【尚学堂·Hadoop学习】MapReduce案例1--天气
案例描述
找出每个月气温最高的2天
数据集
-- :: 34c -- :: 38c -- :: 36c -- :: 32c -- :: 37c -- :: 23c -- :: 41c -- :: 27c -- :: 45c -- :: 46c -- :: 47c
代码
MyTQ.class
package com.hadoop.mr.tq;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
/**
* 客户端
* @author Lindsey
*
*/
public class MyTQ {
public static void main(String args []) throws Exception{
//加载配置文件
Configuration conf = new Configuration(true);
//创建客户端
Job job = Job.getInstance(conf);
job.setJarByClass(MyTQ.class);
//Map配置
job.setMapperClass(TMapper.class);
job.setMapOutputKeyClass(Tq.class);
job.setMapOutputValueClass(IntWritable.class);
//分区类:处理大数据量均衡并发处理
job.setPartitionerClass(TPartitioner.class);
//比较类:用buffer字节数组内的key排序
job.setSortComparatorClass(TSortComparator.class);
//Reduce配置
job.setNumReduceTasks(2);
job.setReducerClass(TReducer.class);
//分组比较类:年月相同为一组
job.setGroupingComparatorClass(TGroupingComparator.class);
//输入输出源
Path input = new Path("/user/hadoop/input/weather.txt");
FileInputFormat.addInputPath(job, input);
Path output = new Path("/user/hadoop/output/weather");
if(output.getFileSystem(conf).exists(output)){
output.getFileSystem(conf).delete(output,true);
}
FileOutputFormat.setOutputPath(job, output);
//提交
job.waitForCompletion(true);
}
}
TMapper.class
package com.hadoop.mr.tq;
import java.io.IOException;
import java.text.ParseException;
import java.text.SimpleDateFormat;
import java.util.Calendar;
import java.util.Date;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.util.StringUtils;
public class TMapper extends Mapper<LongWritable, Text, Tq,IntWritable>{
/*
* k-v 映射
* K(Tq) V(IntWritable)
* 1949-10-01 14:21:02 34c
*
*/
Tq mkey = new Tq();
IntWritable mval =new IntWritable();
@Override
protected void map(LongWritable key, Text value,Context context)
throws IOException, InterruptedException {
try {
//字符串分割
String [] strs = StringUtils.split(value.toString(),'\t');
//设置时间格式 注意月份是大写!
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd");
//解析为Date格式
Date date = sdf.parse(strs[0]);
//日历上设置时间
Calendar cal = Calendar.getInstance();
cal.setTime(date);
//Key
mkey.setYear(cal.get(Calendar.YEAR));
mkey.setMonth(cal.get(Calendar.MONTH)+1);
mkey.setDay(cal.get(Calendar.DAY_OF_MONTH));
int temperture = Integer.parseInt(strs[1].substring(0,strs[1].length()-1));
mkey.setTemperature(temperture);
//value
mval.set(temperture);
//输出
context.write(mkey, mval);
} catch (ParseException e) {
e.printStackTrace();
}
}
}
Tq.class
package com.hadoop.mr.tq;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import org.apache.hadoop.io.WritableComparable;
public class Tq implements WritableComparable<Tq>{
private int year;
private int month;
private int day;
private int temperature;
public int getYear() {
return year;
}
public void setYear(int year) {
this.year = year;
}
public int getMonth() {
return month;
}
public void setMonth(int month) {
this.month = month;
}
public int getDay() {
return day;
}
public void setDay(int day) {
this.day = day;
}
public int getTemperature() {
return temperature;
}
public void setTemperature(int temperature) {
this.temperature = temperature;
}
@Override
public void readFields(DataInput in) throws IOException {
this.year=in.readInt();
this.month=in.readInt();
this.day=in.readInt();
this.temperature=in.readInt();
}
@Override
