
urllib 是python内置的基本库,提供了一系列用于操作URL的功能,我们可以通过它来做一个简单的爬虫. 0X01 基本使用 简单的爬取一个页面: import urllib2 request ...
- Python做简单爬虫(urllib.request怎么抓取https以及伪装浏览器访问的方法)
一:抓取简单的页面: 用Python来做爬虫抓取网站这个功能很强大,今天试着抓取了一下百度的首页,很成功,来看一下步骤吧 首先需要准备工具: 1.python:自己比较喜欢用新的东西,所以用的是Pyt ...
- 六 web爬虫讲解2—urllib库爬虫—基础使用—超时设置—自动模拟http请求
利用python系统自带的urllib库写简单爬虫 urlopen()获取一个URL的html源码read()读出html源码内容decode("utf-8")将字节转化成字符串 ...
- 网络爬虫必备知识之urllib库
就库的范围,个人认为网络爬虫必备库知识包括urllib.requests.re.BeautifulSoup.concurrent.futures,接下来将结合爬虫示例分别对urllib库的使用方法进行 ...
- 爬虫入门之urllib库详解(二)
爬虫入门之urllib库详解(二) 1 urllib模块 urllib模块是一个运用于URL的包 urllib.request用于访问和读取URLS urllib.error包括了所有urllib.r ...
随机推荐
- SQL Server - DISTINCT
http://www.runoob.com/sql/sql-distinct.html 只选出不同的值,过滤掉重复的值.
- English 动词篇
动词后加to do 和 doing的记忆口诀 一.只能用动名词(ing)作宾语 [口诀] 考虑建议盼原谅,承认推迟没得想. 避免错过继续练,否定完成停欣赏. 禁止想象才冒险,不禁介意弃逃亡. cons ...
- 51nod--1072 威佐夫游戏 (博弈论)
题目: 1072 威佐夫游戏 基准时间限制:1 秒 空间限制:131072 KB 分值: 0 难度:基础题 收藏 关注 有2堆石子.A B两个人轮流拿,A先拿.每次可以从一堆中取任意个或从2堆中取相同 ...
- java基础编程题练习(二)
1.回文数 思路一:使用java特有解法,将原数字以字符串存储,翻转后赋值给新的字符串变量,再使用equals与原字符串进行对比 import java.util.Scanner; public cl ...
- 【python】flask+nginx配置
背景信息 有wordpress服务A 有flask服务B, gunicorn启动,8个进程 用nginx代理,实现访问A然后跳转到B 问题 flask服务B上有文件上传操作,用nginx后发现无法上传 ...
- Postgresql查询出换行符和回车符:
1.有时候,业务因为回车和换行出现的错误,第一步,首先要查询出回车符和换行符那一条数据: -- 使用chr()和chr()进行查询 SELECT * )||)||'%'; -- 其实查询chr()和c ...
- 学习笔记: yield迭代器
yield 与 IEnumerable<T> 结对出现, 可实现按需获取 , 迭代器模式 static void Main(string[] args) { ...
- php操作数据库获取到的结果集mysql_result
判断取出的结果集是否为空集: $sql="select adminPwd from adminaccount"; //判断查询是否有数据 if(mysqli_num_rows($r ...
- 1.使用RNN做MNIST分类
第一次用LSTM,从简单做起吧~~ 注意事项: batch_first=True 意味着输入的格式为(batch_size,time_step,input_size),False 意味着输入的格式为( ...
- Django表单字段汇总
Field.clean(value)[source] 虽然表单字段的Field类主要使用在Form类中,但也可以直接实例化它们来使用,以便更好地了解它们是如何工作的.每个Field的实例都有一个cle ...