kmp--考研写法
首先是模式串匹配:
#include<iostream>
#include<stdlib.h>
using namespace std;
#define maxn 1000000
struct str
{
char *ch;
int length;
}a,b;
int lower(str a, str b)
{ int i=1,j=1;
int k=0; while(i<=a.length&&j<=b.length)
{
if(a.ch[i]==b.ch[j])
{
i++;
j++;
}
else
{
i=++k;
j=1;
}
}
if(j>b.length)
return k;
else
return 0; }
int main()
{ cin>>a.length;
a.ch=(char*)malloc((a.length+1)*sizeof(char));
for(int i=1;i<=a.length;i++)
cin>>a.ch[i];
cin>>b.length;
b.ch=(char*)malloc((b.length+1)*sizeof(char));
for(int i=1;i<=5;i++)
cin>>b.ch[i];
if(lower(a,b)!=0)
cout<< lower(a, b)<<endl;
else
cout<<"no match"<<endl;
free(a.ch);
free(b.ch); return 0;
}
malloc :
数组=(类型*)malloc(数组大小*sizeof(类型));
free(数组);
例如:
a.ch=(char*)malloc((a.length+1)*sizeof(char));
free(b.ch);
为什么不用2个for。然后不匹配break呢?
因为更好改kmp,而且更防止老师眼睛一累以为你瞎搞,批错了了。
然后 这个算法的复杂度是o(m^n);
我们需要一个更快的算法——kmp
我们来看一个例子:例子别的博主那里偷一下吧。
abcaabababaa和abab
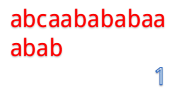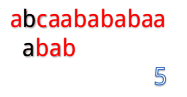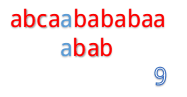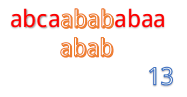
但是我们发现这样匹配很浪费!
为什么这么说呢,我们看到第4步: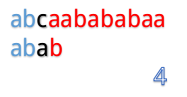
在第4步的时候,我们发现第3位上c与a不匹配,然后第五步的时候我们把B串向后移一位,再从第一个开始匹配。
这里就有一个对已知信息很大的浪费,因为根据前面的匹配结果,我们知道B串的前两位是ab,所以不管怎么移,都是不能和b匹配的,所以应该直接跳过对A串第二位的匹配,对于A串的第三位也是同理
许这这个例子还不够经典,我们再举一个。
A=”abbaabbbabaa”
B=”abbaaba”
在这个例子中,我们依然从第1位开始匹配,直到匹配失败:
abbaabbbabba
abbaaba
我们发现第7位不匹配
那么我们若按照原来的方式继续匹配,则是把B串向后移一位,重新从第一个字符开始匹配
abbaabbbabba
_abbaaba
依然不匹配,那我们就要继续往后移咯。
且住!
既然我们已经匹配了前面的6位,那么我们也就知道了A串这6位和B串的前6位是匹配的,我们能否利用这个信息来优化我们的匹配呢?
也就是说,我们能不能在上面匹配失败后直接跳到:
abbaabbbabba
____abbaaba
这样就可以省去很多不必要的匹配
我们把这个状态叫做s状态跳转到 s1 状态;
怎么跳呢。这时候我们需要一个f数组;
f数组
在模式串j处发生了不匹配,只需将f前移使fL和fR重合即可;
1 f为模式串中j之前的子串
2fL和fR
fL 为f左端的一个子串 fR为右端的一个子串

另外要取最长的fL和fR;
下一个状态是这个
abababab
abababab
如果不取最长的会造成
abababab
abababab
直接冲s状态跳到了s2,漏掉了s1状态。
好了怎么求f呢。暴力。开个玩笑。那怎么能叫kmp呢。了解kmp的同学都知道kmp有个next数组。

这是手工求发适用于:考研选择题
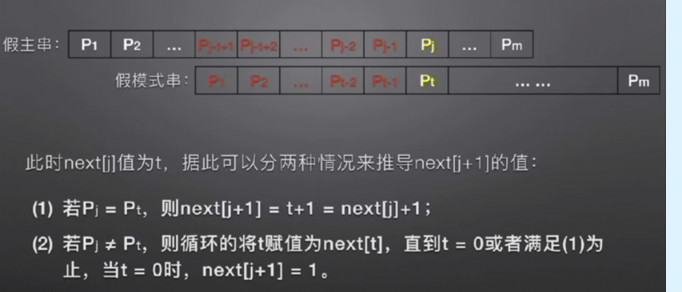
我们是不是一次一次遍历下去的呢,每一次求next[j]都已经把next[j]以前的都处理好了呢。
之前说了 暴力那想写很容易改。那么我们怎么改呢:
int kmp(str a, str b)
{ int i=1,j=1;
//int k=0; while(i<=a.length&&j<=b.length)
{
if(a.ch[i]==b.ch[j]&&j==0)//j==0加进来
{
i++;
j++;
}
else
{
//i=++k;我们都知道kmpn不需要i回溯。
j=next[j];//j=1;跳转到next,用next转移;
}
}
if(j>b.length)
return i-b.length; //return k;
else
return 0; }
那么我们还差一个next
void getnext()
{
int i=1;
