serialVersionUID序列化版本号与ObjectOutputStream对象输入输出流
1. 观察ObjectOutputStream
我们观察ObjectOutputStream就可以发现该类没有无参构造,只有有参构造,所以他是一个包装流
2. 具体使用:
public static void main(String[] args) throws IOException {
Student stu = new Student(13,"xj",15,"男");
String path = "src/main/java/com/xj/dayio/demo2.txt";
FileOutputStream fos = new FileOutputStream(path);
ObjectOutputStream oos = new ObjectOutputStream(fos);
oos.writeObject(stu);
}
3. 实现Serializable接口
我们在使用ObjectOutputStream的时候,需要为被序列化的对象实现Serializable接口(implements Serializable),意思是此类是“可序列化的”。
否则会抛出异常:Exception in thread "main" java.io.NotSerializableException: com.xj.dayio.Student
public class Student implements Serializable {
private int id;
private String name;
private int age;
private String sex;
构造器。。。
get,set方法
toString方法
}
此时调用ObjectOutputStream对象输出流就可以成功将对象写出到文件
�� sr com.xj.dayio.Student�(U�\jb� I ageI idL namet Ljava/lang/String;L sexq ~ xp
t
xjt 男
4. 使用ObjectInputStream读取
我们在读取的时候也可以使用ObjectInputStream对象输入流来进行读取
public static void main(String[] args) throws IOException {
String path = "src/main/java/com/xj/dayio/demo2.txt";
FileInputStream fis = new FileInputStream(path);
ObjectInputStream ois = new ObjectInputStream(fis);
Object object = ois.readObject();
System.out.println((Student) object);
}
输出:
Student{id=13, name='xj', age=15, sex='男'}
5. 序列化接口的作用
那么我们的序列化接口是主要做什么呢?为什么必须要实现接口才能使用对象输出流
- 序列化指的是把一个对象中所包含的数据按照一定的顺序转化成二进制数据。
- 但是,我们自己定义的类型,JVM没有权力直接对其对象进行序列化。因为一个类型一旦允许被序列化,则意味着该类型对象中保存的数据存在泄露的风险。
- 程序员虽然不需要关心对象的具体序列化过程,但是必须要向JVM授权,告诉它哪个类型是允许被序列化的。
- 向JVM授意的方式:让需要被传输的类型实现一个接口Serializable,该接口代表“可序列化的”。
- Serializable是一个空接口,什么内容都没有。它只是为了起到一个“标识”作用。
注意:需要被IO流传输的对象中所有包含的类型都需要是“可序列化”的。所有的引用类型属性所属类型都必须实现Serializable。(那为什么String对象我们可以直接序列化呢?我们查看String的源码就可以发现String类已经实现过序列化接口)
6. 在反序列化的时候,需要提供对应的.class文件。
- 例如本案例中,写入到文件中的是一个com.xj.dayio.Student类对象
- 该对象所有包含的信息都会被写入到文件中,也包含它的类型信息。
- 在反序列化时,JVM会尝试加载这个类型。
- 如果对应的.class不存在,则类加载失败,反序列化对应也会失败。
- 因为内存中想要出现一个对象,它所属的类型不可能不存在。
7. 需要提供的.class字节码文件未必一定是当时存储时!