public void write(DataOutput out) throws IOException {
out.writeInt(year);
out.writeInt(month);
out.writeInt(day);
out.writeInt(temperature);
}
@Override
public int compareTo(Tq that) {
//约定:日期正序
int y = Integer.compare(this.year,that.getYear());
if(y == 0){ //年份相同
int m = Integer.compare(this.month,that.getMonth());
if(m == 0){ //月份相同
return Integer.compare(this.day,that.getDay());
}
return m;
}
return y;
}
}
TPartitioner.class
package com.hadoop.mr.tq;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.mapreduce.Partitioner;
/**
* 分区规则设计 使数据分区均衡避免倾斜
* @author Lindsey
*
*/
public class TPartitioner extends Partitioner<Tq,IntWritable>{
@Override
public int getPartition(Tq key, IntWritable value, int numPartitions) {
return key.getYear() % numPartitions;
}
}
TSortComparator.class
package com.hadoop.mr.tq;
import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.io.WritableComparator;
public class TSortComparator extends WritableComparator{
//对字节数据中map排序 需要先将Key反序列化为对象再比较
public TSortComparator(){
super(Tq.class,true); //true是将Tq实例化
}
/* 时间正序 、温度倒序 */
@Override
public int compare(WritableComparable a, WritableComparable b) {
Tq t1 = (Tq) a;
Tq t2 = (Tq) b;
int y = Integer.compare(t1.getYear(),t2.getYear());
if(y == 0){
int m = Integer.compare(t1.getMonth(),t2.getMonth());
if(m == 0){
//加上负号实现倒序
return -Integer.compare(t1.getTemperature(),t2.getTemperature());
}
return m;
}
return y;
}
}
TReducer.class
package com.hadoop.mr.tq;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.shaded.org.glassfish.grizzly.compression.lzma.impl.lz.InWindow;
public class TReducer extends Reducer<Tq, IntWritable, Text,IntWritable>{
Text rkey = new Text();
IntWritable rval = new IntWritable();
/*
* 相同的Key为一组:Tq
*/
@Override
protected void reduce(Tq key, Iterable<IntWritable> values, Context context)
throws IOException, InterruptedException {
int flg = 0; //标志,表示是否已经取了当天的天气
int day = 0;
for(IntWritable v:values){
if(flg == 0){
day = key.getDay();
//设置文本内容 yyyy-mm-dd:temperture
rkey.set(key.getYear()+"-"+key.getMonth()+"-"+key.getDay());
rval.set(key.getTemperature());
flg++;
context.write(rkey, rval);
}
if(flg!=0 && day!=key.getDay()){
rkey.set(key.getYear()+"-"+key.getMonth()+"-"+key.getDay());
rval.set(key.getTemperature());
context.write(rkey, rval);
break;
}
}
}
}
TGroupingComparator.class
package com.hadoop.mr.tq;
import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.io.WritableComparator;
public class TGroupingComparator extends WritableComparator{
public TGroupingComparator() {
super(Tq.class,true);
}
/*
* 面向Reduce
* 年月相同为一组 返回0表示为同一组
*/
@Override
public int compare(WritableComparable a, WritableComparable b) {
Tq t1 = (Tq) a;
Tq t2 = (Tq) b;
int y = Integer.compare(t1.getYear(),t2.getYear());
if(y == 0){
return Integer.compare(t1.getMonth(),t2.getMonth());
}
return y;
}
}
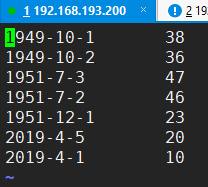
运行结果
part-r-00000

part-r-00001
【尚学堂·Hadoop学习】MapReduce案例1--天气的更多相关文章
- 【尚学堂·Hadoop学习】MapReduce案例2--好友推荐
案例描述 根据好友列表,推荐好友的好友 数据集 tom hello hadoop cat world hadoop hello hive cat tom hive mr hive hello hive ...
- 尚学堂xml学习笔记
1.打开eclipse,文件-新建java project,输入文件的名字,比如输入20181112. 2.对着src右键,选择new-file,输入文件名字,比如:book.xml. 3.开始写.x ...
- 大数据学习——mapreduce案例join算法
需求: 用mapreduce实现select order.orderid,order.pdtid,pdts.pdt_name,oder.amount from orderjoin pdtson ord ...
