【机器学习】异常检测算法(I)
在给定的数据集,我们假设数据是正常的 ,现在需要知道新给的数据Xtest中不属于该组数据的几率p(X)。
异常检测主要用来识别欺骗,例如通过之前的数据来识别新一次的数据是否存在异常,比如根据一个用户以前的使用习惯(数据)来判断这次使用的用户是不是以前的用户。或者根据之前CPU正常运行时候的的用量数据来判断当前状态下的CPU是否正常工作。
这里我们通过密度估计来进行判断:if P(X) >ε时候,为normal(正常)<ε 的时候为异常 。
我们用x(i)来表示用户的第i个特征,模型P(x)= 我们其属于一组数据的可能性
在这里我们会用到高斯分布(二项分布),在高斯分布中,我们 对于方差通常只除以m来得到μ和σ而不是统计学中的m-1
异常检测算法:
对于给定的数据集x(1)...x(m),我们要针对每一个特征计算出μ和σ的估计值。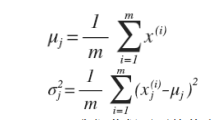
一旦我们获得了平均值和方差的估计值,给定的一个新的训练实例,根据模型计算我们就可以得出p(x)

我们选择一个 ε,将p(x)=ε作为我们的判定边界,当p(x)> ε的时候预测数据为正常数据,否则为异常数据。
异常检测算是一个非监督学习算法,这意味着我们无法根据结果变量Y 的值来告诉我们是否异常,我们可以从带标记的数据着手,选取一部分正常的数据用来训练和构建,然后用剩下的正常样本和测试样本混合构成交叉检验集和测试集。
在这里我们举一个栗子,用来更详细的描述异常检测算法。
例如:我们有 10000 台正常引擎的数据,有 20 台异常引擎的数据。 我们这样分配数
据:
6000 台正常引擎的数据作为训练集
2000 台正常引擎和 10 台异常引擎的数据作为交叉检验集
2000 台正常引擎和 10 台异常引擎的数据作为测试集
具体的评价方法如下:
1. 根据测试集数据,我们估计特征的平均值和方差并构建 p(x)函数
2. 对交叉检验集,我们尝试使用不同的 ε 值作为阀值,并预测数据是否异常,根据 F1
值或者查准率与查全率的比例来选择 ε
3. 选出 ε 后,针对测试集进行预测,计算异常检验系统的 F1 值, 或者查准率与查全
率之比
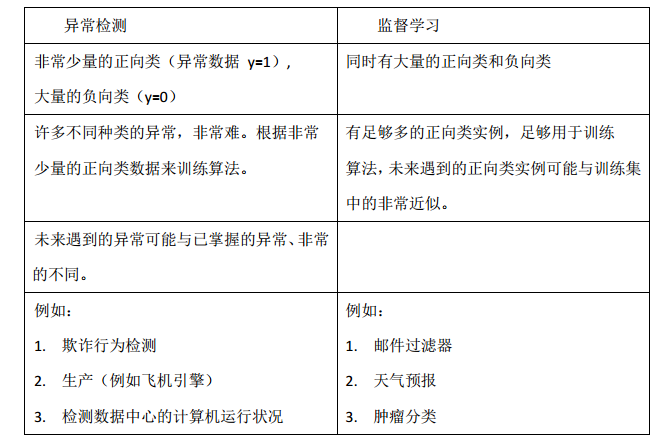
之前我们构建的异常检测系统也使用了带标记的数据,与监督学习有些相似,下面的对
比有助于选择采用监督学习还是异常检测:
两者比较:
【机器学习】异常检测算法(I)的更多相关文章
- 机器学习:异常检测算法Seasonal Hybrid ESD及R语言实现
Twritters的异常检测算法(Anomaly Detection)做的比较好,Seasonal Hybrid ESD算法是先用STL把序列分解,考察残差项.假定这一项符合正态分布,然后就可以用Ge ...
- kaggle信用卡欺诈看异常检测算法——无监督的方法包括: 基于统计的技术,如BACON *离群检测 多变量异常值检测 基于聚类的技术;监督方法: 神经网络 SVM 逻辑回归
使用google翻译自:https://software.seek.intel.com/dealing-with-outliers 数据分析中的一项具有挑战性但非常重要的任务是处理异常值.我们通常将异 ...
