详解GaussDB bufferpool缓存策略,这次彻底懂了!
摘要:华为云GaussDB(for mysql)是华为云自主研发的最新一代云原生数据库,采用计算存储分离、日志即数据的架构设计。具备极致可靠、极致性价比、多为扩展、完全可信等诸多特性。
一 、GaussDB(for mysql)简介
华为云GaussDB(for mysql)是华为云自主研发的最新一代云原生数据库,采用计算存储分离、日志即数据的架构设计。通过IO卸载、日志压缩合并、批量处理、软硬件垂直整合等技术,使数据库性能方面有了大幅提升。同时存储层采用多副本,多az部署,增强数据可靠性。具备极致可靠、极致性价比、多为扩展、完全可信等诸多特性。
GaussDB(for mysql)采用了计算存储分离、日志即数据的架构,一部分计算能力下推到存储层。存储层需要通过consolidation不断将写入的日志应用到页面上,从而将日志回收掉。另外SQL层从存储层读取页面时,也需要将日志回放到相应的版本从而获得对应版本的页面。如果每次都从磁盘读取页面,IO时延较大,这里将成为整个回放流程的瓶颈。
根据数据库一贯的做法,我们需要一个缓存(bufferpool),把经常访问的页面放在缓存中,从而加快页面读取的速度。但是存储层能够分配给bufferpool的资源非常有限,我们需要根据bufferpool的使用特点设计一个高效的缓存策略。
二、一些常见的缓存淘汰算法
缓存一般从以下三个特征进行描述:
- 命中率
返回正确结果数/请求缓存次数,命中率问题是缓存中的一个非常重要的问题,它是衡量缓存有效性的重要指标。命中率越高,表明缓存的使用率越高。
- 最大元素(或最大空间)
缓存中可以存放的最大元素的数量,一旦缓存中元素数量超过这个值(或者缓存数据所占空间超过其最大支持空间),那么将会触发缓存启动清空策略根据不同的场景合理的设置最大元素值往往可以一定程度上提高缓存的命中率,从而更有效的时候缓存。
- 淘汰(替换)策略
如上描述,缓存的存储空间有限制,当缓存空间被用满时,如何保证在稳定服务的同时有效提升命中率?这就由淘汰(替换)策略来处理,设计适合自身数据特征的淘汰策略能有效提升命中率。
因此,选择一个适合使用场景的淘汰(替换)策略非常重要,能够大大提升缓存命中率,从而加速业务处理。
缓存的淘汰(替换)根据访问模式可以分为基于时间或者访问频率两类,下面分别对这两类进行详细描述。
基于访问时间:此类算法按各缓存项的被访问时间来组织缓存队列,决定替换对象,如LRU。
基于访问频率:此类算法用缓存项的被访问频率来组织缓存。如LFU、LRU-2、2Q、LIRS。
1. LRU
基本思想:如果数据最近被访问过,那么将来被访问的几率也更高
常见实现方法:
一般采用unordered_map+list来实现,访问数据时,直接从unordered_map通过key在O(1)时间内获取到所需数据。有新数据时,插入到链表的头部;当缓存命中时,也将数据移动到链表头部;当缓存满时将链表尾部的数据丢弃。
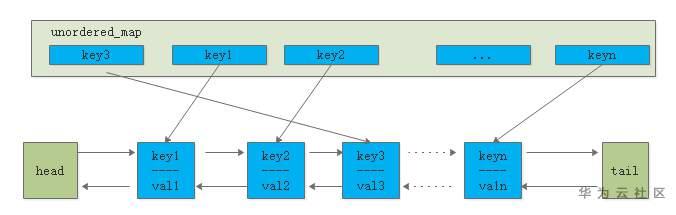
命中率分析
当存在热点数据时,LRU的效率很好,但偶发性的、周期性的批量操作会导致LRU命中率急剧下降,缓存污染情况比较严重。
Mysql对朴素LRU算法的改进:
由于朴素的LRU算法会存在缓存污染问题,若直接读取到的页放入到LRU的首部,那么某些SQL操作可能会使缓冲池中的页被刷新出,从而影响缓冲池的效率。常见的这类操作为索引或数据的扫描操作。这类操作需要访问表中的许多页,甚至是全部的页,而这些页通常来说又仅在这次查询操作中需要,并不是活跃的热点数据。如果页被放入LRU列表的首部,那么非常可能将所需要的热点数据页从LRU列表移除,而在下一次需要读取该页时,InnoDB存储引擎需要再次访问磁盘。
解决方案:
InnoDB存储引擎引入了另一个参数来进一步管理LRU列表,这个参数是Innodb_old_blocks_time,用于表示页读取到mid位置后需要等待多久才会被加入到LRU列表的热端。链表按照5:3的比例分为young区和old区,新加入的数据放在old区,若old区的数据在LRU链表中存在时间超过了1秒,则将其移动到链表头部,如果数据在LRU old区链表中存在的时间少于1秒,则保持位置不变,淘汰时优先淘汰old区的数据。这样可以避免全表扫描对LRU链表的污染,全表扫描的冷数据很快会被淘汰出去。
2. LFU
基本思想:如果数据过去被访问多次,那么将来被访问的频率也更高。
注意LFU和LRU的区别,LRU的淘汰规则是基于访问时间,而LFU是基于访问次数常见实现方法:
