【Spark】RDD(Resilient Distributed Dataset)究竟是什么?
基本概念
官方文档
介绍RDD的官方说明:http://spark.apache.org/docs/latest/rdd-programming-guide.html
概述
含义
RDD (Resilient Distributed Dataset) 叫做 弹性分布式数据集,是Spark中最基本的数据抽象,它代表一个不可变、可分区、里面的元素可并行计算的集合。RDD具有数据流模型的特点:自动容错、位置感知性调度和可伸缩性。RDD允许用户在执行多个查询时显式地将数据缓存在内存中,后续的查询能够重用这些数据,这极大地提升了查询速度。
Resilient —— RDD中的数据优先装在内存当中进行处理,如果内存不够用了,就将数据放到磁盘上面去处理。
Distributed —— RDD中的数据是分布式存储的,可用于分布式计算。
Dataset —— 一个数据集合,用于存放数据的。
RDD出现的原因
RDD是Spark的基石,是实现Spark数据处理的核心抽象。
最初,第一代计算引擎为Hadoop的MapReduce时,开始可以使用代码来实现数据分析处理等。但这种方法需要使用大量代码,比较复杂,不算高效。
之后,第二代计算引擎——Hive出现后,使用hql来实现数据分析,摆脱了MapReduce的繁琐的代码。但这种方法的缺点依然比较明显,就是执行效率慢。
第三代计算引擎以impala、Spark为代表的内存计算框架,开始将数据尽量放到内存中计算,RDD的概念也伴随而生。
五大属性
- A list of partitions 分区列表
- A function for computing each split 作用在每一个文件切片上面的函数
- A list of dependencies on other RDDs 依赖于其他的一些RDD
- Optionally, a Partitioner for key-value RDDs (e.g. to say that the RDD is hash-partitioned) 可选项:对于key,value对的rdd,有分区函数
- Optionally, a list of preferred locations to compute each split on (e.g. block locations for
an HDFS file) 可选项:数据的位置优先性来进行计算。移动计算比移动数据便宜
所谓移动计算比移动数据便宜,是指 如果文件在哪一台服务器上面,就在哪一台服务器上面启动task进行运算,尽量避免数据的拷贝
1.对于RDD来说,每个分片都会被一个计算任务处理,并决定并行计算的粒度,如果文件的block个数小于等于2,那么默认分区为2,如果大于等于2,则分区数为block的个数。