- 尚学堂 hadoop
mr spark storm 都是分布式计算框架,他们之间不是谁替换谁的问题,是谁适合做什么的问题. mr特点,移动计算,而不移动数据. 把我们的计算程序下发到不同的机器上面运行,但是不移动数据. 每 ...
- 尚学堂JAVA基础学习笔记
目录 尚学堂JAVA基础学习笔记 写在前面 第1章 JAVA入门 第2章 数据类型和运算符 第3章 控制语句 第4章 Java面向对象基础 1. 面向对象基础 2. 面向对象的内存分析 3. 构造方法 ...
- Hadoop学习之第一个MapReduce程序
期望 通过这个mapreduce程序了解mapreduce程序执行的流程,着重从程序解执行的打印信息中提炼出有用信息. 执行前 程序代码 程序代码基本上是<hadoop权威指南>上原封不动 ...
- Hadoop学习之旅三:MapReduce
MapReduce编程模型 在Google的一篇重要的论文MapReduce: Simplified Data Processing on Large Clusters中提到,Google公司有大量的 ...
- hadoop 学习笔记:mapreduce框架详解
开始聊mapreduce,mapreduce是hadoop的计算框架,我学hadoop是从hive开始入手,再到hdfs,当我学习hdfs时候,就感觉到hdfs和mapreduce关系的紧密.这个可能 ...
- Hadoop学习笔记:MapReduce框架详解
开始聊mapreduce,mapreduce是hadoop的计算框架,我学hadoop是从hive开始入手,再到hdfs,当我学习hdfs时候,就感觉到hdfs和mapreduce关系的紧密.这个可能 ...
随机推荐
- 【spring源码分析】IOC容器初始化(三)
前言:在[spring源码分析]IOC容器初始化(二)中已经得到了XML配置文件的Document实例,下面分析bean的注册过程. XmlBeanDefinitionReader#registerB ...
- Linux新手随手笔记1.3
shell脚本的编写(划重点) #!/bin/bash 脚本的声明信息 #sjsjdhsjdhh 脚本的注释 ls -l ...
- 【故障公告】SendCloud 邮件发送服务故障造成大量 QQ 邮箱收不到邮件
抱歉,由于我们所使用的搜狐旗下的 SendCloud 邮件发送服务出现故障,今天上午大量发往 @qq.com 邮箱的邮件无法正常发送,从 SendCloud 管理控制台看这些邮件一直处于“请求中”的状 ...
- Python----Kernel SVM
什么是kernel Kernel的其实就是将向量feature转换与点积运算合并后的运算,如下, 概念上很简单,但是并不是所有的feature转换函数都有kernel的特性. 常见kernel 常见k ...
- (三)jdk8学习心得之方法引用
三.方法引用 https://www.jianshu.com/p/c9790ba76cee 这边博客写的很好,可以首先阅读,在这里感谢这篇文章的博主. 1. 格式 调用者::调用者具备的方法名 2. ...
- StringBuilder的常用方法
转自:https://www.cnblogs.com/jack-Leo/p/6684447.html 在程序开发过程中,我们常常碰到字符串连接的情况,方便和直接的方式是通过"+"符 ...
- NLP句子表征,NLP 的巨人肩膀(下):从 CoVe 到 BERT (转载)
深度长文:NLP的巨人肩膀(上):https://www.jiqizhixin.com/articles/2018-12-10-17 NLP 的巨人肩膀(下):从 CoVe 到 BERT: https ...
- tensorflow-mnist报错[WinError 10060] 由于连接方在一段时间后没有正确答复解决办法
问题原因: tensorflow提供了tensorflow.exapmles.tutorials.mnist.input_data模块下载mnist数据集.代码如下 如果path路径底下没有mnist ...
- 自定义的AdBlock过滤规则
自定义的AdBlock过滤规则 # 屏蔽百度首页的广告流 www.baidu.com##DIV[id="u1"] www.baidu.com##DIV[id="qrcod ...
- 如何解决Redis中的key过期问题
最近我们在Redis集群中发现了一个有趣的问题.在花费大量时间进行调试和测试后,通过更改key过期,我们可以将某些集群中的Redis内存使用量减少25%. Twitter内部运行着多个缓存服务.其中一 ...