【Spark学习】Apache Spark项目简介
引言:本文直接翻译自Spark官方网站首页
![]() Lightning-fast cluster computing
Lightning-fast cluster computing
从Spark官方网站给出的标题可以看出:Spark——像闪电一样快的集群计算
Apache Spark™ 是一个应用于大规模数据处理的快速且通用的引擎。
速度
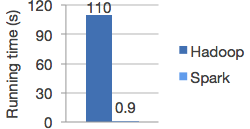
Spark在内存中运行程序的速度比Hadoop MapReduce要快100多倍,在磁盘上则要快10多倍。它使用先进的DAG执行引擎来支持循环数据流和内存计算。
易用
用户可以使用Java、Scala或Python语言来快速编写应用程序。Spark提供了80多种高级运算符来帮助用户轻松创建并行应用。而且,用户还可以借助Spark-shell(Scala和Python语言有各自的Spark-shell)来交互地使用Spark。
# Word count in Spark's Python API
file = spark.textFile("hdfs://...")
file.flatMap(lambda line: line.split())
.map(lambda word: (word, 1))
.reduceByKey(lambda a, b: a+b)
通用性
Spark兼备SQL、流处理以及复杂分析等功能。它为多个高级工具提供驱动,包括数据库框架Spark SQL、机器学习框架MLlib、图运算框架GraphX,以及流处理框架Spark Streaming。用户可以在相同的应用程序中无缝兼备这几种框架。

兼容
Spark可以运行在Hadoop、Mesos、Standalone 或者 Cloud平台之上。它可以访问各种数据源,包括HDFS、HBase、S3,以及Cassandra。用户可以分别使用Standalone集群模式,EC2,Hadoop YARN或者Apache Mesos平台轻松运行Spark。Spark可以从HDFS、HBase、Cassandra,以及其他任何Hadoop数据源中读取数据。

【Spark学习】Apache Spark项目简介的更多相关文章
- Spark学习之Spark Streaming(9)
Spark学习之Spark Streaming(9) 1. Spark Streaming允许用户使用一套和批处理非常接近的API来编写流式计算应用,这就可以大量重用批处理应用的技术甚至代码. 2. ...
- Spark学习之Spark SQL(8)
Spark学习之Spark SQL(8) 1. Spark用来操作结构化和半结构化数据的接口--Spark SQL. 2. Spark SQL的三大功能 2.1 Spark SQL可以从各种结构化数据 ...
- Spark学习之Spark调优与调试(7)
Spark学习之Spark调优与调试(7) 1. 对Spark进行调优与调试通常需要修改Spark应用运行时配置的选项. 当创建一个SparkContext时就会创建一个SparkConf实例. 2. ...
- Spark学习之Spark SQL
一.简介 Spark SQL 提供了以下三大功能. (1) Spark SQL 可以从各种结构化数据源(例如 JSON.Hive.Parquet 等)中读取数据. (2) Spark SQL 不仅支持 ...
- Spark学习一:Spark概述
1.1 什么是Spark Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎. 一站式管理大数据的所有场景(批处理,流处理,sql) spark不涉及到数据的存储,只 ...
- 【Spark学习】Spark 1.1.0 with CDH5.2 安装部署
[时间]2014年11月18日 [平台]Centos 6.5 [工具]scp [软件]jdk-7u67-linux-x64.rpm spark-worker-1.1.0+cdh5.2.0+56-1.c ...
- Spark学习之Spark Streaming
一.简介 许多应用需要即时处理收到的数据,例如用来实时追踪页面访问统计的应用.训练机器学习模型的应用,还有自动检测异常的应用.Spark Streaming 是 Spark 为这些应用而设计的模型.它 ...
- Spark学习(4) Spark Streaming
什么是Spark Streaming Spark Streaming类似于Apache Storm,用于流式数据的处理 Spark Streaming有高吞吐量和容错能力强等特点.Spark Stre ...
- Spark学习进度-Spark环境搭建&Spark shell
Spark环境搭建 下载包 所需Spark包:我选择的是2.2.0的对应Hadoop2.7版本的,下载地址:https://archive.apache.org/dist/spark/spark-2. ...
- Spark学习之Spark调优与调试(二)
下面来看看更复杂的情况,比如,当调度器进行流水线执行(pipelining),或把多个 RDD 合并到一个步骤中时.当RDD 不需要混洗数据就可以从父节点计算出来时,调度器就会自动进行流水线执行.上一 ...
随机推荐
- The 5th Zhejiang Provincial Collegiate Programming Contest---ProblemG:Give Me the Number
http://acm.zju.edu.cn/onlinejudge/showProblem.do?problemCode=2971 题意:将输入的英文数字表达转化为阿拉伯数字. #include< ...
- 大象的崛起!Hadoop七年发展风雨录
http://www.open-open.com/news/view/a22597 在互联网这个领域一直有这样的说法:“如果老二无法战胜老大,那么就把老大赖以生存的东西开源吧”.当年Yahoo!与Go ...
- MFC的dll中控制资源问题
有程序EXE和DLL,其中DLL中有1个函数用来显示对话框,被EXE调用.当EXE和DLL都为Release或Debug时,没有任何问题,但EXE为Release.DLL为Debug时,就会出错.该D ...
- SQLite入门与分析(一)---简介
写在前面:出于项目的需要,最近打算对SQLite的内核进行一个完整的剖析,在此希望和对SQLite有兴趣的一起交流.我知道,这是一个漫长的过程,就像曾经去读Linux内核一样,这个过程也将是辛苦的,但 ...
- 解决 Your project contains error(s),please fix them before running your application问题
原文地址: Android笔记:解决 Your project contains error(s),please fix them before running your application问题 ...
- 211. Add and Search Word - Data structure design
题目: Design a data structure that supports the following two operations: void addWord(word) bool sear ...
- POJ1328——Radar Installation
Radar Installation Description Assume the coasting is an infinite straight line. Land is in one side ...
- CVE爬虫抓取漏洞URL
String url1="http://www.cnnvd.org.cn/vulnerability/index/vulcode2/tomcat/vulcode/tomcat/cnnvdid ...
- P94、面试题12:打印1到最大的n位数
题目:输入数字n,按顺序打印出从1最大的n位十进制数.比如输入3,则打印出1,2,3一直到最大的3位数999. 思路:先把字符串中的每一个数字都初始化为‘0’,然后每一次为字符串表示的数字加1,再打印 ...
- python numpy笔记:给matlab使用者
利用Numpy,python可以进行有效的科学计算.本文给过去常用matlab,现在正学习Numpy的人. 在进行矩阵运算等操作时,使用array还是matrix?? 简短的回答,更多的时候使用arr ...