2.Spark中每个RDD都会实现compute函数,以此来达到让RDD的计算都是以分片为单位的目的。compute函数会对迭代器进行复合,不需要保存每次计算的结果。
3.RDD每次转换都会生成一个新的RDD,所以RDD之间就会形成类似于流水线一样的前后依赖关系,在部分分区数据丢失时,Spark可以通过这个依赖关系重新计算丢失的分区数据,而不是对RDD的所有分区重新计算。
4.Spark中实现了两种类型的分片函数,一种是基于哈希的HashPartitioner,一种是基于范围的RangePartitioner。只有对于key-value的RDD才会有Partitioner,非key-value的RDD的Partitioner的值是None。Partitioner函数不但决定了RDD本身的分片数量,也决定了parent RDD Shuffle输出时的分片数量。
以单词统计为例,一张图熟悉RDD当中的五大属性
解构图
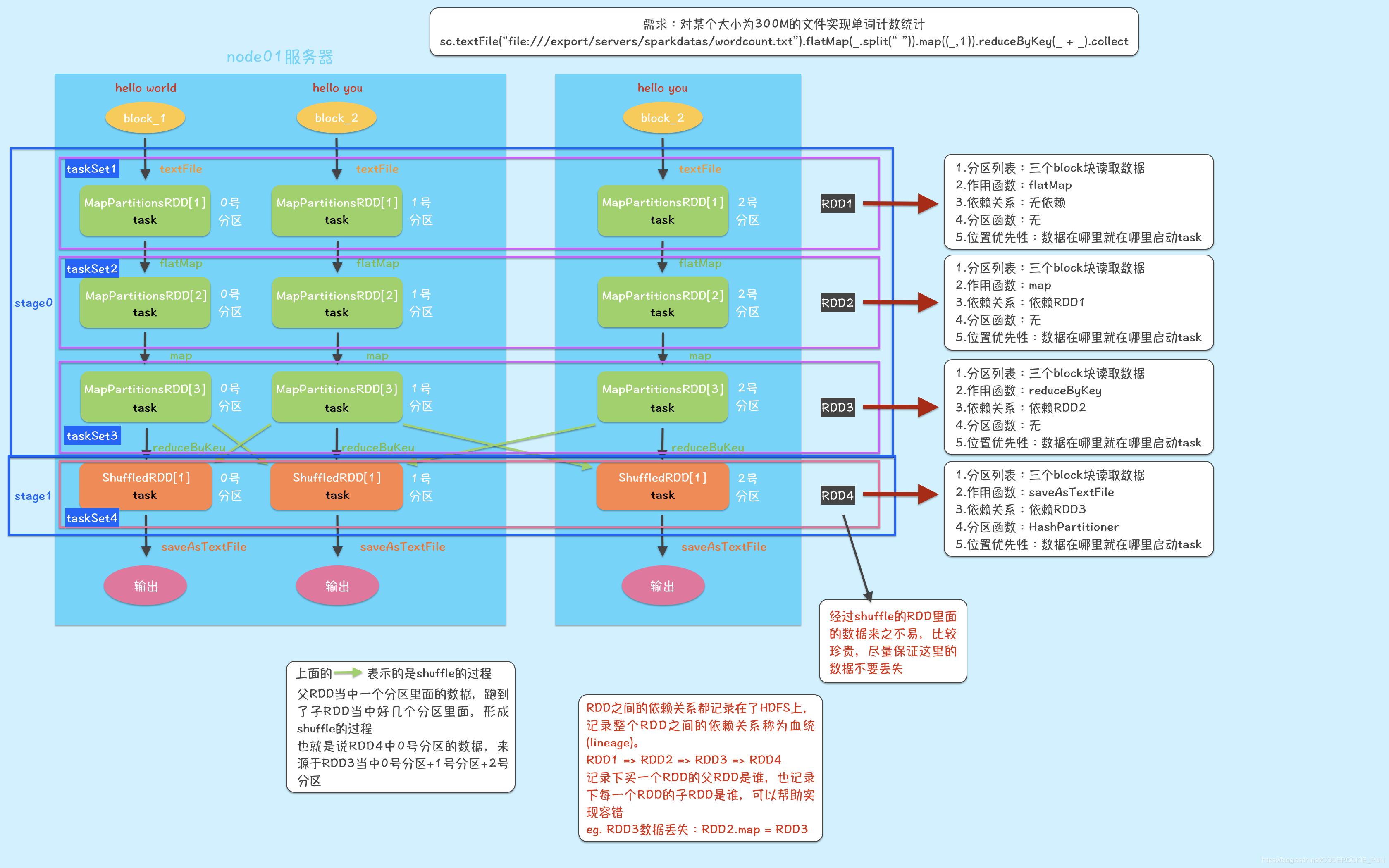
RDD弹性
一、自动进行内存以及磁盘文件切换
二、基于血统lineage的高效容错性。lineage记录了rdd之间的依赖关系
三、task执行失败自动进行重试
四、stage失败自动进行重试
五、checkpoint实现数据的持久化保存
基于RDDs之间的依赖,RDDs会形成一个有向无环图DAG,该DAG描述了整个流式计算的流程,实际执行的时候,RDD是通过血缘关系(Lineage)一气呵成的,即使出现数据分区丢失,也可以通过血缘关系重建分区
RDD特点
分区
只读
rdd当中的数据是只读的,不能更改
依赖
缓存
常用的rdd我们可以给缓存起来
checkpoint
对于一些常用的rdd我们也可以试下持久化
【Spark】RDD(Resilient Distributed Dataset)究竟是什么?的更多相关文章
- Spark RDD(Resilient Distributed Dataset)
基于数据集的处理:从物理存储上加载数据,然后操作数据,然后写入物理存储设备.比如Hadoop的MapReduce. 缺点:1.不适合大量的迭代 2. 交互式查询 3. 不能复用曾经的 ...
- spark RDD,DataFrame,DataSet 介绍
弹性分布式数据集(Resilient Distributed Dataset,RDD) RDD是Spark一开始就提供的主要API,从根本上来说,一个RDD就是你的数据的一个不可变的分布式元素集合,在 ...
- 2. RDD(弹性分布式数据集Resilient Distributed dataset)
*以下内容由<Spark快速大数据分析>整理所得. 读书笔记的第二部分是讲RDD.RDD 其实就是分布式的元素集合.在 Spark 中,对数据的所有操作不外乎创建RDD.转化已有RDD以及 ...
