Python_关于python2的encode(编码)和decode(解码)的使用
在使用Python2时,我们习惯于在文件开头声明编码
# coding: utf-8
不然在文件中出现中文,运行时就会报错 SyntaxError: Non-ASCII character... 之类,这是因为python2的文件编码默认使用的ascii,ascii码是不支持中文的。
如果在开头声明了编码,文件编码就会变为utf-8。
python执行过程的编解码
python使用的unicode类型作为编码的基础类型,默认情况下,python在执行文件过程中的编解码为 str-->unicode-->str,当我们在python开头声明utf-8编码后,编解码就变为了 str-->ascii-->str
举个简单例子,就可以验证这个现象。
# coding:utf-8
s = "我要学Python"
print(1, s)

从打印结果可以看出,我们没有做任何处理,中文在执行过程就被处理成了ascii码
encode&decode
在了解了Python执行过程的编码转换后,那我们自己如果转换编码该如何实现呢?这里就得使用两个内置方法 encode编码和decode解码。
例如:
# coding:utf-8
s = "我要学Python"
s.encode("utf-8") # 编码
s.decode("utf-8") # 解码
上面是方法的简单运用,但是执行上面代码,第3行就会出现编解码过程中常见的一个报错
UnicodeDecodeError: 'ascii' codec can't decode byte 0xe6 in position 0: ordinal not in range(128)

简单分析下,明明执行的encode方法,为什么会抛decode错误呢?这就要从上面介绍的python执行过程来分析了。
在执行encode方法编码时,python先要解码,而Python解码默认用unicode格式,而文件开头指定的编码格式为ascii,这就导致编码格式与解码格式不一致,从而产生了报错 ascii 不能解码成 unicode。
要解决这个问题,只需要在编码前,用utf-8格式解码就可以了
s = "我要学Python"
s.decode("utf-8").encode("utf-8") # 编码
s.decode("utf-8") # 解码

中文乱码解决方法
在了解编解码过程后,我们来解决实际遇到的问题:接口响应中文乱码!
比如:在接口测试中,有些响应类似 "\u9875\u9762\u4e0d\u5b58\u5728" 的响应内容,看起来就像乱码

注意看乱码前面有个u ,这表示使用的unicode编码字符。可用以下方法进行解码:
# 直接在 unicode 字符串前加u ===> 使用Python机制自动解码
s = u"\u9875\u9762\u4e0d\u5b58\u5728"
print(s) # 打印:页面不存在。因为字符串为unicode编码格式,python在执行过程中,默认就是使用的unicode解码,编解码类型一致,就看到了中文打印内容 # 使用 decode 方法解码成中文 ===> 主动解码
s = "\u9875\u9762\u4e0d\u5b58\u5728"
print(s.decode("unicode_escape"))
常见问题
格式化带有中文的字符串报错
格式拼接的字符串包含中文,会抛错:UnicodeDecodeError: 'ascii' codec can't decode byte 0xe5 in position 0: ordinal not in range(128)
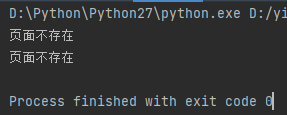
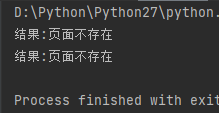
# coding:utf-8 s = "\u9875\u9762\u4e0d\u5b58\u5728" # 拼接的字符串 不包含 中文字符===>正常
print("result: %s" % s.decode("unicode_escape")) # 拼接的字符串 包含 中文字符串===>异常
print("结果: %s" % s.decode("unicode_escape"))

