CopyOnWrite 思想在 Kafka 源码中的运用
CopyOnWrite 思想在 Kafka 源码中的运用
在 Kafka 的内核源码中,有这么一个场景,客户端在向 Kafka 写数据的时候,会把消息先写入客户端本地的内存缓冲,然后在内存缓冲里形成一个 Batch 之后再一次性发送到 Kafka 服务器上去,这样有助于提升吞吐量。
请看下图:
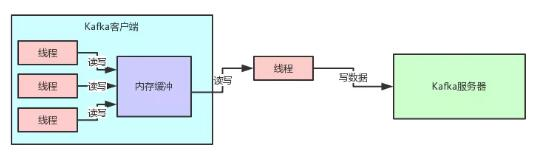
这个时候 Kafka 的内存缓冲用的是什么数据结构呢?
请看源码:
private final ConcurrentMap<TopicPartition, Deque<RecordBatch>> batches =
new CopyOnWriteMap<TopicPartition, Deque<RecordBatch>>();
这个数据结构就是核心的用来存放写入内存缓冲中的消息的数据结构,要看懂这个数据结构需要对很多 Kafka 内核源码里的概念进行解释。Kafka 是自己实现了一个 CopyOnWriteMap,这个CopyOnWriteMap 采用的就是 CopyOnWrite 思想。
我们来看一下这个 CopyOnWriteMap 的源码实现:
// 典型的volatile修饰普通Map
private volatile Map<K, V> map; @Override
public synchronized V put(K k, V v) {
// 更新的时候先创建副本,更新副本,然后对volatile变量赋值写回去
Map<K, V> copy = new HashMap<K, V>(this.map);
V prev = copy.put(k, v);
this.map = Collections.unmodifiableMap(copy);
return prev;
} @Override
public V get(Object k) {
// 读取的时候直接读volatile变量引用的map数据结构,无需锁
return map.get(k);
}
Kafka 这个核心数据结构在这里之所以采用 CopyOnWriteMap 思想来实现,就是因为这个 Map 的 Key-Value 对,其实没那么频繁更新。
也就是 TopicPartition-Deque 这个 Key-Value 对,更新频率很低。但是它的 Get 操作却是高频的读取请求,因为会高频的读取出来一个 TopicPartition 对应的 Deque 数据结构,来对这个队列进行入队出队等操作,所以对于这个 Map 而言,高频的是其 Get 操作。这个时候,Kafka 就采用了 CopyOnWrite 思想来实现这个 Map,避免更新 Key-Value 的时候阻塞住高频的读操作,实现无锁的效果,优化线程并发的性能。
相信看完这个文章,对于 CopyOnWrite 思想以及适用场景,包括 JDK 中的实现,以及在 Kafka 源码中的运用,都有了一个切身的体会了。
CopyOnWrite 思想在 Kafka 源码中的运用的更多相关文章
- Kafka源码中的Producer Record定义
1.ProducerRecord 含义: 发送给Kafka Broker的key/value 值对 2.内部数据结构: -- Topic (名字) -- PartitionID ( 可选) -- Ke ...
- Linux Kafka源码环境搭建
本文主要讲述的是如何搭建Kafka的源码环境,主要针对的Linux操作系统下IntelliJ IDEA编译器,其余操作系统或者IDE可以类推. 1.安装和配置JDK确认JDK版本至少为1.7,最好是1 ...
- Kakfa揭秘 Day3 Kafka源码概述
Kakfa揭秘 Day3 Kafka源码概述 今天开始进入Kafka的源码,本次学习基于最新的0.10.0版本进行.由于之前在学习Spark过程中积累了很多的经验和思想,这些在kafka上是通用的. ...
- Kafka源码分析(二) - 生产者
系列文章目录 https://zhuanlan.zhihu.com/p/367683572 目录 系列文章目录 一. 使用方式 step 1: 设置必要参数 step 2: 创建KafkaProduc ...
- Kafka源码分析系列-目录(收藏不迷路)
持续更新中,敬请关注! 目录 <Kafka源码分析>系列文章计划按"数据传递"的顺序写作,即:先分析生产者,其次分析Server端的数据处理,然后分析消费者,最后再补充 ...
- Kafka源码分析(三) - Server端 - 消息存储
系列文章目录 https://zhuanlan.zhihu.com/p/367683572 目录 系列文章目录 一. 业务模型 1.1 概念梳理 1.2 文件分析 1.2.1 数据目录 1.2.2 . ...
- kafka源码分析之一server启动分析
0. 关键概念 关键概念 Concepts Function Topic 用于划分Message的逻辑概念,一个Topic可以分布在多个Broker上. Partition 是Kafka中横向扩展和一 ...
- Kafka 源码剖析
1.概述 在对Kafka使用层面掌握后,进一步提升分析其源码是极有必要的.纵观Kafka源码工程结构,不算太复杂,代码量也不算大.分析研究其实现细节难度不算太大.今天笔者给大家分析的是其核心处理模块, ...
- apache kafka & CDH kafka源码编译
Apache kafka编译 前言 github网站kafka项目的README.md有关于kafka源码编译的说明 github地址:https://github.com/apache/kafka ...
随机推荐
- linux 利用LDAP身份集中认证
碰巧所在的公司用到了ldap 集中身份认证,所有打算研究下这套架构,但是看遍了网络上的很多教程,要么不完整,要么就是照着根本弄不出来,十月一研究了三天,结合八方资源终于弄出来了,真是不容易,哎,特此记 ...
- node gm图片操作
1,安首先要安装 GraphicsMagick或者ImageMagick 2,npm install gm --save 3,编码测试 var fs = require('fs') //graph ...
- Kotlin扩展深入解析及注意事项和可见性
可见性[Visibility]: 在Java中的可见性有public.protected.private.default四种,而在Kotlin中也有四种:public.protected.privat ...
- webpack loader和插件的编写原理
webpack自定义loader和插件的api网址:https://www.webpackjs.com/api/loaders/ 点击顶部API,看左侧api: 1. 如何编写一个loader 实现的 ...
- DT开发笔记-Cookie作用域的设置
当网站任意一个模块绑定了二级域名或者会员公司主页开启了二级域名时,必须设置cookie作用域,否则会导致二级域名站点不能显示正确的登录状态,js权限错误等问题(例如评论框显示不完全的现象). 进入网站 ...
- machine learning (7)---normal equation相对于gradient descent而言求解linear regression问题的另一种方式
Normal equation: 一种用来linear regression问题的求解Θ的方法,另一种可以是gradient descent 仅适用于linear regression问题的求解,对其 ...
- ip address control获取ip字符串
1.环境:vs2010 & 默认项目字符集(貌似是unicode) 2.首先为ip address control添加control类型变量m_ipaddressedit, BYTE ips[ ...
- netty: 编解码之jboss marshalling, 用marshalling进行对象传输
jboss marshalling是jboss内部的一个序列化框架,速度也十分快,这里netty也提供了支持,使用十分方便. TCP在网络通讯的时候,通常在解决TCP粘包.拆包问题的时候,一般会用以下 ...
- 配置Sublime,为了Python
E:\Sublime Text 3\Data\Packages\User\untitled.sublime-build { "cmd": ["C:\Program Fil ...
- Java【基础学习】之暴力求素数【用数组返回】
Java[基础学习]之暴力求素数[用数组返回] */ import java.util.*; public class Main{ public static void main(String[] a ...