- [bigdata] Spark RDD整理
1. RDD是什么RDD:Spark的核心概念是RDD (resilient distributed dataset),指的是一个只读的,可分区的弹性分布式数据集,这个数据集的全部或部分可以缓存在内存 ...
- Spark RDD基本概念与基本用法
1. 什么是RDD RDD(Resilient Distributed Dataset)叫做分布式数据集,是Spark中最基本的数据抽象,它代表一个不可变.可分区.里面的元素可并行计算的集合.RDD具 ...
- RDD, DataFrame or Dataset
总结: 1.RDD是一个Java对象的集合.RDD的优点是更面向对象,代码更容易理解.但在需要在集群中传输数据时需要为每个对象保留数据及结构信息,这会导致数据的冗余,同时这会导致大量的GC. 2.Da ...
- Spark RDD理解-总结
1.spark是什么 快速.通用.可扩展的分布式计算引擎. 2. 弹性分布式数据集RDD RDD(Resilient Distributed Dataset),是Spark中最基本的数据抽象结构,表示 ...
- Spark的核心RDD(Resilient Distributed Datasets弹性分布式数据集)
Spark的核心RDD (Resilient Distributed Datasets弹性分布式数据集) 原文链接:http://www.cnblogs.com/yjd_hycf_space/p/7 ...
- RDD内存迭代原理(Resilient Distributed Datasets)---弹性分布式数据集
Spark的核心RDD Resilient Distributed Datasets(弹性分布式数据集) Spark运行原理与RDD理论 Spark与MapReduce对比,MapReduce的计 ...
随机推荐
- 新时代前端必备神器 Snapjs之弹动效果
有人说不会 SVG 的前端开发者不叫开发者,而叫爱好者.前端不光是 Angularjs 了,这时候再不学 SVG 就晚了!(如果你只会 jQuery 就当我没说...)这里我就给大家分享一个前几天在别 ...
- 用Python画的,5 种非传统的可视化技术,超炫酷的动态图
数据可以帮助我们描述这个世界.阐释自己的想法和展示自己的成果,但如果只有单调乏味的文本和数字,我们却往往能难抓住观众的眼球.而很多时候,一张漂亮的可视化图表就足以胜过千言万语.本文将介绍 5 种基于 ...
- 遇到自己喜欢的视频无法下载,python帮你解决
问题描述 python是一种非常好用的爬虫工具.对于大多数的爬虫小白来说,python是更加简洁,高效的代码.今天就用实际案例讲解如何爬取动态的网站视频. 环境配置:python3:爬虫库reques ...
- How Many Answers Are Wrong HDU - 3038 (经典带权并查集)
题目大意:有一个区间,长度为n,然后跟着m个子区间,每个字区间的格式为x,y,z表示[x,y]的和为z.如果当前区间和与前面的区间和发生冲突,当前区间和会被判错,问:有多少个区间和会被判错. 题解:x ...
- Flask接口开发过程中的心得2019.10.03
完善了一下慕课网实战中的post接口开发,得到了一些进步: 代码如下: #coding=utf-8 from flask import Flask from flask import request ...
- async,await执行流看不懂?看完这篇以后再也不会了
昨天有朋友在公众号发消息说看不懂await,async执行流,其实看不懂太正常了,因为你没经过社会的毒打,没吃过牢饭就不知道自由有多重要,没生过病就不知道健康有多重要,没用过ContinueWith就 ...
- 2. js的异步
1. 回掉2. promise3. Generator4. Async/await
- 二、Go语言开发环境安装与编写第一个Hello World
本系列文章均为学习过程中记录的笔记,欢迎和我一起来学习Go语言. 全文使用环境如下: Go语言版本:1.13 操作系统:deepin 使用工具:Goland开发工具 Go语言追溯历史 Go语言2009 ...
- 用python把技术文档中,每个模块系列截图生成一个动态GIF
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 最近在写技术文档的时候,发现一个问题.对于每个技术步骤,都需要一个截图,这 ...
- python学习09元组
'''元组''''''元组Tuple:1.不可变的序列:元祖不能对元素进行变动(字符串也不可以,但是列表可以) 2.元组用小括号()表示(列表是中括号[],字符串是“”) 3.可以存储各种数据类型 4 ...