与LRU类似,LFU一般也采用unordered_map+list来实现,访问数据时,直接从unordered_map通过key在O(1)时间内获取到所需数据。有新数据时,插入到链表的尾部;
当缓存命中时,增加该key的引用计数,链表按照引用计数排序。为了避免节点在链表中频繁移动,一般会将链表划分为多个区域或者使用多个链表,如果引用计数落入某个范围,将该节点加入到相应的链表中,当引用计数超出阈值时将当前节点移动到上一个区间的链表。当缓存满时将引用计数最小的区域的数据丢弃。
命中率分析
LFU命中率要优于LRU,且能够避免周期性或者偶发性的操作导致缓存命中率下降的问题,但LFU需要记录数据的历史访问记录,一旦数据访问模式改变,LFU需要更长时间来适用新的访问模式,即LFU存在历史数据影响将来数据的"缓存污染"问题。
3. LRU-K
LRU-K中的K代表最近使用的次数,因此LRU可以认为是LRU-1。LRU-K的主要目的是为了解决LRU算法"缓存污染"的问题,其核心思想是将"最近使用过1次"的判断标准扩展为"最近使用过K次"
常用实现如下:
数据第一次被访问,加入到访问历史列表;如果数据在访问历史列表里后没有达到K次访问,则按照LRU淘汰;当访问历史队列中的数据访问次数达到K次后,将数据索引从历史队列删除,将数据移到缓存队列中,并缓存此数据,缓存队列重新按照时间排序;缓存数据队列中被再次访问后,重新排序;需要淘汰数据时,淘汰缓存队列中排在末尾的数据,即淘汰"倒数第K次访问离现在最久"的数据。
命中率分析:
LRU-K具有LRU的优点,同时能够避免LRU的缺点,实际应用中LRU-2是综合各种因素后最优的选择,LRU-3或者更大的K值命中率会高,但适应性差,需要大量的数据访问才能将历史访问记录清除掉。LRU-K降低了"缓存污染"带来的问题,命中率比LRU要高。
4. 2Q
算法类似于LRU-2,不同点在于2Q将LRU-2算法中的访问历史队列改为一个FIFO队列,即2Q有两个缓存队列:FIFO队列和LRU队列
常见实现方法:
当数据第一次访问时,2Q算法将数据缓存在FIFO队列里面,当数据第二次被访问时,则将数据从FIFO队列移到LRU队列里面,两个队列各自按照自己的方法淘汰数据。
命中率分析:
2Q LRU-K类似,都是LRU的改进版,命中率比LRU要高,可以避免LRU污染带来的问题。
上面介绍了4个常用的缓存淘汰算法,实现起来也不是很复杂。当然还有一些其他的算法,这里就不再介绍了,感兴趣的朋友可以查找资料学习一下。
三、 GaussDB(for mysql)bufferpool的缓存策略
GaussDB(for mysql)目前支持两种缓存淘汰策略:LRU和LFU,这两种淘汰算法都是改进过的。
1. 改进的LFU算法:
LFU在实现上采用unordered_map+list方式实现,访问数据时,直接从unordered_map通过key在O(1)时间内获取到所需数据。为了避免数据在链表中频繁移动,将链表按照引用计数分成多个区间,当缓存命中时,增加引用计数,若引用计数仍落在原来的区间,保持数据在链表中的位置不动,如果引用计数落入新的区间,将数据移动到相应位置。
为了避免一些频繁访问的数据后面不再访问,但是引用计数很大,导致不能被淘汰,因此引入“老化”策略,每隔一段时间将引用计数值衰减一下,这样就可以将一些引用计数较大,但是当前不怎么访问的数据淘汰出去。
一些被淘汰出去的数据我们还会在历史记录里面保留一段时间其对应的引用计数,下次该数据再次被加入缓存时,可以“投胎转世”,可以在上次的引用计数基础上开始计数。这样可以更精确的反应数据被访问的频率。
LFU的缓存命中率较高,但是在“老化”的过程中需要对链表加锁,这样会阻塞其他地方的访问。
2. 改进的LRU算法:
与mysql的改进LRU算法类似,也是将链表划分为hot和cold两个区,数据第一次被加入时先放入cold区,当再次命中时移入hot区。淘汰时优先淘汰cold区的数据。同时我们引入了一个lockfree的队列,以免在flush page时对链表加锁,增强缓冲操作的并发度。
四、下一步的改进
虽然我们引入了改进版的LRU和LFU算法,但是在大数据量时,按照一些模拟分析数据,还有一定的改进空间。后面在两个算法的基础上进一步改进,提升缓存的命中率。
详解GaussDB bufferpool缓存策略,这次彻底懂了!的更多相关文章
- 干货!上古神器 sed 教程详解,小白也能看的懂
目录: 介绍工作原理正则表达式基本语法数字定址和正则定址基本子命令实战练习 介绍 熟悉 Linux 的同学一定知道大名鼎鼎的 Linux 三剑客,它们是 grep.awk.sed,我们今天要聊的主角就 ...