我们可以将Student对象输出到文件中后,然后删除掉Student类,然后重写一个Student类,但是这个类必须要与原Student类一样
包括包名、类名、实现的接口、继承的父类、属性、属性的修饰符、属性的名称、属性的类型、属性的默认值、方法、方法的修饰符、方法的返回值、方法的参数、方法的抛出异常……
8. 实际上,我们看到的只是一个表象。
决定是否允许进行反序列化,实际上并不是单纯地、直接地根据类中包含的信息进行判断。
实际上,是由一个叫做serialVersionUID(序列化版本号)字段控制反序列化是否允许执行。
向文件中写入一个对象的时候,也包含一个UID。将来进行反序列化的时候,也会将这个UID读取出来,并且和当前尝试加载的类的该UID字段值进行比较。
- 如果这两个UID是相同的,则允许执行反序列化,生成对象成功。
- 如果这两个UID是不相同的,则不允许执行反序列化,生成对象失败。会抛出异常:java.io.InvalidClassException - 不合法的类型异常
9. serialVersionUID来自哪里
那么serialVersionUID来自哪里呢,我们在程序中并没有写呀。
- 如果我们在类中没有定义该字段,那么JVM会自动计算出一个值来充当该类的该字段值
- 该字段值的计算过程类似哈希过程。意味着只要参与运算的数值相同,那么结果也一定相同。
- 也就是说,只要两个类保证一模一样,计算出来的serialVersionUID肯定是相同的。
10. 自己定义serialVersionUID
但是同样我们也可以自己定义serialVersionUID
只需要在代码中加上这一句即可
public class Student implements Serializable {
private static final long serialVersionUID = -4167987148983999791L;
private int id;
private String name;
private int age;
private String sex;
我们还可以有idea直接生成,但是idea默认是不会提醒的
我们需要修改设置,将其后面的对勾勾上
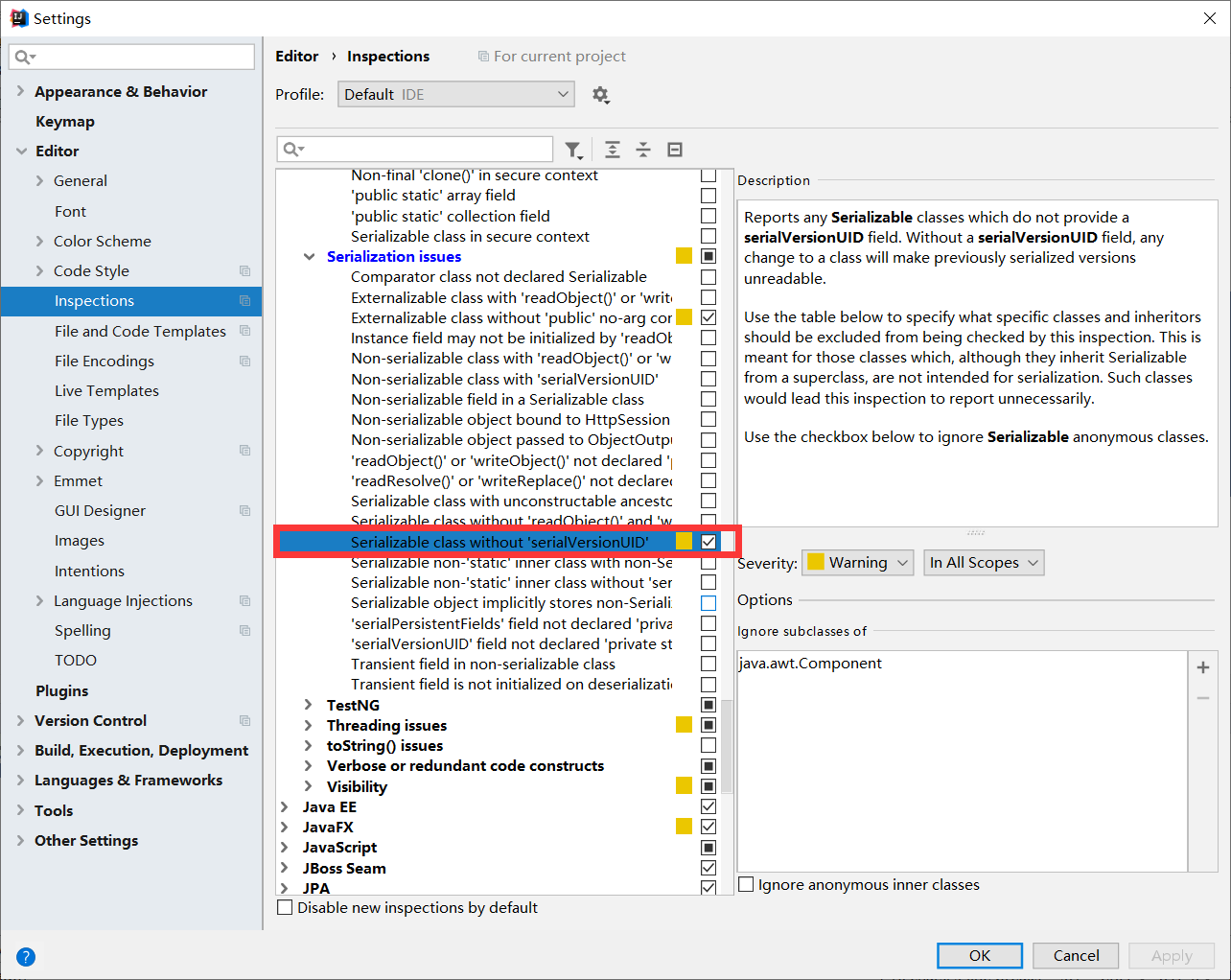
这时如果我们没有写serialVersionUID,ide就会爆出警告
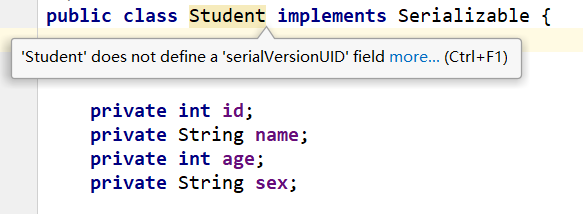
