【转载】 tensorflow中 tf.train.slice_input_producer 和 tf.train.batch 函数
原文地址:
https://blog.csdn.net/dcrmg/article/details/79776876
------------------------------------------------------------------------------------------------------------------
tensorflow数据读取机制
tensorflow中为了充分利用GPU,减少GPU等待数据的空闲时间,使用了两个线程分别执行数据读入和数据计算。
具体来说就是使用一个线程源源不断的将硬盘中的图片数据读入到一个内存队列中,另一个线程负责计算任务,所需数据直接从内存队列中获取。
tf在内存队列之前,还设立了一个文件名队列,文件名队列存放的是参与训练的文件名,要训练 N个epoch,则文件名队列中就含有N个批次的所有文件名。 示例图如下:
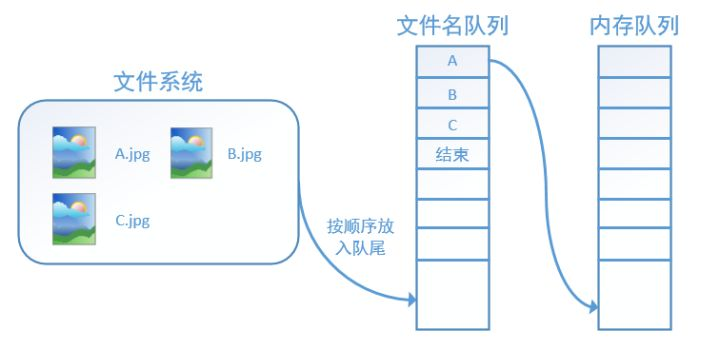
图片来至于 https://zhuanlan.zhihu.com/p/27238630)
在N个epoch的文件名最后是一个结束标志,当tf读到这个结束标志的时候,会抛出一个 OutofRange 的异常,外部捕获到这个异常之后就可以结束程序了。而创建tf的文件名队列就需要使用到 tf.train.slice_input_producer 函数。
tf.train.slice_input_producer
tf.train.slice_input_producer是一个tensor生成器,作用是按照设定,每次从一个tensor列表中按顺序或者随机抽取出一个tensor放入文件名队列。
slice_input_producer(tensor_list, num_epochs=None, shuffle=True, seed=None,
capacity=32, shared_name=None, name=None)
- 第一个参数 tensor_list:包含一系列tensor的列表,表中tensor的第一维度的值必须相等,即个数必须相等,有多少个图像,就应该有多少个对应的标签。
- 第二个参数num_epochs: 可选参数,是一个整数值,代表迭代的次数,如果设置 num_epochs=None,生成器可以无限次遍历tensor列表,如果设置为 num_epochs=N,生成器只能遍历tensor列表N次。
- 第三个参数shuffle: bool类型,设置是否打乱样本的顺序。一般情况下,如果shuffle=True,生成的样本顺序就被打乱了,在批处理的时候不需要再次打乱样本,使用 tf.train.batch函数就可以了;如果shuffle=False,就需要在批处理时候使用 tf.train.shuffle_batch函数打乱样本。
- 第四个参数seed: 可选的整数,是生成随机数的种子,在第三个参数设置为shuffle=True的情况下才有用。
- 第五个参数capacity:设置tensor列表的容量。
- 第六个参数shared_name:可选参数,如果设置一个‘shared_name’,则在不同的上下文环境(Session)中可以通过这个名字共享生成的tensor。
- 第七个参数name:可选,设置操作的名称。
tf.train.slice_input_producer定义了样本放入文件名队列的方式,包括迭代次数,是否乱序等,要真正将文件放入文件名队列,还需要调用tf.train.start_queue_runners 函数来启动执行文件名队列填充的线程,之后计算单元才可以把数据读出来,否则文件名队列为空的,计算单元就会处于一直等待状态,导致系统阻塞。
tf.train.slice_input_producer 和 tf.train.start_queue_runners 使用:
import tensorflow as tf images = ['img1', 'img2', 'img3', 'img4', 'img5']
labels= [1,2,3,4,5] epoch_num=8 f = tf.train.slice_input_producer([images, labels],num_epochs=None,shuffle=False) with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(sess=sess, coord=coord)
for i in range(epoch_num):
k = sess.run(f)
print ('************************')
print (i,k) coord.request_stop()
coord.join(threads)
tf.train.slice_input_producer函数中shuffle=False,不对tensor列表乱序,输出:

如果设置shuffle=True,输出乱序:

tf.train.batch
tf.train.batch是一个tensor队列生成器,作用是按照给定的tensor顺序,把batch_size个tensor推送到文件队列,作为训练一个batch的数据,等待tensor出队执行计算。
batch(tensors, batch_size, num_threads=1, capacity=32,
enqueue_many=False, shapes=None, dynamic_pad=False,
allow_smaller_final_batch=False, shared_name=None, name=None)
- 第一个参数tensors:tensor序列或tensor字典,可以是含有单个样本的序列;
- 第二个参数batch_size: 生成的batch的大小;
- 第三个参数num_threads:执行tensor入队操作的线程数量,可以设置使用多个线程同时并行执行,提高运行效率,但也不是数量越多越好;
- 第四个参数capacity: 定义生成的tensor序列的最大容量;
- 第五个参数enqueue_many: 定义第一个传入参数tensors是多个tensor组成的序列,还是单个tensor;
- 第六个参数shapes: 可选参数,默认是推测出的传入的tensor的形状;
- 第七个参数dynamic_pad: 定义是否允许输入的tensors具有不同的形状,设置为True,会把输入的具有不同形状的tensor归一化到相同的形状;
- 第八个参数allow_smaller_final_batch: 设置为True,表示在tensor队列中剩下的tensor数量不够一个batch_size的情况下,允许最后一个batch的数量少于batch_size, 设置为False,则不管什么情况下,生成的batch都拥有batch_size个样本;
- 第九个参数shared_name: 可选参数,设置生成的tensor序列在不同的Session中的共享名称;
- 第十个参数name: 操作的名称;
如果tf.train.batch的第一个参数 tensors 传入的是tenor列表或者字典,返回的是tensor列表或字典,如果传入的是只含有一个元素的列表,返回的是单个的tensor,而不是一个列表。
以下举例: 一共有5个样本,设置迭代次数是2次,每个batch中含有3个样本,不打乱样本顺序:
