机器学习实战基础(十三):sklearn中的数据预处理和特征工程(六)特征选择 feature_selection 简介
当数据预处理完成后,我们就要开始进行特征工程了。

在做特征选择之前,有三件非常重要的事:跟数据提供者开会!跟数据提供者开会!跟数据提供者开会!
一定要抓住给你提供数据的人,尤其是理解业务和数据含义的人,跟他们聊一段时间。技术能够让模型起飞,前提是你和业务人员一样理解数据。
所以特征选择的第一步,其实是根据我们的目标,用业务常识来选择特征。来看完整版泰坦尼克号数据中的这些特征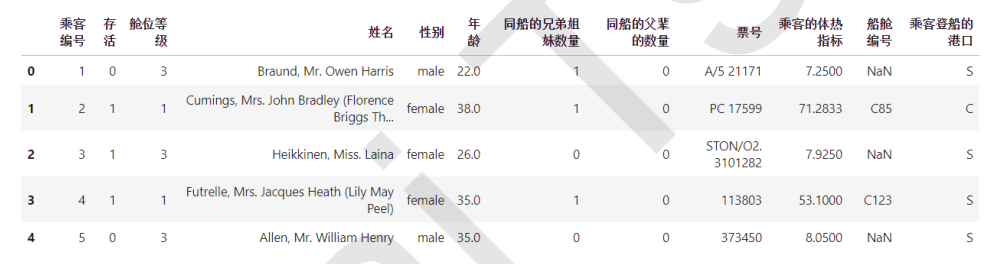
其中是否存活是我们的标签。很明显,以判断“是否存活”为目的,票号,登船的舱门,乘客编号明显是无关特征,可以直接删除。姓名,舱位等级,船舱编号,也基本可以判断是相关性比较低的特征。
性别,年龄,船上的亲人数量,这些应该是相关性比较高的特征。
所以,特征工程的第一步是:理解业务。
当然了,在真正的数据应用领域,比如金融,医疗,电商,我们的数据不可能像泰坦尼克号数据的特征这样少,这样明显,那如果遇见极端情况,我们无法依赖对业务的理解来选择特征,该怎么办呢?我们有四种方法可以用来选择特征:过滤法,嵌入法,包装法,和降维算法。
#导入数据,让我们使用digit recognizor数据来一展身手 import pandas as pd
data = pd.read_csv(r"C:\work\learnbetter\micro-class\week 3 Preprocessing\digit
recognizor.csv") X = data.iloc[:,1:]
y = data.iloc[:,0] X.shape """
这个数据量相对夸张,如果使用支持向量机和神经网络,很可能会直接跑不出来。使用KNN跑一次大概需要半个小时。
用这个数据举例,能更够体现特征工程的重要性。
"""
机器学习实战基础(十三):sklearn中的数据预处理和特征工程(六)特征选择 feature_selection 简介的更多相关文章
- 机器学习实战基础(八):sklearn中的数据预处理和特征工程(一)简介
1 简介 数据挖掘的五大流程: 1. 获取数据 2. 数据预处理 数据预处理是从数据中检测,纠正或删除损坏,不准确或不适用于模型的记录的过程 可能面对的问题有:数据类型不同,比如有的是文字,有的是数字 ...
- sklearn中的数据预处理和特征工程
小伙伴们大家好~o( ̄▽ ̄)ブ,沉寂了这么久我又出来啦,这次先不翻译优质的文章了,这次我们回到Python中的机器学习,看一下Sklearn中的数据预处理和特征工程,老规矩还是先强调一下我的开发环境是 ...
- 机器学习实战基础(十八):sklearn中的数据预处理和特征工程(十一)特征选择 之 Wrapper包装法
Wrapper包装法 包装法也是一个特征选择和算法训练同时进行的方法,与嵌入法十分相似,它也是依赖于算法自身的选择,比如coef_属性或feature_importances_属性来完成特征选择.但不 ...
- 机器学习实战基础(十七):sklearn中的数据预处理和特征工程(十)特征选择 之 Embedded嵌入法
Embedded嵌入法 嵌入法是一种让算法自己决定使用哪些特征的方法,即特征选择和算法训练同时进行.在使用嵌入法时,我们先使用某些机器学习的算法和模型进行训练,得到各个特征的权值系数,根据权值系数从大 ...
