使用 Scrapy 的 ImagesPipeline 下载图片
下载 百度贴吧-动漫壁纸吧 所有图片
定义item

Spider
spider 只需要得到图片的url,必须以列表的形式给管道处理
class PictureSpiderSpider(scrapy.Spider):
name = 'picture_spider'
allowed_domains = ['tieba.baidu.com']
start_urls = ['https://tieba.baidu.com/f?kw=%E5%8A%A8%E6%BC%AB%E5%A3%81%E7%BA%B8']
def parse(self, response):
# 贴吧中一页帖子的ID和标题
theme_urls = re.findall(r'<a rel="noreferrer" href="/p/(\d+)" title="(.*?)" target="_blank" class="j_th_tit ">',
response.text, re.S)
for theme in theme_urls:
# 帖子的url
theme_url = 'https://tieba.baidu.com/p/' + theme[0]
# 进入各个帖子
yield scrapy.Request(url=theme_url, callback=self.parse_theme)
# 贴吧下一页的url
next_url = re.findall(
r'<a href="//tieba.baidu.com/f\?kw=%E5%8A%A8%E6%BC%AB%E5%A3%81%E7%BA%B8&ie=utf-8&pn=(\d+)" class="next pagination-item " >下一页></a>',
response.text, re.S)
if next_url:
next_url = self.start_urls[0] + '&pn=' + next_url[0]
yield scrapy.Request(url=next_url)
# 下载每个帖子里的所有图片
def parse_theme(self, response):
item = PostBarItem()
# 每个贴子一页图片的缩略图的url
pic_ids = response.xpath('//img[@class="BDE_Image"]/@src').extract()
# 用列表来装图片的url
item['pic_urls'] = []
for pic_url in pic_ids:
# 取出每张图片的名称
item['pic_name'] = pic_url.split('/')[-1]
# 图片URL
url = 'http://imgsrc.baidu.com/forum/pic/item/' + item['pic_name']
# 将url添加进列表
item['pic_urls'].append(url)
# 将item交给pipelines下载
yield item
# 下完一页图片后继续下一页
next_url = response.xpath('//a[contains(text(),"下一页")]/@href').extract_first()
if next_url:
yield scrapy.Request('https://tieba.baidu.com' + next_url, callback=self.parse_theme)
ImagesPipeline
- from scrapy.pipelines.images import ImagesPipeline
- 继承ImagesPipeline,重写get_media_requests()和file_path()方法
from scrapy.pipelines.images import ImagesPipeline
import scrapy
class PostBarPipeline(ImagesPipeline):
# 需要headers的网站,再使用
headers = {
'User-Agent': '',
'Referer': '',
}
def get_media_requests(self, item, info):
for pic_url in item['pic_urls']:
# 为每个url生成一个Request
yield scrapy.Request(pic_url)
# 需要请求头的时候,添加headers参数
# yield scrapy.Request(pic_url, headers=self.headers)
def file_path(self, request, response=None, info=None):
# 重命名(包含后缀名),若不重写这函数,图片名为哈希
pic_path = request.url.split('/')[-1]
return pic_path
settings文件
激活管道

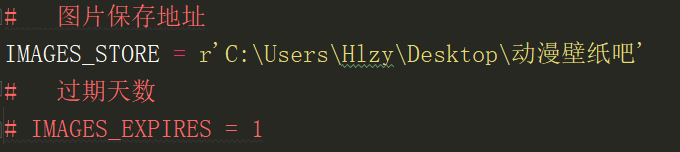
设置图片保存地址
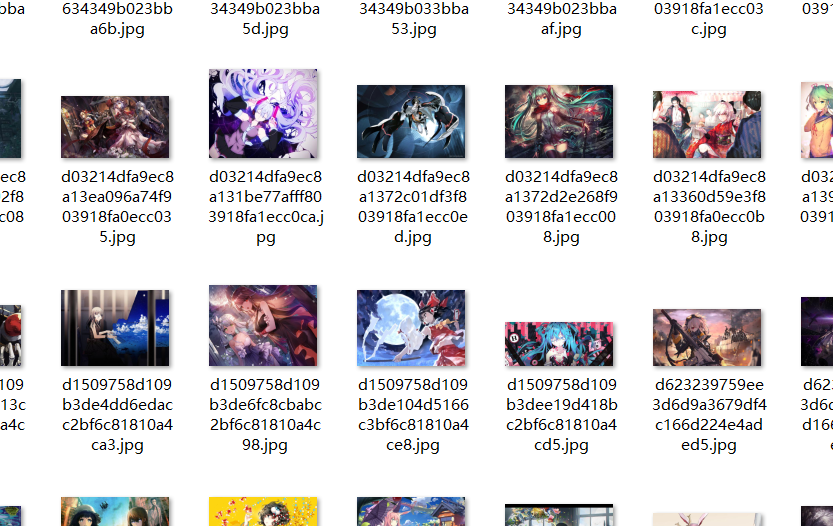
运行结果
使用 Scrapy 的 ImagesPipeline 下载图片的更多相关文章
- Scrapy框架学习 - 使用内置的ImagesPipeline下载图片
需求分析需求:爬取斗鱼主播图片,并下载到本地 思路: 使用Fiddler抓包工具,抓取斗鱼手机APP中的接口使用Scrapy框架的ImagesPipeline实现图片下载ImagesPipeline实 ...
