IO在Socket中的应用
一、BIO
在JDK1.4出来之前,我们建立网络连接的时候采用BIO模式,需要先在服务端启动一个ServerSocket,然后在客户端启动Socket来对服务端进行通信,默认情况下服务端需要对每个连接请求建立一堆线程等待其他请求操作,而客户端发送请求后,先咨询服务端是否有线程相应,如果没有则会一直等待或者遭到拒绝请求,如果有的话,客户端连接线程会等待请求结束后才继续执行。
在使用同步I/O的网络应用中,如果要同时处理多个客户端请求,或是在客户端要同时和多个服务器进行通讯,就必须使用多线程来处理。
也就是说,将每一个客户端请求分配给一个线程来单独处理。这样做虽然可以达到我们的要求,但同时又会带来另外一个问题。由于每创建一个线程,就要为这个线程分配一定的内存空间(也叫工作存储器),而且操作系统本身也对线程的总数有一定的限制。如果客户端的请求过多,服务端程序可能会因为不堪重负而拒绝客户端的请求,甚至服务器可能会因此而瘫痪。
缺点1:
每有一个用户请求,就会创建一个新的线程。当用户请求量特别巨大,线程数量要会随之增 大,继而内存的占用增大,所以,不可能适用高并发、高访问的场景。
缺点2:
线程特别多,不仅是占用内存开销,也会占用大量的cpu开销,因为cpu要做线程调度。
缺点3:
如果一个用户仅仅是连入操作,并且长时间不做其他操作,会产生大量的闲置线程。会使cpu 做无意义的空转。降低整体性能
缺点4:
这个模型会导致真正需要被处理的线程(用户请求)不能被及时处理
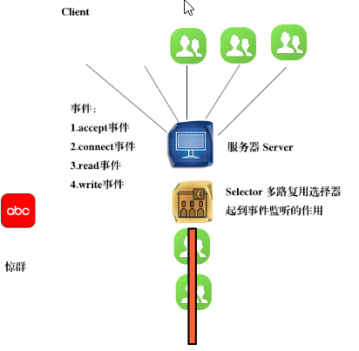
针对缺点3和缺点4,可以将闲置的线程设置为阻塞态,cpu是不会调度阻塞态的线程,避免了cpu的空转。所以引入事件监听机制实现。
Selector多路复用选择器,起到事件监听的作用。
监听哪个用户执行操作,就唤醒对应的线程执行。那么都有哪些事件呢?
事件:1.accept事件、2.connect事件、3.read事件、4.write事件
针对缺点1和缺点2,可以利用非阻塞模型来实现,利用少量线程甚至一个线程来处理多用户请求。但是注意,这个模型是有使用场景的,适用于大量短请求场景。(比如用户访问电商网站),不适合长请求场景(比如下载大文件,这种场景,NIO不见得比BIO好)
二、NIO
NIO本身是基于事件驱动思想来完成的,其主要想解决的是BIO的并发问题:
NIO基于Reactor,当socket有流可读或可写入socket时,操作系统会相应的通知引用程序进行处理,应用再将流读取到缓冲区或写入操作系统。 也就是说,这个时候,已经不是一个连接就要对应一个处理线程了,而是有效的请求,对应一个线程,当连接没有数据时,是没有工作线程来处理的。
BIO与NIO一个比较重要的不同,是我们使用BIO的时候往往会引入多线程,每个连接一个单独的线程;而NIO则是使用单线程或者只使用少量的多线程,每个连接共用一个线程。
selector有两个作用:多路复用和事件监听

NIO的最重要的地方是当一个连接创建后,不需要对应一个线程,这个连接会被注册到多路复用器上面,所以所有的连接只需要一个线程就可以搞定,当这个线程中的多路复用器进行轮询的时候,发现连接上有请求的话,才开启一个线程进行处理,也就是一个请求一个线程模式。
在NIO的处理方式中,当一个请求来的话,开启线程进行处理,可能会等待后端应用的资源(JDBC连接等),其实这个线程就被阻塞了,当并发上来的话,还是会有BIO一样的问题。
HTTP/1.1出现后,有了Http长连接,这样除了超时和指明特定关闭的http header外,这个链接是一直打开的状态的,这样在NIO处理中可以进一步的进化,在后端资源中可以实现资源池或者队列,当请求来的话,开启的线程把请求和请求数据传送给后端资源池或者队列里面就返回,并且在全局的地方保持住这个现场(哪个连接的哪个请求等),这样前面的线程还是可以去接受其他的请求,而后端的应用的处理只需要执行队列里面的就可以了,这样请求处理和后端应用是异步的.当后端处理完,到全局地方得到现场,产生响应,这个就实现了异步处理。

三、AIO
与NIO不同,当进行读写操作时,只须直接调用API的read或write方法即可。这两种方法均为异步的,对于读操作而言,当有流可读取时,操作系统会将可读的流传入read方法的缓冲区,并通知应用程序;对于写操作而言,当操作系统将write方法传递的流写入完毕时,操作系统主动通知应用程序。 即可以理解为,read/write方法都是异步的,完成后会主动调用回调函数。 在JDK1.7中,这部分内容被称作NIO.2,主要在java.nio.channels包下增加了下面四个异步通道:
- AsynchronousSocketChannel
- AsynchronousServerSocketChannel
- AsynchronousFileChannel
- AsynchronousDatagramChannel
其中的read/write方法,会返回一个带回调函数的对象,当执行完读取/写入操作后,直接调用回调函数。
BIO是一个连接一个线程。
NIO是一个请求一个线程。
AIO是一个有效请求一个线程。
先来个例子理解一下概念,以银行取款为例:
- 同步 : 自己亲自出马持银行卡到银行取钱(使用同步IO时,Java自己处理IO读写);
- 异步 : 委托一小弟拿银行卡到银行取钱,然后给你(使用异步IO时,Java将IO读写委托给OS处理,需要将数据缓冲区地址和大小传给OS(银行卡和密码),OS需要支持异步IO操作API);
- 阻塞 : ATM排队取款,你只能等待(使用阻塞IO时,Java调用会一直阻塞到读写完成才返回);
- 非阻塞 : 柜台取款,取个号,然后坐在椅子上做其它事,等号广播会通知你办理,没到号你就不能去,你可以不断问大堂经理排到了没有,大堂经理如果说还没到你就不能去(使用非阻塞IO时,如果不能读写Java调用会马上返回,当IO事件分发器会通知可读写时再继续进行读写,不断循环直到读写完成)
IO在Socket中的应用的更多相关文章
- socket.io 中文手册 中文文档
服务端 io.on('connection',function(socket));//监听客户端连接,回调函数会传递本次连接的socket io.sockets.emit('String',data) ...