# -*- coding:utf-8 -*-
import tensorflow as tf
import numpy as np # 样本个数
sample_num=5 # 设置迭代次数
epoch_num = 2 # 设置一个批次中包含样本个数
batch_size = 3 # 计算每一轮epoch中含有的batch个数
batch_total = int(sample_num/batch_size)+1 # 生成4个数据和标签
def generate_data(sample_num=sample_num):
labels = np.asarray(range(0, sample_num))
images = np.random.random([sample_num, 224, 224, 3])
print('image size {},label size :{}'.format(images.shape, labels.shape)) return images,labels def get_batch_data(batch_size=batch_size):
images, label = generate_data() # 数据类型转换为tf.float32
images = tf.cast(images, tf.float32)
label = tf.cast(label, tf.int32) #从tensor列表中按顺序或随机抽取一个tensor
input_queue = tf.train.slice_input_producer([images, label], shuffle=False) image_batch, label_batch = tf.train.batch(input_queue, batch_size=batch_size, num_threads=1, capacity=64) return image_batch, label_batch image_batch, label_batch = get_batch_data(batch_size=batch_size) with tf.Session() as sess:
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(sess, coord)
try:
for i in range(epoch_num): # 每一轮迭代
print( '************' )
for j in range(batch_total): #每一个batch
print( '--------' )
# 获取每一个batch中batch_size个样本和标签
image_batch_v, label_batch_v = sess.run([image_batch, label_batch])
print(image_batch_v.shape, label_batch_v)
except tf.errors.OutOfRangeError:
print("done")
finally:
coord.request_stop()
coord.join(threads)
输出:

每次生成的batch中含有3个样本,不打乱次序,所以生成的tensor序列是按照‘0,1,2,3,4,0,1,2,3……’排列的。
如果设置每个batch中含有2个样本,打乱次序,即设置 batch_size = 2, tf.train.slice_input_producer函数中 shuffle=True,输出为:
# -*- coding:utf-8 -*-
import tensorflow as tf
import numpy as np # 样本个数
sample_num=5 # 设置迭代次数
epoch_num = 2 # 设置一个批次中包含样本个数
batch_size = 2 # 计算每一轮epoch中含有的batch个数
batch_total = int(sample_num/batch_size)+1 # 生成4个数据和标签
def generate_data(sample_num=sample_num):
labels = np.asarray(range(0, sample_num))
images = np.random.random([sample_num, 224, 224, 3])
print('image size {},label size :{}'.format(images.shape, labels.shape)) return images,labels def get_batch_data(batch_size=batch_size):
images, label = generate_data() # 数据类型转换为tf.float32
images = tf.cast(images, tf.float32)
label = tf.cast(label, tf.int32) #从tensor列表中按顺序或随机抽取一个tensor
input_queue = tf.train.slice_input_producer([images, label], shuffle=True) image_batch, label_batch = tf.train.batch(input_queue, batch_size=batch_size, num_threads=1, capacity=64) return image_batch, label_batch image_batch, label_batch = get_batch_data(batch_size=batch_size) with tf.Session() as sess:
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(sess, coord)
try:
for i in range(epoch_num): # 每一轮迭代
print( '************' )
for j in range(batch_total): #每一个batch
print( '--------' )
# 获取每一个batch中batch_size个样本和标签
image_batch_v, label_batch_v = sess.run([image_batch, label_batch])
print(image_batch_v.shape, label_batch_v)
except tf.errors.OutOfRangeError:
print("done")
finally:
coord.request_stop()
coord.join(threads)

与tf.train.batch函数相对的还有一个tf.train.shuffle_batch函数,两个函数作用一样,都是生成一定数量的tensor, 组成训练一个batch需要的数据集,区别是tf.train.shuffle_batch会打乱样本顺序。
【转载】 tensorflow中 tf.train.slice_input_producer 和 tf.train.batch 函数的更多相关文章
- tensorflow中 tf.train.slice_input_producer 和 tf.train.batch 函数(转)
tensorflow数据读取机制 tensorflow中为了充分利用GPU,减少GPU等待数据的空闲时间,使用了两个线程分别执行数据读入和数据计算. 具体来说就是使用一个线程源源不断的将硬盘中的图片数 ...