问题分析:
解决方法:
统一编码格式
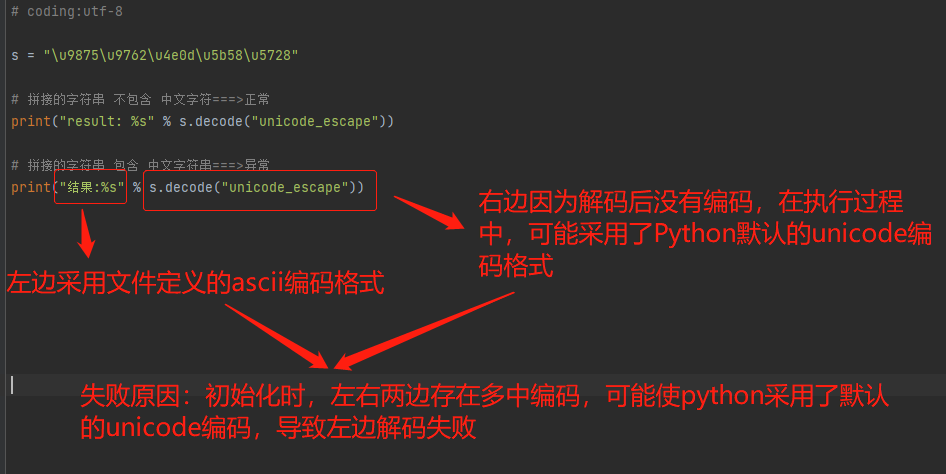
# coding:utf-8 s = "\u9875\u9762\u4e0d\u5b58\u5728" # 方法1:将右边变为 ascii 编码
print("结果:%s" % s.decode("unicode_escape").encode("utf-8")) # 方法2:将左边变为 unicode 编码
print(u"结果:%s" % s.decode("unicode_escape"))
带有中文的字符串反转后乱码
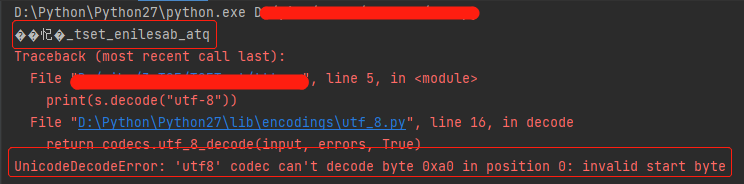
带有中文的字符串使用列表反转方式后乱码,使用decode("utf-8") 解码,报错:UnicodeDecodeError: 'utf8' codec can't decode byte 0xa0 in position 0: invalid start byte
# coding:utf-8 s = "qta_baseline_test_勿删"[::-1]
print(s)
print(s.decode("utf-8"))
问题分析:
中文被Python解析后,先转换成ascii码

