scrapy 中crawlspider 爬虫
爬取目标网站:
http://www.chinanews.com/rss/rss_2.html
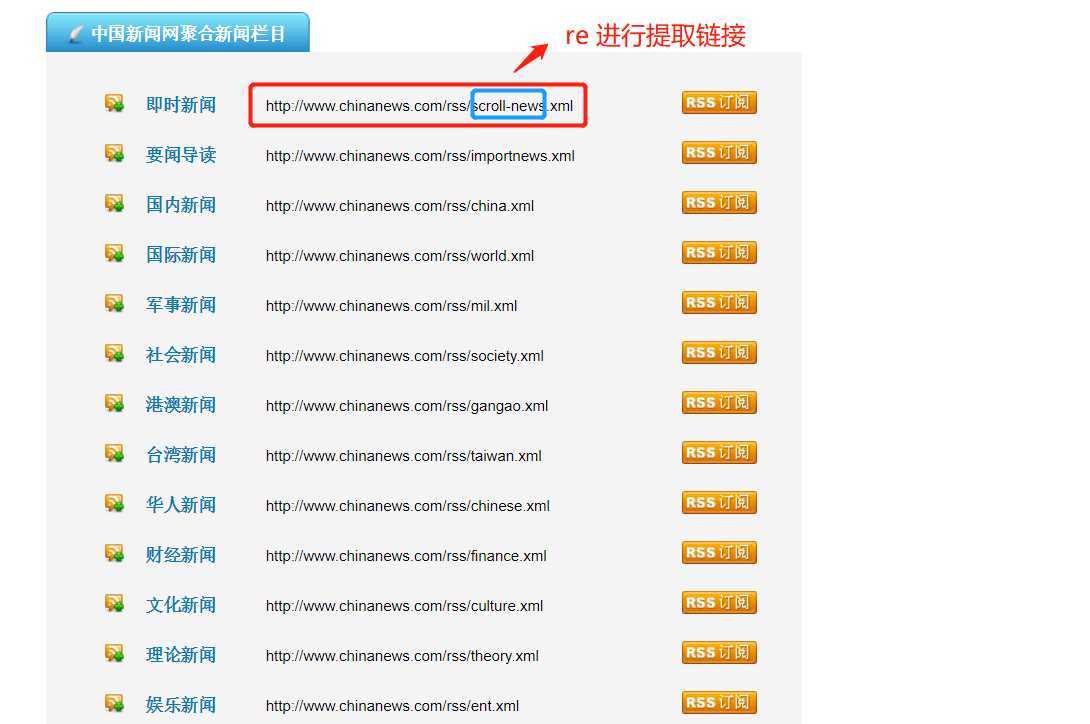
获取url后进入另一个页面进行数据提取

检查网页:
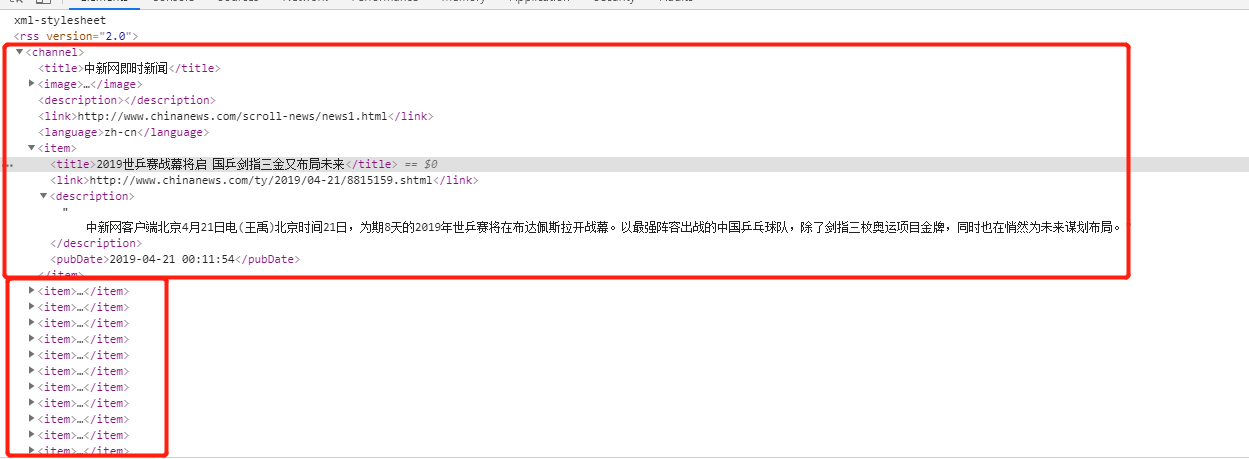
爬虫该页数据的逻辑:
Crawlspider爬虫类:
# -*- coding: utf-8 -*-
import scrapy
import re
#from scrapy import Selector
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule class NwSpider(CrawlSpider):
name = 'nw'
# allowed_domains = ['www.new.com']
start_urls = ['http://www.chinanews.com/rss/rss_2.html'] rules = (
Rule(LinkExtractor(allow='http://www.chinanews.com/rss/.*?\.xml'), callback='parse_item'),
) def parse_item(self, response):
selector = Selector(response)
items =response.xpath('//item').extract()
for node in items:
# print(type(node))
#
item = {}
item['title'] = re.findall(r'<title>(.*?)</title>',node,re.S)[0]
item['link'] = re.findall(r'<link>(.*?)</link>',node,re.S)[0]
item['desc'] = re.findall(r'<description>(.*?)</description>',node,re.S)[0]
item['pub_date'] =re.findall(r'<pubDate>(.*?)</pubDate>',node,re.S)[0]
print(item)
#item['domain_id'] = response.xpath('//input[@id="sid"]/@value').get() #item['name'] = response.xpath('//div[@id="name"]').get()
#item['description'] = response.xpath('//div[@id="description"]').get()
# yield item
scrapy 中crawlspider 爬虫的更多相关文章
- python框架Scrapy中crawlSpider的使用——爬取内容写进MySQL
一.先在MySQL中创建test数据库,和相应的site数据表 二.创建Scrapy工程 #scrapy startproject 工程名 scrapy startproject demo4 三.进入 ...
