Python-爬虫-租房Ziroom
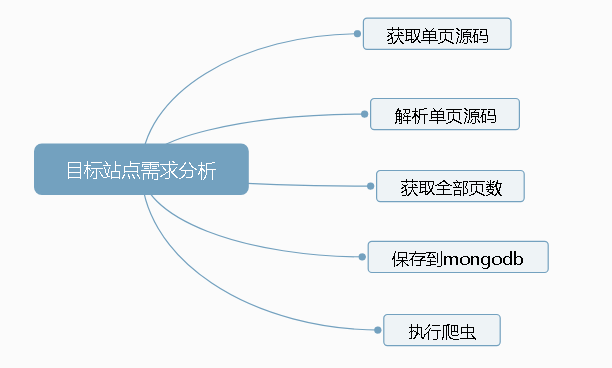
目标站点需求分析
涉及的库
import requests
import time
import pymongo
from lxml import etree
from requests.exceptions import RequestException
获取单页源码
def get_one_page(page):
'''获取单页源码'''
try:
url = "http://sh.ziroom.com/z/nl/z2.html?p=" + str(page)
print('url',url)
headers = {
'Referer':'http://sh.ziroom.com/',
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36'
}
res = requests.get(url,headers=headers)
time.sleep(1)
if res.status_code == 200:
return res.text
return None
except RequestException:
return None
解析单页源码
def parse_one_page(sourcehtml):
'''解析单页源码'''
contentTree = etree.HTML(sourcehtml) #解析源代码
results = contentTree.xpath('//ul[@id="houseList"]/li') #利用XPath提取相应内容
for result in results:
title = result.xpath("./div/h3/a/text()")[0][5:] if len(result.xpath("./div/h3/a/text()")[0]) > 0 else ""
area = " ".join(result.xpath("./div/div/p[1]/span/text()")).replace(" ", "", 1) # 使用join方法将列表中的内容以" "字符连接
nearby = result.xpath("./div/div/p[2]/span/text()")[0].strip() if len(result.xpath("./div/div/p[2]/span/text()"))>0 else ""
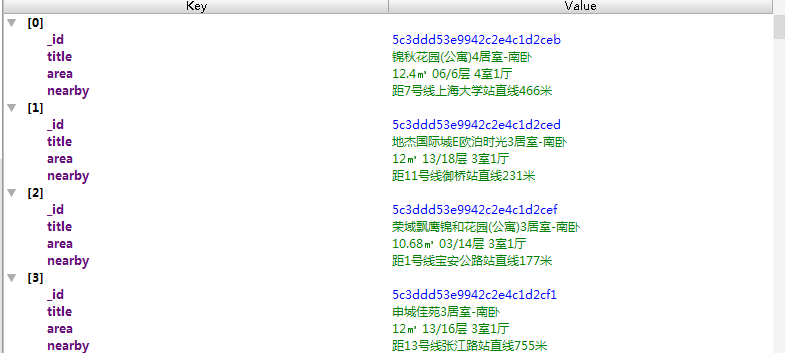
data = {
"title": title,
"area": area,
"nearby": nearby
}
print(data)
save_to_mongodb(data)
抓取总页数,保存到Mongobd中
def get_pages():
"""得到总页数"""
page = 1
html = get_one_page(page)
contentTree = etree.HTML(html)
pages = int(contentTree.xpath('//div[@class="pages"]/span[2]/text()')[0].strip("共页"))
return pages def save_to_mongodb(result):
"""存储到MongoDB中"""
# 创建数据库连接对象, 即连接到本地
client = pymongo.MongoClient(host="localhost")
# 指定数据库,这里指定ziroom和表名
db = client.iroomz
db_table = db.roominfo
try:
#插入到数据库
if db_table.insert(result):
print("抓取成功",result)
except Exception as reason:
print("抓取失败",reason)
def task():
pages = get_pages()
print('总共',pages)
for page in range(1,int(pages)+1):
html = get_one_page(page)
parse_one_page(html)
Python-爬虫-租房Ziroom的更多相关文章
- python 爬虫入门----案例爬取上海租房图片
前言 对于一个net开发这爬虫真真的以前没有写过.这段时间学习python爬虫,今天周末无聊写了一段代码爬取上海租房图片,其实很简短就是利用爬虫的第三方库Requests与BeautifulSoup. ...
- python爬虫项目(scrapy-redis分布式爬取房天下租房信息)
python爬虫scrapy项目(二) 爬取目标:房天下全国租房信息网站(起始url:http://zu.fang.com/cities.aspx) 爬取内容:城市:名字:出租方式:价格:户型:面积: ...