nxt[1]=0;
int j=0; while(i<b.length)
{
if(j==0||b.ch[i]==b.ch[j])
{
++i;
++j;
nxt[i]=j;
}
else
j=nxt[j];
} }
合起来就是
#include<iostream>
#include<stdlib.h>
#include <cstdio>
#include <fstream>
using namespace std;
#define maxn 1000000
struct str
{
char *ch;
int length;
}a,b;
int nxt[maxn];
void getnext()
{
int i=1;
nxt[1]=0;
int j=0; while(i<b.length)
{
if(j==0||b.ch[i]==b.ch[j])
{
++i;
++j;
nxt[i]=j;
}
else
j=nxt[j];
} }
int kmp(str a, str b)
{ int i=1,j=1;
//int k=0; while(i<=a.length&&j<=b.length)
{
if(a.ch[i]==b.ch[j]&&j==0)//j==0加进来
{
i++;
j++;
}
else
{
//i=++k;我们都知道kmpn不需要i回溯。
j=nxt[j];//j=1;
}
}
if(j>b.length)
return i-b.length; //return k;
else
return 0; }
int main()
{ cin>>a.length;
a.ch=(char*)malloc((a.length+1)*sizeof(char));
for(int i=1;i<=a.length;i++)
cin>>a.ch[i];
cin>>b.length;
b.ch=(char*)malloc((b.length+1)*sizeof(char));
getnext();
for(int i=1;i<=b.length;i++)
cin>>b.ch[i];
if(kmp(a,b)!=0)
cout<< kmp(a, b)<<endl;
else
cout<<"no match"<<endl;
free(a.ch);
free(b.ch); return 0;
}
最后我们看到这个
kmp的这里。

他需要不断的跳。其实,我们改进。跳的时候相同,必不可能是当前位子

#include<iostream>
#include<stdlib.h>
#include <cstdio>
#include <fstream>
using namespace std;
#define maxn 1000000
struct str
{
char *ch;
int length;
}a,b;
int nextval[maxn];
void getnextval()
{
int i=1;
nextval[1]=0;
int j=0; while(i<b.length)
{
if(j==0||b.ch[i]==b.ch[j])
{
++i;
++j;
if (b.ch[i]!=b.ch[j]){
nextval[i]=j;
}
else
{
nextval[i]=nextval[j];
}
}
else
j=nextval[j];
} }
int kmp(str a, str b)
{ int i=1,j=1;
//int k=0; while(i<=a.length&&j<=b.length)
{
if(a.ch[i]==b.ch[j]&&j==0)//j==0加进来
{
i++;
j++;
}
else
{
//i=++k;我们都知道kmpn不需要i回溯。
j=nextval[j];//j=1;
}
}
if(j>b.length)
return i-b.length; //return k;
else
return 0; }
int main()
{ cin>>a.length;
a.ch=(char*)malloc((a.length+1)*sizeof(char));
for(int i=1;i<=a.length;i++)
cin>>a.ch[i];
cin>>b.length;
b.ch=(char*)malloc((b.length+1)*sizeof(char));
getnextval();
for(int i=1;i<=b.length;i++)
cin>>b.ch[i];
if(kmp(a,b)!=0)
cout<< kmp(a, b)<<endl;
else
cout<<"no match"<<endl;
free(a.ch);
free(b.ch); return 0;
}
kmp--考研写法的更多相关文章
- KMP总结
首先给一个我能看懂的KMP讲解: http://blog.csdn.net/v_july_v/article/details/7041827 来自大神july 文章很长,但是慢慢看,会发现讲的很好. ...
- poj-3080(kmp+暴力枚举)
题意:给你多个字符串,问你这几个字符串的最长公共子串是哪个,如果有多个,输出字典序最大的那个,如果最长的公共子串长度小于3,输出一个奇怪的东西: 解题思路:首先看数据,数据不大,开始简单快乐的暴力之路 ...