- python框架Scrapy中crawlSpider的使用
一.创建Scrapy工程 #scrapy startproject 工程名 scrapy startproject demo3 二.进入工程目录,根据爬虫模板生成爬虫文件 #scrapy genspi ...
- scrapy中运行爬虫时出现twisted critical unhandled error错误
1. 试试这条命令: twisted critical unhandled error on scrapy tutorial python python27\scripts\pywin32_posti ...
- 爬虫07 /scrapy图片爬取、中间件、selenium在scrapy中的应用、CrawlSpider、分布式、增量式
爬虫07 /scrapy图片爬取.中间件.selenium在scrapy中的应用.CrawlSpider.分布式.增量式 目录 爬虫07 /scrapy图片爬取.中间件.selenium在scrapy ...
- scrapy进阶(CrawlSpider爬虫__爬取整站小说)
# -*- coding: utf-8 -*- import scrapy,re from scrapy.linkextractors import LinkExtractor from scrapy ...
- Scrapy - CrawlSpider爬虫
crawlSpider 爬虫 思路: 从response中提取满足某个条件的url地址,发送给引擎,同时能够指定callback函数. 1. 创建项目 scrapy startproject mysp ...
- python爬虫之Scrapy框架(CrawlSpider)
提问:如果想要通过爬虫程序去爬取”糗百“全站数据新闻数据的话,有几种实现方法? 方法一:基于Scrapy框架中的Spider的递归爬去进行实现的(Request模块回调) 方法二:基于CrawlSpi ...
- 第三百五十一节,Python分布式爬虫打造搜索引擎Scrapy精讲—将selenium操作谷歌浏览器集成到scrapy中
第三百五十一节,Python分布式爬虫打造搜索引擎Scrapy精讲—将selenium操作谷歌浏览器集成到scrapy中 1.爬虫文件 dispatcher.connect()信号分发器,第一个参数信 ...
- 爬虫开发12.selenium在scrapy中的应用
selenium在scrapy中的应用阅读量: 370 1 引入 在通过scrapy框架进行某些网站数据爬取的时候,往往会碰到页面动态数据加载的情况发生,如果直接使用scrapy对其url发请求,是绝 ...
随机推荐
- Oracle函数中对于NO_DATA_FOUND异常处理的研究
一直以来有一个困惑,一直没解决,昨天一哥们问我这个问题,决心弄清楚,终于得到了答案.先看下面这个函数: create or replace function fn_test(c_xm varchar) ...
- windows下python环境安装
虽然是windows下安装的方式,但是linux也差不多哈: 1,首先安装python 这个是菜鸟教程的安装介绍页面,其实很清晰了:http://www.runoob.com/python3/pyth ...
- 如何在centos6.5中安装MySQL数据库
huidaoli 东华理工大学信工IT网-项目1+1学习基地(www.ecit-it.com)
- Net Core API网关Ocelot
Ocelot在github的地址 https://github.com/TomPallister/Ocelot , 非常给力的是在课程当天完成了.NET Core 2.0的升级,升级过程请看https ...
- 宝塔安装swoole
新建文件夹 mkdir swoole 切入到文件夹中,进行下载安装包 wget http://pecl.php.net/get/swoole-4.3.2.tgz 解压 tar -zxvf swoole ...
- 项目添加大量js文件时关闭Eclipse校验机制
1,如:当添加Ext JS的examples文件夹时
- 2019/4/17 wen 注解、垃圾回收、多线程
- Oracle SQL语句之常见优化方法总结--不定更新
1.SQL语句尽量用大写的: 因为oracle总是先解析SQL语句,把小写的字母转换成大写的再执行. 2.WHERE子句中的连接顺序: ORACLE采用自下而上的顺序解析WHERE子句,根据这个原理, ...
- Spark大型电商项目实战-及其改良(2) RDD优化效果不稳定的真正原因
首先看没有map join的第2任务: 时间线如下 接着是对应id的算子计算时间表 Stage Id Description Submitted Duration Tasks: Succeeded/T ...
- Vue 组件&组件之间的通信 之 父组件向子组件传值
父组件向子组件传值:父组件通过属性向下传值的方式和子组件通信: 使用步骤: 定义组件:现有自定义组件com-a.com-b,com-a是com-b的父组件: 准备获取数据:com-b要获取父组件dat ...