根据提示ide就会自动为我们生成默认的serialVersionUID
11. 定义serialVersionUID为1
我们刚才说了,反序列化是主要根据serialVersionUID 来的,与属性,方法等无关,只是默认serialVersionUID 是由属性,方法生成,但是我们在手动定义serialVersionUID 后,JVM就不会使用默认的,而是使用我们自己的。我们可以定义一个serialVersionUID 为1,那么此时我无论是删除属性,修改方法等,都不会影响反序列化,只是我们如果属性对应不上就无法赋值
例如:若我将name重改为name1
输出:此时name属性就没有被赋值,这也是为什么序列化后数据会有泄露的风险
Student{id=13, name='null', age=15, sex='男'}
比如保存用户名和密码的文件被泄露,此时我只需要写一个类,实现Serializable 后,里面定义很多个变量,如password,passWord,pwd,PassWord等等,此时使用我自己定义的类去使用对象流去读取保存密码的文件时,就有可能将密码提取出来,所以我们应该尽可能的去让序列化版本号serialVersionUID去随机,这样子,序列化版本号不正确,文件也无法被反序列化。
serialVersionUID序列化版本号与ObjectOutputStream对象输入输出流的更多相关文章
- (JAVA)从零开始之--对象输入输出流ObjectInputStream、ObjectOutputStream(对象序列化与反序列化)
对象的输入输出流 : 主要的作用是用于写入对象信息与读取对象信息. 对象信息一旦写到文件上那么对象的信息就可以做到持久化了 对象的输出流: ObjectOutputStream 对象的输入流: Ob ...
- 对象输入输出流ObjectInputStream、ObjectOutputStream(对象序列化与反序列化)
对象的输入输出流 : 主要的作用是用于写入对象信息与读取对象信息. 对象信息一旦写到文件上那么对象的信息就可以做到持久化了 对象的输出流: ObjectOutputStream 对象的输入流: Ob ...
- Day 18:SequenceInputStream、合并切割mp3、对象输入输出流对象
SequenceInputStream用例题讲述用法 需求:1.把a.txt与b.txt 文件的内容合并 2.把a.txt与b.txt .c.txt文件的内容合并 import java.io.Fil ...