- 一文详解Redis键过期策略
摘要:Redis采用的过期策略:惰性删除+定期删除. 本文分享自华为云社区<Redis键过期策略详解>,作者:JavaEdge. 1 设置带过期时间的 key # 时间复杂度:O(1),最 ...
- 详解GaussDB(DWS) explain分布式执行计划
摘要:本文主要介绍如何详细解读GaussDB(DWS)产生的分布式执行计划,从计划中发现性能调优点. 前言 执行计划(又称解释计划)是数据库执行SQL语句的具体步骤,例如通过索引还是全表扫描访问表中的 ...
- 详解三种缓存过期策略LFU,FIFO,LRU(附带实现代码)
在学操作系统的时候,就会接触到缓存调度算法,缓存页面调度算法:先分配一定的页面空间,使用页面的时候首先去查询空间是否有该页面的缓存,如果有的话直接拿出来,如果没有的话先查询,如果页面空间没有满的时候, ...
- 详解GaussDB(for MySQL)服务:复制策略与可用性分析
摘要:本文通过介绍GaussDB(for MySQL)读写路径,分析其可用性. 简介 数据持久性和服务可用性是数据库服务的关键特征. 在实践中,通常认为拥有 3 份数据副本,就足以保证持久性. 但是 ...
- http缓存详解,http缓存推荐方案
前言 通过本文,你将了解到http缓存机制是怎样的,no-cache到底有没有缓存,地址栏回车,F5,ctrl+F5的区别,以及当下较为推荐的缓存方案等. 自从和前端组的同事一起整了个前端扫盲计划,想 ...
- php笔记07:http响应详解(禁用缓存设置和文件下载)
演示如何通过Http响应控制页面缓存,在默认情况下,浏览器是会缓存页面的1.禁用缓存设置 (1).我在...\htdocs\http文件夹,写一个cache.php文件如下: <?php ech ...
- Hibernate框架笔记04HQL_QBC查询详解_抓取策略优化机制
目录 1. Hibernate的查询方式 1.1 方式一:OID查询 1.2 方式二:对象导航查询 1.3 方式三:HQL方式 1.4 方式四:QBC查询 1.5 方式五:SQL查询 2. 环境搭建 ...
- JAVA设计模式详解(一)----------策略模式
策略模式,顾名思义就是设计一个策略算法,然后与对象拆分开来将其单独封装到一系列策略类中,并且它们之间可以相互替换.首先LZ举一个例子为大家引出这一个模式. 例子:某公司的中秋节奖励制度为每个员工发放2 ...
随机推荐
- Centos6.5--svn搭建
0x01 配置好镜像源安装svn yum install subversion -y 0x02 安装完成之后在/opt下面新建一个svn的目录,当然也可以在其他的地方建立svn目录,这个看个人爱好. ...
- 解析HOT原理
2020-06-09 19:31:01 一.疑问 前段时间:QQ群里有人对“这个表(0,4)这行数据我做了update操作,查看索引的page数据,看到索引一直指向(0,4),用ctid='(0,4) ...
- 关于thinkhphp3.1中废弃 preg_replace /e 修饰符
警告:preg_replace(): The /e modifier is deprecated, use preg_replace_callback instead 网上查了下 发现 php5.5版 ...
- [转] linux操作系统下c语言编程入门--基础知识
点击阅读原文 这篇文章介绍在LINUX下进行C语言编程所需要的基础知识.在这篇文章当中,我们将会学到以下内容: 1. 源程序编译 2. Makefile的编写 3. 程序库 ...
- DockerFile构建镜像和Docker仓库
利用commit理解镜像构成 注意: docker commit 命令除了学习之外,还有一些特殊的应用场合,比如被入侵后保存现 场等.但是,不要使用 docker commit 定制镜像,定制镜像应该 ...
- AJAX的GET请求、POST请求
感谢:链接(视频讲解很详细) AJAX(Asynchronous Javascript and XML):异步的JavaScript和XML(不需要刷新网页就可以更新网页数据) XML:百度百科 是一 ...
- Looooops(求解同余方程、同余方程用法)【拓展欧几里得】
Looooops(点击) A Compiler Mystery: We are given a C-language style for loop of type for (variable = A; ...
- iOSdelegate、Notification、block区别
1.delegate与block一般用于1对1的通信交互.delegate需先定义好协议方法,代理对象实现协议方法且需要建立代理关系才可以通信. 2.block使用简洁,如果通信事件较多,建议使用de ...
- FastStone+ImageReady+Kutools plus导入图片到Excel单元格
先前打算自己做一个也附带训练下,发现有下面方法也好. 1)做帮助文档时需要一种格式(需要将图片导入到Excel中时,假如是按此法归类汇总) 2)FastStone滚动截图 粘贴到Photo ...
- 华为海思搞定4K60fps!Vmate掌上云台相机国内首发
目录 Snoppa Vmate Snoppa Vmate Snoppa Vmate是一款掌上型的高性能4K摄像机,集成了微型机械三轴增稳云台,一体化机身集成可操控式触摸屏,既可以独立使用,也可以无线连 ...