- bzoj4641 基因改造 KMP / hash
依稀记得,$NOIP$之前的我是如此的弱小.... 完全不会$KMP$的写法,只会暴力$hash$.... 大体思路为把一个串的哈希值拆成$26$个字母的位权 即$hash(S) = \sum\lim ...
- HDU - 1711 A - Number Sequence(kmp
HDU - 1711 A - Number Sequence Given two sequences of numbers : a[1], a[2], ...... , a[N], and b[1 ...
- CodeForces 1200E Compress Words
\(C_n^m\)的typora,点了一下启用源代码模式就把我已经写好的博客弄没了,就给我留个标题,自动保存也只给我保存了个标题--\(C_n^m\),wdnmd Time limit 1000 ms ...
- KMP算法不同写法之间区别
网上之所以有这么多版本的KMP算法,是因为有的人写的是最大长度串版本的,有的人写的是next数组版本的(具体区别看下面博文),有的人写的是next优化版的,有的人写的是未优化的,不同人写的循环方法不同 ...
- 求NEXT数组和KMP匹配的两种写法
注释掉的是我不喜欢的写法. //计算串str的next数组 void getnext(char *str){ int len=strlen(str); ,k=-; next[]=-; while(j& ...
- POJ3461 KMP 模板题
最近忙着考研复习,所以刷题少了.. 数据结构昨天重新学习了一下KMP算法,今天自己试着写了写,问题还不少,不过KMP算法总归是理解了,以前看v_JULY_v的博客,一头雾水,现在终于懂了他为什么要在算 ...
- 数据结构之KMP算法next数组
我们要找到一个短字符串(模式串)在另一个长字符串(原始串)中的起始位置,也就是模式匹配,最关键的是找到next数组.最简单的算法就是用双层循环来解决,但是这种算法效率低,kmp算法是针对模式串自身的特 ...
- 模式匹配KMP算法
关于KMP算法的原理网上有很详细的解释,我试着总结理解一下: KMP算法是什么 以这张图片为例子 匹配到j=5时失效了,BF算法里我们会使i=1,j=0,再看s的第i位开始能不能匹配,而KMP算法接下 ...
随机推荐
- Trino总结
文章目录 1.Trino与Spark SQL的区别分析 2.Trino与Spark SQL解析过程对比 3.Trino基本概念 4.Trino架构 5.Trino SQL执行流程 6.Trino Ta ...
- 初审blucms(入坑)
作为一名初来乍到审计小白,从blueCMS入手再好不过了.通过对入门级的cms进行审计以及一个整体的框架和常见的漏洞学习,对个人而言是一次不错的学习经历.话不多说直接进入主题. 代码审计环境 Blue ...
- 改变JavaScript中函数的内部this指向!
改变JavaScript中函数的内部this指向! 第一种方法 call call 可以 调用函数 + 改变函数内的this指向! var obj = { name: 'lvhang' } funct ...
- Linux 通过端口终止进程
以下命令可用于杀死占用某端口的所有进程. root 用户: kill -9 $(lsof -i tcp:进程号 -t) 非 root 用户: kill -9 $(sudo lsof -i tcp:进程 ...
- Web漏洞扫描-AWVS
Web漏洞扫描-AWVS 一.AWVS概述 二.功能以及特点 三.AWVS界面 四.AWVS使用 相关优质博文: CSDN:帽子不够白:WEB渗透测试之三大漏扫神器 一.AWVS概述 Acunetix ...
- Spark运行程序异常信息: org.apache.spark.SparkException: Task not serializable 解决办法
错误信息: 17/05/20 18:51:39 ERROR JobScheduler: Error running job streaming job 1495277499000 ms.0 org.a ...
- java校验导入的模板
/** * 验证导入模板的正确性 InputStream inputStream = file.getInputStream(); */ @SuppressWarnings("depreca ...
- 安装superset
1.首先去Anaconda官网下载安装脚本 Anaconda3-2019.07-Linux-x86_64.sh 2.上传Anaconda3-2019.07-Linux-x86_64.sh 将Anaco ...
- 阅读笔记:ImageNet Classification with Deep Convolutional Neural Networks
概要: 本文中的Alexnet神经网络在LSVRC-2010图像分类比赛中得到了第一名和第五名,将120万高分辨率的图像分到1000不同的类别中,分类结果比以往的神经网络的分类都要好.为了训练更快,使 ...
- Luogu T14448 区间开方
题面版权来自Shlw.题目链接 题目背景 无 题目描述 给定一个数列,元素均为正整数,对其以下两种操作: 1.将某区间每一个数变为其算术平方根(取整) 2.求出某区间内所有数的最大值 输入输出格式 输 ...