[Spark RDD_add_1] groupByKey & reduceBykey 的区别
【groupByKey & reduceBykey 的区别】
在都能实现相同功能的情况下优先使用 reduceBykey
Combine 是为了减少网络负载
1. groupByKey 是没有 Combine 过程,可以改变 V 的类型
List[]
combineByKeyWithClassTag[CompactBuffer[V]](createCombiner, mergeValue, mergeCombiners, partitioner, mapSideCombine = false)
2. reduceByKey 有 Combine 过程,不能改变 V 的类型
List[]
combineByKeyWithClassTag[V]((v: V) => v, func, func, partitioner)
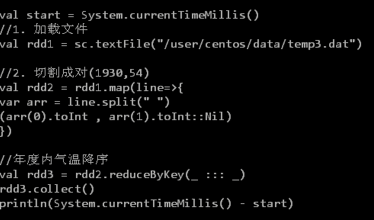
【通过测试气温数据的双排序考察 reduceByKey 和 groupByKey() 的不同】
1.启动 Hadoop 和 Spark 集群
2.上传 temp.txt 数据到 HDFS
3.启动 Shell 进行以下操作
【启动 Shell】
spark-shell --master spark://s101:7077 --deploy-mode client
【test_1】

【test_2】
[Spark RDD_add_1] groupByKey & reduceBykey 的区别的更多相关文章
- Spark中groupBy groupByKey reduceByKey的区别
groupBy 和SQL中groupby一样,只是后面必须结合聚合函数使用才可以. 例如: hour.filter($"version".isin(version: _*)).gr ...
- Spark 学习笔记之 distinct/groupByKey/reduceByKey
distinct/groupByKey/reduceByKey: distinct: import org.apache.spark.SparkContext import org.apache.sp ...
- (九)groupByKey,reduceByKey,sortByKey算子-Java&Python版Spark
groupByKey,reduceByKey,sortByKey算子 视频教程: 1.优酷 2. YouTube 1.groupByKey groupByKey是对每个key进行合并操作,但只生成一个 ...
- spark 例子groupByKey分组计算2
spark 例子groupByKey分组计算2 例子描述: 大概意思为,统计用户使用app的次数排名 原始数据: 000041b232,张三,FC:1A:11:5C:58:34,F8:E7:1E:1E ...
- [Spark][Python]groupByKey例子
Spark Python 索引页 [Spark][Python]sortByKey 例子 的继续: [Spark][Python]groupByKey例子 In [29]: mydata003.col ...
- spark 例子groupByKey分组计算
spark 例子groupByKey分组计算 例子描述: [分组.计算] 主要为两部分,将同类的数据分组归纳到一起,并将分组后的数据进行简单数学计算. 难点在于怎么去理解groupBy和groupBy ...
- Spark TempView和GlobalTempView的区别
Spark TempView和GlobalTempView的区别 TempView和GlobalTempView在spark的Dataframe中经常使用,两者的区别和应用场景有什么不同. 我们以下面 ...
- 015 在Spark中关于groupByKey与reduceByKey的区别
1.groupByKey的源代码 2.groupByKey的使用缺点 不使用groupByKey的主要原因:在大规模的数据下,数据分布不均匀的情况下,可能导致OOM 3.reduceByKey的源代码 ...
- spark RDD,reduceByKey vs groupByKey
Spark中有两个类似的api,分别是reduceByKey和groupByKey.这两个的功能类似,但底层实现却有些不同,那么为什么要这样设计呢?我们来从源码的角度分析一下. 先看两者的调用顺序(都 ...
随机推荐
- 一行一行读Java源码——LinkedBlockingQueue
1.LinkedBlockingQueue概述 Linked:链表+Blocking:阻塞+Queue:队列 Queue:首先想到的是FIFO Linked:,Queue:其结构本质上是线性表,可以有 ...
- Nhibernate + MySQL 类型映射
用SQLyog工具创建表 然后用自动映射工具NHibernate Mapping Generator对表做自动映射,得到 这个是可视化界面,后面有对应的代码. using System; using ...
- 2-1. Creating a Simple Model 使用图形界面设计器创建一个简单的模型
一.创建新项目 二.添加模型文件 三.添加完后,在设计面板空白处右击,创建一个实体 实体集(B) 这里的名称会是对应的数据库表名称!!! ,开始不知道这是什么,生成后才知道表名是这个,以后注意点就行. ...
- Spring技术内幕_IOC容器载入Bean定义资源文件
转自:http://blog.csdn.net/chjttony/article/details/6259723 1.当spring的IoC容器将Bean定义的资源文件封装为Spring的Resour ...
- Java设计模式学习记录-简单工厂模式、工厂方法模式
前言 之前介绍了设计模式的原则和分类等概述.今天开启设计模式的学习,首先要介绍的就是工厂模式,在介绍工厂模式前会先介绍一下简单工厂模式,这样由浅入深来介绍. 简单工厂模式 做法:创建一个工厂(方法或类 ...
- 使用Akka构建集群(一)
概述 Akka提供的非常吸引人的特性之一就是轻松构建自定义集群,这也是我要选择Akka的最基本原因之一.如果你不想敲太多代码,也可以通过简单的配置构建一个非常简单的集群.本文为说明Akka集群构建的学 ...
- zoj 2060 Fibonacci Again(fibonacci数列规律、整除3的数学特性)
题目链接: http://acm.zju.edu.cn/onlinejudge/showProblem.do?problemCode=2060 题目描述: There are another kind ...
- Java SDK夯住(Hang)问题排查
夯住(Hang)是指程序仍在运行,卡在某个方法调用上,没有返回也没有异常抛出:卡住时间从几秒到几小时不等. Java程序发生Hang时,应该首先使用 jstack 把java进程的堆栈信息保存下来 , ...
- [转]How to speed up Magento 2. Maximum Performance
本文转自:https://magedirect.co/how-to-speed-up-magento-2-maximum-performance/ Introduction In this artic ...
- C#基础知识回顾--串行化与反串行化
串行化是指存储和获取磁盘文件.内存或其他地方中的对象.在串行化时,所有的实例数据都保存到存储介质上, 在取消串行化时,对象会被还原,且不能与其原实例区别开来.只需给类添加Serializable属性, ...