- tensorflow中 tf.train.slice_input_producer 和 tf.train.batch 函数
tensorflow数据读取机制 tensorflow中为了充分利用GPU,减少GPU等待数据的空闲时间,使用了两个线程分别执行数据读入和数据计算. 具体来说就是使用一个线程源源不断的将硬盘中的图片数 ...
- tensorflow数据读取机制tf.train.slice_input_producer 和 tf.train.batch 函数
tensorflow中为了充分利用GPU,减少GPU等待数据的空闲时间,使用了两个线程分别执行数据读入和数据计算. 具体来说就是使用一个线程源源不断的将硬盘中的图片数据读入到一个内存队列中,另一个线程 ...
- [转载]tensorflow中使用tf.ConfigProto()配置Session运行参数&&GPU设备指定
tf.ConfigProto()函数用在创建session的时候,用来对session进行参数配置: config = tf.ConfigProto(allow_soft_placement=True ...
- 【转载】 tf.train.slice_input_producer()和tf.train.batch()
原文地址: https://www.jianshu.com/p/8ba9cfc738c2 ------------------------------------------------------- ...
- tensorflow中使用变量作用域及tf.variable(),tf,getvariable()与tf.variable_scope()的用法
一 .tf.variable() 在模型中每次调用都会重建变量,使其存储相同变量而消耗内存,如: def repeat_value(): weight=tf.variable(tf.random_no ...
- [转载]Tensorflow中reduction_indices 的用法
Tensorflow中reduction_indices 的用法 默认时None 压缩成一维
- tensorflow中数据批次划分示例教程
1.简介 将数据划分成若干批次的数据,使用的函数主要有: tf.train.slice_input_producer(tensor_list,shuffle=True,seed=None,capaci ...
- TensorFlow中读取图像数据的三种方式
本文面对三种常常遇到的情况,总结三种读取数据的方式,分别用于处理单张图片.大量图片,和TFRecorder读取方式.并且还补充了功能相近的tf函数. 1.处理单张图片 我们训练完模型之后,常常要用图片 ...
随机推荐
- 渗透之路基础 -- XXE注入漏洞
XXE漏洞 XXE漏洞全称XML External Entity Injection即xml外部实体注入漏洞,XXE漏洞发生在应用程序解析XML输入时,没有禁止外部实体的加载,导致可加载恶意外部文件, ...
- 小程序~获取手机号getPhoneNumber提示该appid没有权限
处理思路 (1)小程序是不是企业主体 (2)有没有进行认证 (3)如果没有 是不可以获取用户手机号码的 .
- linux下分析java程序占用CPU、内存过高
一.CPU过高分析 1)使用TOP命令查看CPU.内存使用状态可以发现CPU占用主要分为两部分,一部分为系统内核空间占用CPU百分比,一部分为用户空间占用CPU百分比.其中CPU状态中标示id的为空闲 ...
- PHP——封装Curl请求方法支持POST | DELETE | GET | PUT 等
前言 Curl: https://www.php.net/manual/en/book.curl.php curl_setopt: https://www.php.net/manual/en/fun ...
- iptables常用命令二之如何删除nat规则
删除iptables nat 规则 删除FORWARD 规则: iptables -nL FORWARD --line-number iptables -D FORWARD 1 删除一条nat 规则 ...
- Linux命令基础3-cd命令
cd 到带空格的文件夹 [root@cctg-sjc16-grafana ccatgbld]# cd 'my test' [root@cctg-sjc16-grafana my test]# cd . ...
- 多线程实现的方式二实现Rannable
package thread; class Thread2 implements Runnable{ private String name; public Thread2(String name) ...
- Javaweb学习笔记(一)
一.javaweb学习是所需要的细节 1.发送响应头相关的方法 1).addHeader()与setHeader()都是设置HTTP协议的响应头字段,区别是addHeader()方法可以增加同名的响应 ...
- 01_搭建新浪云SAE
Step1:注册新浪云计算平台用新浪微博登陆新浪云计算平台,网址:http://sae.sina.com.cn/ 登陆成功之后会跳转到安全设置页面,安全设置页面要填写的东西比较多,需要注意:安全设置里 ...
- asp.net之大文件断点续传
ASP.NET上传文件用FileUpLoad就可以,但是对文件夹的操作却不能用FileUpLoad来实现. 下面这个示例便是使用ASP.NET来实现上传文件夹并对文件夹进行压缩以及解压. ASP.NE ...