50行Python代码,教你获取公众号全部文章
> 本文首发自公众号:python3xxx
爬取公众号的方式常见的有两种
- 通过搜狗搜索去获取,缺点是只能获取最新的十条推送文章
- 通过微信公众号的素材管理,获取公众号文章。缺点是需要申请自己的公众号。

今天介绍一种通过抓包PC端微信的方式去获取公众号文章的方法。相比其他的方法非常方便。


如上图,通过抓包工具获取微信的网络信息请求,我们发现每次下拉刷新文章的时候都会请求 mp.weixin.qq.com/mp/profile_ext 这个接口。
经过多次测试分析,用到了以下几个参数
- __biz : 用户和公众号之间的唯一id,
- uin :用户的私密id
- key :请求的秘钥,一段时候只会就会失效。
- offset :偏移量
- count :每次请求的条数
数据如下
```
{
"ret": 0,
"errmsg": "ok", # 请求状态
"msg_count": 10, # 信息条数
"can_msg_continue": 1, # 是否还可以继续获取,1代表可以。0代表不可以,也就是最后一页
"general_msg_list": "{"list":[]}", # 公众号文本信息
"next_offset": 20,
"video_count": 1,
"use_video_tab": 1,
"real_type": 0,
"home_page_list": []
}
```
部分代码如下
```
params = {
'__biz': biz,
'uin': uin,
'key': key,
'offset': offset,
'count': count,
'action': 'getmsg',
'f': 'json'
}
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36'
}
response = requests.get(url=url, params=params, headers=headers)
resp_json = response.json()
if resp_json.get('errmsg') == 'ok':
resp_json = response.json()
# 是否还有分页数据, 用于判断return的值
can_msg_continue = resp_json['can_msg_continue']
# 当前分页文章数
msg_count = resp_json['msg_count']
general_msg_list = json.loads(resp_json['general_msg_list'])
list = general_msg_list.get('list')
print(list, "**************")
```
最后打印的list就是公众号的文章信息详情。包括标题(titile)、摘要(digest)、文章地址(content_url)、阅读原文地址(source_url)、封面图(cover)、作者(author)等等...
输出结果如下:
```
[{
"comm_msg_info": {
"id": 1000000038,
"type": 49,
"datetime": 1560474000,
"fakeid": "3881067844",
"status": 2,
"content": ""
},
"app_msg_ext_info": {
"title": "入门爬虫,这一篇就够了!!!",
"digest": "入门爬虫,这一篇就够了!!!",
"content": "",
"fileid": 0,
"content_url": "http:XXXXXX",
"source_url": "",
"cover": "I5kME6BVXeLibZDUhsiaEYiaX7zOoibxa9sb4stIwrfuqID5ttmiaoVAFyxKF6IjOCyl22vg8n2NPv98ibow\\/0?wx_fmt=jpeg",
"subtype": 9,
"is_multi": 0,
"multi_app_msg_item_list": [],
"author": "Python3X",
"copyright_stat": 11,
"duration": 0,
"del_flag": 1,
"item_show_type": 0,
"audio_fileid": 0,
"play_url": "",
"malicious_title_reason_id": 0,
"malicious_content_type": 0
}
},{...},{...},{...},{...},{...},{...},{...},{...},{...}]
```
获取数据之后,可以保存到数据库中,也可以将文章保存在PDF中。
# 1、保存在Mongo中
```python
# Mongo配置
conn = MongoClient('127.0.0.1', 27017)
db = conn.wx #连接wx数据库,没有则自动创建
mongo_wx = db.article #使用article集合,没有则自动创建
for i in list:
app_msg_ext_info = i['app_msg_ext_info']
# 标题
title = app_msg_ext_info['title']
# 文章地址
content_url = app_msg_ext_info['content_url']
# 封面图
cover = app_msg_ext_info['cover']
# 发布时间
datetime = i['comm_msg_info']['datetime']
datetime = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime(datetime))
mongo_wx.insert({
'title': title,
'content_url': content_url,
'cover': cover,
'datetime': datetime
})
```
结果如下
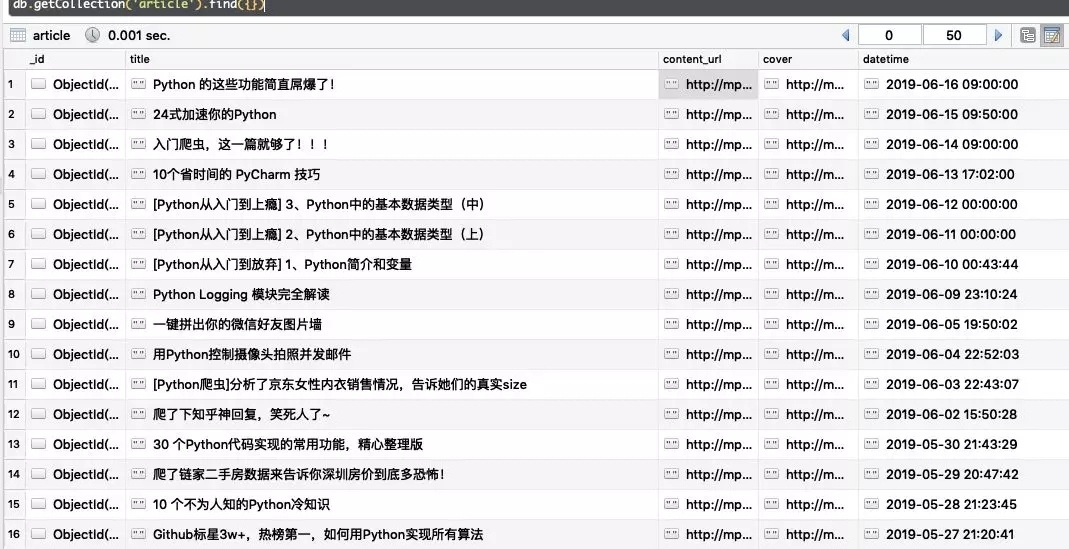
# 2、导入到PDF文件中
Python3中常用的操作PDF的库有python-pdf和pdfkit。我用了pdfkit这个模块导出pdf文件。
pdfkit是工具包Wkhtmltopdf的封装类,因此需要安装Wkhtmltopdf才能使用。
可以访问 https://wkhtmltopdf.org/downloads.html 下载和操作系统匹配的工具包。