- 异常检测算法--Isolation Forest
南大周志华老师在2010年提出一个异常检测算法Isolation Forest,在工业界很实用,算法效果好,时间效率高,能有效处理高维数据和海量数据,这里对这个算法进行简要总结. iTree 提到森林 ...
- 异常检测算法:Isolation Forest
iForest (Isolation Forest)是由Liu et al. [1] 提出来的基于二叉树的ensemble异常检测算法,具有效果好.训练快(线性复杂度)等特点. 1. 前言 iFore ...
- 如何开发一个异常检测系统:使用什么特征变量(features)来构建异常检测算法
如何构建与选择异常检测算法中的features 如果我的feature像图1所示的那样的正态分布图的话,我们可以很高兴地将它送入异常检测系统中去构建算法. 如果我的feature像图2那样不是正态分布 ...
- 异常检测(Anomaly detection): 异常检测算法(应用高斯分布)
估计P(x)的分布--密度估计 我们有m个样本,每个样本有n个特征值,每个特征都分别服从不同的高斯分布,上图中的公式是在假设每个特征都独立的情况下,实际无论每个特征是否独立,这个公式的效果都不错.连乘 ...
- 异常检测算法的Octave仿真
在基于高斯分布的异常检测算法一文中,详细给出了异常检测算法的原理及其公式,本文为该算法的Octave仿真.实例为,根据训练样例(一组网络服务器)的吞吐量(Throughput)和延迟时间(Latenc ...
- 异常检测算法Robust Random Cut Forest(RRCF)关键定理引理证明
摘要:RRCF是亚马逊发表的一篇异常检测算法,是对周志华孤立森林的改进.但是相比孤立森林,具有更为扎实的理论基础.文章的理论论证相对较为晦涩,且没给出详细的证明过程.本文不对该算法进行详尽的描述,仅对 ...
- 时间序列异常检测算法S-H-ESD
1. 基于统计的异常检测 Grubbs' Test Grubbs' Test为一种假设检验的方法,常被用来检验服从正太分布的单变量数据集(univariate data set)\(Y\) 中的单个异 ...
随机推荐
- SpringCloud系列五:Ribbon 负载均衡(Ribbon 基本使用、Ribbon 负载均衡、自定义 Ribbon 配置、禁用 Eureka 实现 Ribbon 调用)
1.概念:Ribbon 负载均衡 2.具体内容 现在所有的服务已经通过了 Eureka 进行了注册,那么使用 Eureka 注册的目的是希望所有的服务都统一归属到 Eureka 之中进 行处理,但是现 ...
- vue keep-alive 原理
前人种树:https://segmentfault.com/a/1190000011978825 add : 使用 keep-alive 组件后,组件生命周期会新引入两个钩子
- Innodb引擎中Count(*)
select count(*)是MySQL中用于统计记录行数最常用的方法,count方法可以返回表内精确的行数. 在某些索引下是好事,但是如果表中有主键,count(*)的速度就会很慢,特别在千万记录 ...
- java将错误信息写入文件
第一种办法可以通过字符串,也就是先把错误信息写入字符串,再将字符串写入文件 import java.io.*; public class Demo { public static void main( ...
- ubuntu16中部署web项目到tomcat,xft和securecrt连接到ubuntu16(待续。。。)
xftp xftp中新建连接 ubuntu中安装和启动ssh服务 xftp连接到ubuntu 安装JDK,Tomcat sudo tar -zvxf jdk.tar.gz ...
- 前端面试之Javascript
1,JS基本的数据类型和引用类型: (1)基本数据类型:number,string,null,undefined,symbol--栈: (2)引用数据类型:object,array,function- ...
- R语言-图形辅助
1.画底纹格子 grid()函数 > plot(rnorm(100)) > grid() #画底纹格子 > grid(nx=NA, ny=8, #画水平底纹,横坐标无分隔,纵坐 ...
- Loadrunner进行HTTPS协议性能测试
1.最简单办法就是在脚本前面加上:web_set_sockets_option("SSL_VERSION","TLS"),一般能解决HTTPS协议的请求问题,无 ...
- API权限设计总结
最近在做API的权限设计这一块,做一次权限设计的总结. 1. 假设我们需要访问的API接口是这样的:http://xxxx.com/openapi/v1/get/user/?key=xxxxx& ...
- std::remove_reference
[std::remove_reference] 用于移除类型的引用,返回原始类型. 1.可能的实现. 2.例子. #include <iostream> // std::cout #inc ...