- java 对象输入输出流
对象的输入输出流的作用: 用于写入对象 的信息读取对象的信息. 对象的持久化. 比如:用户信息. ObjectInputStream : 对象输入流 ...
- 对象输入输出流ObjectInputStream、ObjectOutputStream(对象的序列化与反序列化)
如题 所有关联的类需要继承Serializable 接口 文件为空,直接反序列化为发生错误; 毕竟对象为null , 序列化到文件里不是空空的! 以下笔记的原文连接: https://www.cnbl ...
- 输入输出流ObjectInputStream、ObjectOutputStream(对象序列化与反序列化)
对象的输入输出流 : 主要的作用是用于写入对象信息与读取对象信息. 对象信息一旦写到文件上那么对象的信息就可以做到持久化了 对象的输出流: ObjectOutputStream 对象的输入流: Ob ...
- Java知多少(69)面向字节的输入输出流
字节流以字节为传输单位,用来读写8位的数据,除了能够处理纯文本文件之外,还能用来处理二进制文件的数据.InputStream类和OutputStream类是所有字节流的父类. InputStream类 ...
- 八. 输入输出(IO)操作4.面向字节的输入输出流
字节流以字节为传输单位,用来读写8位的数据,除了能够处理纯文本文件之外,还能用来处理二进制文件的数据.InputStream类和OutputStream类是所有字节流的父类. InputStream类 ...
- java学习笔记-输入输出流
================File类 =====================InputStream ==================OutputStream ============== ...
随机推荐
- MVVMLight学习笔记(二)---MVVMLight框架初探
一.MVVM分层概述 MVVM中,各个部分的职责如下: Model:负责数据实体的结构处理,与ViewModel进行交互: View:负责界面显示,与ViewModel进行数据和命令的交互: View ...
- The Second Week lucklyzpp
The Second Week 文件通配符模式 在Linux系统中预定义的字符类 1.显示/etc目录下,以非字母开头,后面跟了一个字母以及其它任意长度任意字符的文件或目录 2.复制/etc目录下 ...
- 及上一篇linux安装mysql的说明
mysql8.0安全策略 1 密码规定:数字英文大小写加特殊符号组成(可以不按照规则,详情去百度设置) 2. mysql数据库用户密码字段不再是password 而是authentication_st ...
- Learning ROS: Roslaunch tips for large projects
Design tip: Top-level launch files should be short, and consist of include's to other files correspo ...
- java对象的引用级别
解释 在java中也有引用的概念,其实就可以认为是变量.标题中的引用级别是指变量与对象之前的引用级别.java中分为4种,按引用强弱关系排序分别是:强引用.软引用.弱引用.虚引用. 强引用(Stron ...
- 对于MySQL远程连接中出现的一个问题总结
2021年9月3日更新补充 (真的心累,本来是个小问题,但是网上帖子都基本差不多,基本都是相同的操作,导致搜了半个多小时才解决) 一.首先为什么要重新发一次呢,因为我发现上次写的这个记录是不完善甚至是 ...
- 分布式技术专题-分布式协议算法-带你彻底认识Paxos算法、Zab协议和Raft协议的原理和本质
内容简介指南 Paxo算法指南 Zab算法指南 Raft算法指南 Paxo算法指南 Paxos算法的背景 [Paxos算法]是莱斯利·兰伯特(Leslie Lamport)1990年提出的一种基于消息 ...
- Django——Paginator分页功能练习
1.路由urls.py from django.contrib import admin from django.urls import path from app01.views import in ...
- 前端路由原理之 hash 模式和 history 模式
什么是路由? 个人理解路由就是浏览器 URL 和页面内容的一种映射关系. 比如你看到我这篇博客,博客的链接是一个 URL,而 URL 对应的就是我这篇博客的网页内容,这二者之间的映射关系就是路由. 其 ...
- Asp.net Core Jwt简单使用
.net 默认新建Api项目不需要额外从Nuget添加Microsoft.AspNetCore.Authentication.JwtBearer appsettings.json { "Lo ...