- 机器学习实战基础(十四):sklearn中的数据预处理和特征工程(七)特征选择 之 Filter过滤法(一) 方差过滤
Filter过滤法 过滤方法通常用作预处理步骤,特征选择完全独立于任何机器学习算法.它是根据各种统计检验中的分数以及相关性的各项指标来选择特征 1 方差过滤 1.1 VarianceThreshold ...
- 机器学习实战基础(十一):sklearn中的数据预处理和特征工程(四) 数据预处理 Preprocessing & Impute 之 处理分类特征:编码与哑变量
处理分类特征:编码与哑变量 在机器学习中,大多数算法,譬如逻辑回归,支持向量机SVM,k近邻算法等都只能够处理数值型数据,不能处理文字,在sklearn当中,除了专用来处理文字的算法,其他算法在fit的 ...
- 机器学习实战基础(十):sklearn中的数据预处理和特征工程(三) 数据预处理 Preprocessing & Impute 之 缺失值
缺失值 机器学习和数据挖掘中所使用的数据,永远不可能是完美的.很多特征,对于分析和建模来说意义非凡,但对于实际收集数据的人却不是如此,因此数据挖掘之中,常常会有重要的字段缺失值很多,但又不能舍弃字段的 ...
- 机器学习实战基础(九):sklearn中的数据预处理和特征工程(二) 数据预处理 Preprocessing & Impute 之 数据无量纲化
1 数据无量纲化 在机器学习算法实践中,我们往往有着将不同规格的数据转换到同一规格,或不同分布的数据转换到某个特定分布的需求,这种需求统称为将数据“无量纲化”.譬如梯度和矩阵为核心的算法中,譬如逻辑回 ...
- 机器学习实战基础(十五):sklearn中的数据预处理和特征工程(八)特征选择 之 Filter过滤法(二) 相关性过滤
相关性过滤 方差挑选完毕之后,我们就要考虑下一个问题:相关性了. 我们希望选出与标签相关且有意义的特征,因为这样的特征能够为我们提供大量信息.如果特征与标签无关,那只会白白浪费我们的计算内存,可能还会 ...
随机推荐
- ArchLinux——使用WINE-TIM头像异常解决办法
ArchLinux--使用WINE-TIM头像异常解决办法 当使用WINE-TIM头像图片加载异常时,执行以下命令 sudo sysctl -w net.ipv6.conf.all.disable_i ...
- 基于 abp vNext 和 .NET Core 开发博客项目 - Blazor 实战系列(五)
系列文章 基于 abp vNext 和 .NET Core 开发博客项目 - 使用 abp cli 搭建项目 基于 abp vNext 和 .NET Core 开发博客项目 - 给项目瘦身,让它跑起来 ...
- c常用函数-atoi 和 itoa
atoi 和 itoa atoi的功能是把一个字符串转为整数 Action(){ int j; char *s=""; j = atoi(s); lr_output_message ...
- C++值元编程
--永远不要在OJ上使用值元编程,过于简单的没有优势,能有优势的编译错误. 背景 2019年10月,我在学习算法.有一道作业题,输入规模很小,可以用打表法解决.具体方案有以下三种: 运行时预处理,生成 ...
- TiDB初探
TiDB是一个开源的分布式NewSQL数据库,设计的目标是满足100%的OLTP和80%的OLAP,支持SQL.水平弹性扩展.分布式事务.跨数据中心数据强一致性保证.故障自恢复的高可用.海量数据高并发 ...
- 05 . Prometheus监控Nginx
List CentOS7.3 prometheus-2.2.1.linux-amd64.tar.gz nginx-module-vts 节点名 IP 软件版本 硬件 网络 说明 Prometheus ...
- TensorFlow中读取图像数据的三种方式
本文面对三种常常遇到的情况,总结三种读取数据的方式,分别用于处理单张图片.大量图片,和TFRecorder读取方式.并且还补充了功能相近的tf函数. 1.处理单张图片 我们训练完模型之后,常常要用图片 ...
- 梳理搭建SSM步骤
以上全程手撕,如有不足或错误的,请指正!
- 入门大数据---Spark_Streaming整合Kafka
一.版本说明 Spark 针对 Kafka 的不同版本,提供了两套整合方案:spark-streaming-kafka-0-8 和 spark-streaming-kafka-0-10,其主要区别如下 ...
- 入门大数据---HDFS-HA搭建
一.简述 上一篇了解了Zookeeper和HDFS的一些概念,今天就带大家从头到尾搭建一下,其中遇到的一些坑也顺便记录下. 1.1 搭建的拓扑图如下: 1.2 部署环境:Centos3.1,java1 ...