- python 爬虫入门案例----爬取某站上海租房图片
前言 对于一个net开发这爬虫真真的以前没有写过.这段时间开始学习python爬虫,今天周末无聊写了一段代码爬取上海租房图片,其实很简短就是利用爬虫的第三方库Requests与BeautifulSou ...
- Python爬虫(四)——开封市58同城数据模型训练与检测
前文参考: Python爬虫(一)——开封市58同城租房信息 Python爬虫(二)——对开封市58同城出租房数据进行分析 Python爬虫(三)——对豆瓣图书各模块评论数与评分图形化分析 数据的构建 ...
- Python爬虫之PyQuery使用(六)
Python爬虫之PyQuery使用 PyQuery简介 pyquery能够通过选择器精确定位 DOM 树中的目标并进行操作.pyquery相当于jQuery的python实现,可以用于解析HTML网 ...
- FocusBI: 使用Python爬虫为BI准备数据源(原创)
关注微信公众号:FocusBI 查看更多文章:加QQ群:808774277 获取学习资料和一起探讨问题. <商业智能教程>pdf下载地址 链接:https://pan.baidu.com/ ...
- 高德API+Python解决租房问题(.NET版)
源码地址:https://github.com/liguobao/58HouseSearch 在线地址:58公寓高德搜房(全国版):http://codelover.link:8080/ 周末闲着无事 ...
- Python爬虫:设置Cookie解决网站拦截并爬取蚂蚁短租
前言 文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者: Eastmount PS:如有需要Python学习资料的小伙伴可以加 ...
- GitHub 上有哪些优秀的 Python 爬虫项目?
目录 GitHub 上有哪些优秀的 Python 爬虫项目? 大型爬虫项目: 实用型爬虫项目: 其它有趣的Python爬虫小项目: GitHub 上有哪些优秀的 Python 爬虫项目? 大型爬虫项目 ...
- Python爬虫系统化学习(5)
Python爬虫系统化学习(5) 多线程爬虫,在之前的网络编程中,我学习过多线程socket进行单服务器对多客户端的连接,通过使用多线程编程,可以大大提升爬虫的效率. Python多线程爬虫主要由三部 ...
随机推荐
- JS中var、let、const区别? 用3句话概括
使用var声明的变量,其作用域为该语句所在的函数内,且存在变量提升现象: 使用let声明的变量,其作用域为该语句所在的代码块内,不存在变量提升: 使用const声明的是常量,在后面出现的代码中不能再修 ...
- 关闭Android ActionBar
修改Styles.xml中 <resources> <!-- Base application theme. --> <style name="AppTheme ...
- asp.net mvc && asp.net 页面跳转
1.使用传统的Response.Redirect例如string url = "/account/create";Response.Redirect(url); 1.Server. ...
- 【noip 2016】普及组
T1.买铅笔 题目链接 #include<cstdio> #include<algorithm> #include<cstring> using namespace ...
- Linux之恢复误删的文件[针对丢弃到回收站]
1.丢弃到回收站(非RM)掉的文件一般在目录~/.local/share/Trash/files/下: 2.如何恢复呢? 原理很简单,既然它们还在,要么copy,要么移动到一个新的地方即可嘛. //以 ...
- python 关于文件操作
,要求在文件 .py 第六行插入一句话: #cat /root/python/2.py 2 昨夜雨疏风骤1 3 昨夜雨疏风骤2 4 昨夜雨疏风骤3 5 昨夜雨疏风骤4 6 昨夜雨疏风骤5 7 昨夜雨疏 ...
- git撤销中间的某次提交
这几天在开发一个新功能,应为着急上线,所以就把代码提交上去了,当现在有时间又要再改改,又要把我那次提交全部删掉,想重新再写,但是代码已经合了,而且还有其他同事的代码,我的提交在中间的某个部分,所以我想 ...
- Django REST Framework API Guide 05
本节大纲 1.Serializer fields 2.Serializer relations Serializer fields 1.serializer 字段定义在fields.py文件内 2.导 ...
- Tip:HttpServletRequest
HttpServletRequest对象代表客户端的请求,当客户端通过HTTP协议访问服务器时,HTTP请求头中的所有信息都封装在这个对象中,开发人员通过这个对象的方法,可以获得客户这些信息. Tip ...
- P4553 80人环游世界
题目地址:P4553 80人环游世界 上下界网络流 无源汇上下界可行流 给定 \(n\) 个点, \(m\) 条边的网络,求一个可行解,使得边 \((u,v)\) 的流量介于 \([B(u,v),C( ...