实现代码也比较简单,只需要传入导入文件的url即可。
安装pdfkit库
```python
pip3 install pdfkit -i http://pypi.douban.com/simple --trusted-host pypi.douban.com
```
```python
import pdfkit
pdfkit.from_url('公众号文章地址', 'out.pdf')
```
运行之后成功导出pdf文件。

以上就是获取公众号文章的方式,如需完整代码,可在公众号[python3xxx]中回复 **朋友圈** 获取完整代码!
50行Python代码,教你获取公众号全部文章的更多相关文章
- 50行Python代码构建小型区块链
本文介绍了如何使用python构建一个小型的区块链技术,使用Python2实现,代码不到50行. Although some think blockchain is a solution waitin ...
- Python学习:50 行 Python 代码,带你追到最心爱的人
程序员世纪难题 人们一提到程序员第一反应就是:我知道!他们工资很高啊!但大部分都是单身狗,不懂得幽默风趣,只是每天穿格子 polo 衫的宅男一个.甚至程序员自己也这样形容自己:钱多话少死的早.程序员总 ...
- 50行Python代码实现视频中物体颜色识别和跟踪
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者: 机器学习与统计学 PS:如有需要Python学习资料的小伙伴可以加 ...
- 20行python代码,轻松获取各路小说,非常简单
哔哔两句 作为现代青年,我相信应该没几个没看过小说的吧,嘿嘿~ 一般来说咱们书荒的时候怎么办?自然是去起某点排行榜先找到小说名字,然后再找度娘一搜,哎 ,笔趣阁就出来答案了,美滋滋~但是那多麻烦,咱们 ...
- 50行python代码实现个代理server(你懂的)
之前遇到一个场景是这种: 我在自己的电脑上须要用mongodb图形client,可是mongodb的server地址没有对外网开放,仅仅能通过先登录主机A,然后再从A连接mongodbserverB. ...
- 50行Python代码实现视频中物体颜色识别和跟踪(必须以红色为例)
目前计算机视觉(CV)与自然语言处理(NLP)及语音识别并列为人工智能三大热点方向,而计算机视觉中的对象检测(objectdetection)应用非常广泛,比如自动驾驶.视频监控.工业质检.医疗诊断等 ...
- 50 行 Python 代码,带你追到女神
今天来给大家分享一个撩妹技巧,利用 python 每天给你最心爱的人,发送微信消息,说声晚安. 废话不多说,源代码奉上 def get_news(): ... url = "http://o ...
- 20行Python代码爬取王者荣耀全英雄皮肤
引言王者荣耀大家都玩过吧,没玩过的也应该听说过,作为时下最火的手机MOBA游戏,咳咳,好像跑题了.我们今天的重点是爬取王者荣耀所有英雄的所有皮肤,而且仅仅使用20行Python代码即可完成. 准备工作 ...
- 拒绝低效!Python教你爬虫公众号文章和链接
本文首发于公众号「Python知识圈」,如需转载,请在公众号联系作者授权. 前言 上一篇文章整理了的公众号所有文章的导航链接,其实如果手动整理起来的话,是一件很费力的事情,因为公众号里添加文章的时候只 ...
随机推荐
- WPF- 模拟触发Touch Events
原文:WPF- 模拟触发Touch Events 基于API: [DllImport("User32.dll")] public static extern bool Initia ...
- C#实现下载的几种方式举例
using System; using System.Data; using System.Configuration; using System.Web; using System.Web.Secu ...
- wcf服务端代码方式及客户端代码方式
ServiceHost host; // 全局 host = new ServiceHost(typeof(实现服务接口的类)); host.open(); 用代码配置端点的方法 host.add ...
- Windows Phone开发参考资料
Windows Phone API 参考 http://msdn.microsoft.com/zh-cn/library/windows/apps/ff626516(v=vs.105).aspx Wi ...
- Android Studio 添加 Genymotion插件
原文:Android Studio 添加 Genymotion插件 1.下载Genymotion:官网地址,必须先注册才能下载,下载带有VirtualBox的版本 2.安装:安装时会连VirtualB ...
- myCloudData SDK
http://www.tmssoftware.com/site/myclouddata.asp http://www.tmssoftware.com/site/myclouddatasdk.asp
- C# ACCESS 修改表记录提示"UPDATE 语句语法错"问题
错误的sql 语句如下: sqlStr = "update tb_userInfo set passWord='" + pw + "' where userName=' ...
- delphi中move函数的正确理解(const和var一样,都是传地址,所以Move是传地址,而恰恰不是传值)太精彩了 good
我们能看到以下代码var pSource,pDest:PChar; len: integer;.......................//一些代码Move(pSource,pDest,l ...
- qtextedit中的光标问题(通过调用repaint去掉Focus的阴影)
[问题]两个textedit,取名为view0,view1.实现view0输入固定的字符个数后,用setFocus切换聚焦到view1,但是切换完了之后view0还会保留光标残影,出现两个文本框中都有 ...
- Ubuntu14.04 静态编译安装Qt4.8.6
./configure -static -nomake demos -nomake examples -nomake tools -no-exceptions -prefix /usr/local/Q ...