- 使用Scrapy自带的ImagesPipeline下载图片,并对其进行分类。
ImagesPipeline是scrapy自带的类,用来处理图片(爬取时将图片下载到本地)用的. 优势: 将下载图片转换成通用的JPG和RGB格式 避免重复下载 缩略图生成 图片大小过滤 异步下载 . ...
- Scrapy爬取美女图片续集 (原创)
上一篇咱们讲解了Scrapy的工作机制和如何使用Scrapy爬取美女图片,而今天接着讲解Scrapy爬取美女图片,不过采取了不同的方式和代码实现,对Scrapy的功能进行更深入的运用.(我的新书< ...
- 用Scrapy爬虫下载图片(豆瓣电影图片)
用Scrapy爬虫的安装和入门教程,这里有,这篇链接的博客也是我这篇博客的基础. 其实我完全可以直接在上面那篇博客中的代码中直接加入我要下载图片的部分代码的,但是由于上述博客中的代码已运行,已爬到快九 ...
- scrapy批量下载图片
# -*- coding: utf-8 -*- import scrapy from rihan.items import RihanItem class RihanspiderSpider(scra ...
- scrapy下载图片到自己的目录,创建缩略图,存储入库
环境和工具:python2.7,scrapy 实验网站:http://www.27270.com/tag/333.html 爬去所有兔女郎图片,下面的推荐需要过滤 逻辑:分析网站信息,下载图片和入库 ...
- 通过scrapy内置的ImagePipeline下载图片到本地、并提取本地保存地址
1.通过scrapy内置的ImagePipeline下载图片到本地 2.获取图片保存本地的地址 1.通过scrapy内置的ImagePipeline下载图片到本地 1)在settings.py中打开 ...
- Scrapy Item用法示例(保存item到MySQL数据库,MongoDB数据库,使用官方组件下载图片)
需要学习的地方: 保存item到MySQL数据库,MongoDB数据库,下载图片 1.爬虫文件images.py # -*- coding: utf-8 -*- from scrapy import ...
- Scrapy——6 APP抓包—scrapy框架下载图片
Scrapy——6 怎样进行APP抓包 scrapy框架抓取APP豆果美食数据 怎样用scrapy框架下载图片 怎样用scrapy框架去下载斗鱼APP的图片? Scrapy创建下载图片常见那些问题 怎 ...
随机推荐
- mysql如何处理高并发(转)
mysql高并发的解决方法有:优化SQL语句,优化数据库字段,加缓存,分区表,读写分离以及垂直拆分,解耦模块,水平切分等. 高并发大多的瓶颈在后台,在存储mysql的正常的优化方案如下: (1)代码中 ...
- ELK 安装部署小计
ELK的安装部署已经是第N次了! 其实也很简单,这里记下来,以免忘记. #elasticsearch安装部署 wget https://artifacts.elastic.co/downloads/e ...
- 8 种经常被忽视的 SQL 错误用法,你有没有踩过坑?
1.LIMIT 语句 分页查询是最常用的场景之一,但也通常也是最容易出问题的地方.比如对于下面简单的语句,一般 DBA 想到的办法是在 type, name, create_time 字段上加组合索引 ...
- Java设计模式 - - 单例模式 装饰者模式
Java设计模式 单例模式 装饰者模式 作者 : Stanley 罗昊 [转载请注明出处和署名,谢谢!] 静态代理模式:https://www.cnblogs.com/StanleyBlogs/p/1 ...
- react中报错Failed to set an indexed property on 'CSSStyleDeclaration': Index property setter is not supported
产生这个报错的原因是我当时将样式写到了less文件,我在div中使用的使用应该是使用className = ,而我误写了一个style = .style里面当然没有自定义的className,所以产生 ...
- Java生鲜电商平台-深入理解微服务SpringCloud各个组件的关联与架构
Java生鲜电商平台-深入理解微服务SpringCloud各个组件的关联与架构 概述 毫无疑问,Spring Cloud是目前微服务架构领域的翘楚,无数的书籍博客都在讲解这个技术.不过大多数讲解还停留 ...
- Python3操作MySQL基于PyMySQL封装的类
Python3操作MySQL基于PyMySQL封装的类 在未使用操作数据库的框架开发项目的时候,我们需要自己处理数据库连接问题,今天在做一个Python的演示项目,写一个操作MySQL数据库的类, ...
- Linux(Centos7)下Mysql的安装
1.1 查看mysql的安装路径: [root@bogon ~]# whereis mysql mysql: /usr/bin/mysql /usr/lib/mysql /usr/share/mysq ...
- 表空间相关SQL
--查表空间使用率情况(含临时表空间)SELECT D.TABLESPACE_NAME "Name", D.STATUS "Status", TO_CHAR(N ...
- DSP开发程序相关问题总结
1. 定义Class总是出错,原来是这样的class SCM_DRV_API CSERCOS{}:后来改为class CSERCOS{}:就可以了. 类的一般定义格式如下: class < ...