当使用列表反转方式后,实际把ascii反转
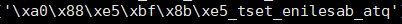
这就导致了反转后的乱码无法被decode("utf-8")正常解码
解决方法:
因为采用的utf-8编码,所以先使用utf-8解码,解码后再反转
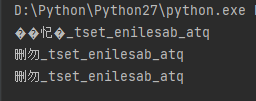
# coding:utf-8 s = "qta_baseline_test_勿删"[::-1]
print(s) s = "qta_baseline_test_勿删".decode("utf-8")[::-1]
print(s)
s = s.encode("utf-8") # 为了后续字符串能正常使用,建议在按原编码方式编码
print(s)
Python_关于python2的encode(编码)和decode(解码)的使用的更多相关文章
- python编码问题 decode与encode
参考: http://www.jb51.net/article/17560.htm 如果要在python2的py文件里面写中文,则必须要添加一行声明文件编码的注释,否则python2会默认使用ASCI ...
- pyhton字符编码问题--decode和encode方法
1 decode和encode方法 字符串在Python内部的表示是unicode编码,因此,在做编码转换时,通常需要以unicode作为中间编码,即先将其他编码的字符串解码(decode)成uni ...
- python2.x 默认编码问题
python2.x中处理中文,是一件头疼的事情.网上写这方面的文章,测次不齐,而且都会有点错误,所以在这里打算自己总结一篇文章. 我也会在以后学习中,不断的修改此篇博客. 这里假设读者已有与编码相关的 ...
- Python2.7字符编码详解
目录 Python2.7字符编码详解 声明 一. 字符编码基础 1.1 抽象字符清单(ACR) 1.2 已编码字符集(CCS) 1.3 字符编码格式(CEF) 1.3.1 ASCII(初创) 1.3. ...
- 一篇文章助你理解Python2中字符串编码问题
前几天给大家介绍了unicode编码和utf-8编码的理论知识,没来得及上车的小伙伴们可以戳这篇文章:浅谈unicode编码和utf-8编码的关系.下面在Python2环境中进行代码演示,分别Wind ...
- python2和python3编码问题
欢迎加入python学习交流群 667279387 一.什么是编解码 1.什么是unicode 2.编码方式 二.python中的编解码 1.python2 (1).encode() 和 .decod ...
- 在python2中的编码
在python2中的编码 #_author:star#date:2019/10/29'''字符编码:ASCII:只能存英文和拉丁字符,gb2312:只能6700中文,1980年gbk1.0:存了200 ...
- Python2 和 Python3 编码问题
基本存储单元 位(bit, b):二进制数中的一个数位,可以是0或者1,是计算机中数据的最小单位. 字节(Byte,B):计算机中数据的基本单位,每8位组成一个字节. 1B = 8b 各种信息在计算机 ...
- javascript处理HTML的Encode(转码)和Decode(解码)总结
HTML的Encode(转码)和解码(Decode)在平时的开发中也是经常要处理的,在这里总结了使用javascript处理HTML的Encode(转码)和解码(Decode)的常用方式 一.用浏览器 ...
随机推荐
- Docker(4)-docker常用命令
帮助命令 docker version # 查看docker的版本信息 docker info # 查看docker的系统信息,包含镜像和容器的数量 docker --help # 帮助命令 dock ...
- for循环中的变量泄漏
经典的案例 let arr = [] for(var i =0;i<=5;i++){ arr[i]= function fn(){ console.log(i) } } arr[0]() //6 ...
- [HarekazeCTF2019]baby_rop
看到名字就想到了用rop来做这道题 老样子chescksec和file一下 可以看到是64位的程序开启了nx保护,把程序放到idax64里 可以看到有system和/bin/sh,/bin/sh无法跟 ...
- 0RAYS元旦招新赛
一共有4道pwn题,题目不算难,但是挺考验调试能力的. pie 一个main函数就四次溢出... 第一次leak canary,第二次leak libc,第三次直接覆盖返回地址为one_gadgets ...
- 延时间隔(Project)
<Project2016 企业项目管理实践>张会斌 董方好 编著 像"饭前洗手"这种事,绝大部分情况下,是洗完手马上就可以动筷子开吃,但总会有意外,比如手都洗好了,突然 ...
- M语言的写、改、删(Power Query 之 M 语言)
M语言基本上和其他语言一样,用敲键盘的方式写入.修改.删除,这个是废话. M语言可以在[编辑栏]或[高级编辑器]里直接写入.修改.删除,这个也是废话. M语言还有个地方可以写入.修改.删除,就是[自定 ...
- 论文翻译:2021_MetricGAN+: An Improved Version of MetricGAN for Speech Enhancement
论文地址:MetricGAN+:用于语音增强的 MetricGAN 的改进版本 论文代码:https://github.com/JasonSWFu/MetricGAN 引用格式:Fu S W, Yu ...
- Uni-app原生插件入门使用教程「2」:如何离线使用原生插件
当HBuilderX中提供的能力无法满足App功能需求,需要通过使用Andorid/iOS原生开发实现时,可使用App离线SDK开发原生插件来扩展原生能力. 如使用Uniapp开发直播功能时,需要调用 ...
- 【LeetCode】1170. Compare Strings by Frequency of the Smallest Character 解题报告(C++)
作者: 负雪明烛 id: fuxuemingzhu 个人博客: http://fuxuemingzhu.cn/ 目录 题目描述 题目大意 解题方法 双重循环 日期 题目地址:https://leetc ...
- 【LeetCode】990. Satisfiability of Equality Equations 解题报告(C++ & python)
作者: 负雪明烛 id: fuxuemingzhu 个人博客: http://fuxuemingzhu.cn/ 目录 题目描述 题目大意 解题方法 DFS 并查集 日期 题目地址:https://le ...