- Java socket中关闭IO流后,发生什么事?(以关闭输出流为例)
声明:该博文以socket中,关闭输出流为例进行说明. 为了方便讲解,我们把DataOutputstream dout = new DataOutputStream(new BufferedOutpu ...
- IO创建Socket通信中慎用BufferReader中的readLine()
在编写Socket的Demo的时候,在Server中使用BufferReader获取从客服端发送过来的内容 package cn.lonecloud.socket; import cn.loneclo ...
- Java 中的 IO 与 socket 编程 [ 复习 ]
一.Unix IO 与 IPC Unix IO:Open-Read or Write-Close IPC:open socket - receive and send to socket - clos ...
- 2、 Spark Streaming方式从socket中获取数据进行简单单词统计
Spark 1.5.2 Spark Streaming 学习笔记和编程练习 Overview 概述 Spark Streaming is an extension of the core Spark ...
- IO和socket编程
五一假期结束了,突然想到3周前去上班的路上看到槐花开的正好.放假也没能采些做槐花糕,到下周肯定就老了.一年就开一次的东西,比如牡丹,花期也就一周.而花开之时,玫瑰和月季无法与之相比.明日黄花蝶也愁.想 ...
- IO多路复用丶基于IO多路复用+socket实现并发请求丶协程
一丶IO多路复用 IO多路复用指:通过一种机制,可以监视多个描述符,一旦某个描述符就绪(一般是读就绪或者写就绪),能够通知程序进行相应的读写操作 IO多路复用作用: 检测多个socket是否已经发生变 ...
- 如何解读 Java IO、NIO 中的同步阻塞与同步非阻塞?
原文链接:如何解读 Java IO.NIO 中的同步阻塞与同步非阻塞? 一.前言 最近刚读完一本书:<Netty.Zookeeper.Redis 并发实战>,个人觉得 Netty 部分是写 ...
- ZeroMQ接口函数之 :zmq_msg_recv - 从一个socket中接受一个消息帧
ZeroMQ 官方地址 :http://api.zeromq.org/4-2:zmq_msg_recv zmq_msg_recv(3) ØMQ Manual - ØMQ/3.2.5 Name zmq_ ...
随机推荐
- AD域 组策略部署U软件
1.首先把需要部署的软件放到活动目录共享文件夹中.(只支持MSI格式的软件) 2.打开组策略管理工具. 3.选择域名右键,创建GPO. 4.在弹出的新建GPO窗口中,输入策略名称. 5.在新创建的策略 ...
- P1579哥德巴赫猜想
写来自己学习用~ 题目内容: 1742年6月7日哥德巴赫写信给当时的大数学家欧拉,正式提出了以下的猜想:任何一个大于9的奇数都可以表示成3个质数之和.质数是指除了1和本身之外没有其他约数的数,如2和1 ...
- Integer 函数传参实现值交换
import java.lang.reflect.Field; public class MainClass { public static void main(String[] args) { In ...
- 4-19 css属性
1. margin 简写属性在一个声明中设置所有外边距属性.该属性可以有 1 到 4 个值. 说明 这个简写属性设置一个元素所有外边距的宽度,或者设置各边上外边距的宽度. 块级元素的垂直相邻外边距会合 ...
- 'BAPI_MESSAGE_GETDETAIL' 用法
其中message class是在se91里创建的 call function 'BAPI_MESSAGE_GETDETAIL' exporting id = msg_class “m ...
- 【转】.NET程序员提高效率的70多个开发工具
原文:.NET程序员提高效率的70多个开发工具 工欲善其事,必先利其器,没有好的工具,怎么能高效的开发出高质量的代码呢?本文为各ASP.NET 开发者介绍一些高效实用的工具,涉及SQL 管理,VS插件 ...
- java 将指定文件夹递归的进行zip打包压缩
package tmp.MavenTest; import java.io.BufferedInputStream; import java.io.File; import java.io.FileI ...
- applium安装过程中遇到的问题及解决方法。
1.安装appium server 之后, cmd输入appium-doctor,运行时提示'node'不是内部或外部的命令 一.提示'node'不是内部或外部命令,先按照下面步骤操作: 1.设置 ...
- tmux使用(程序员适用)
原文:http://jack-boy.iteye.com/blog/1586908 tmux基本使用 tmux是一个优秀的终端复用软件,即使非正常掉线,也能保证当前的任务运行,这一点对于远程S ...
- Hbase的基本操作(CDH组件可用)
Habse创建一张表: 1,创建一个命名空间NameSpace(命名空间NameSpace指的是一个表的逻辑分组 ,同一分组中的各个表有类似的用途,相当于关系型数据库中的DataBase) ...