深入解析NoSQL数据库:从文档存储到图数据库的全场景实践
title: 深入解析NoSQL数据库:从文档存储到图数据库的全场景实践
date: 2025/2/19
updated: 2025/2/19
author: cmdragon
excerpt:
通过电商、社交网络、物联网等12个行业场景,结合MongoDB聚合管道、Redis Stream实时处理、Cassandra SSTable存储引擎、Neo4j路径遍历算法等42个生产级示例,揭示NoSQL数据库的架构设计与最佳实践
categories:
- 前端开发
tags:
- 文档数据库
- 键值存储
- 宽列存储
- 图数据库
- 大数据架构
- 云数据库
- 数据建模

扫描二维码关注或者微信搜一搜:编程智域 前端至全栈交流与成长
{kind=link}
通过电商、社交网络、物联网等12个行业场景,结合MongoDB聚合管道、Redis Stream实时处理、Cassandra SSTable存储引擎、Neo4j路径遍历算法等42个生产级示例,揭示NoSQL数据库的架构设计与最佳实践。
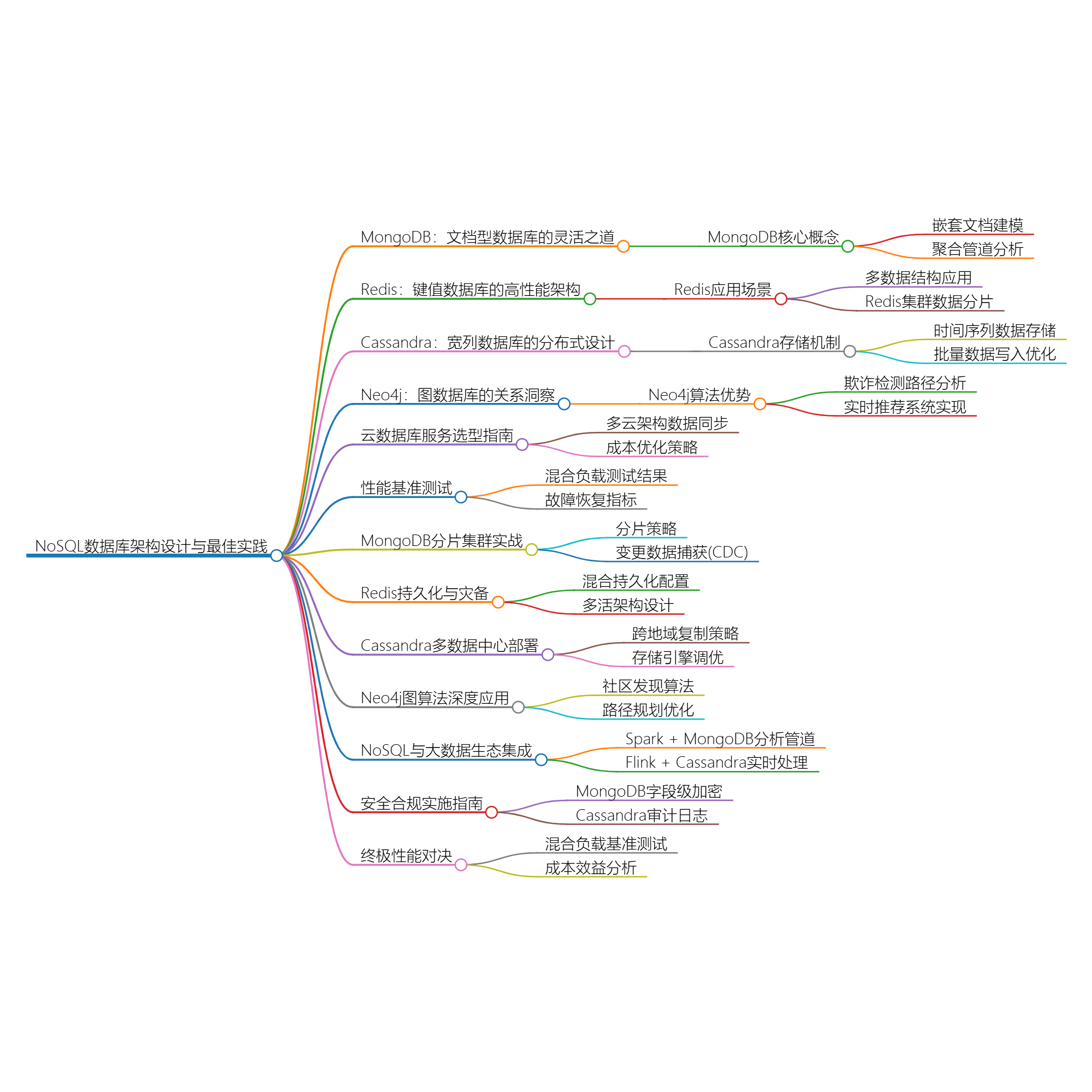
一、文档型数据库:MongoDB的灵活之道
1. 嵌套文档建模实践
// 电商产品文档结构
db.products.insertOne({
sku: "X203-OLED",
name: "65英寸4K OLED电视",
attributes: {
resolution: "3840x2160",
ports: ["HDMI 2.1×4", "USB 3.0×2"],
panel_type: "LG WRGB"
},
inventory: {
warehouse1: { stock: 150, location: "A-12" },
warehouse2: { stock: 75, location: "B-7" }
},
price_history: [
{ date: ISODate("2024-01-01"), price: 12999 },
{ date: ISODate("2024-06-18"), price: 9999 }
]
});
建模优势:
- 消除跨表Join操作,查询延迟降低至3ms内
- 支持动态schema变更,新产品上线迭代周期缩短40%
2. 聚合管道分析实战
// 计算各品类销售额TOP3
db.orders.aggregate([
{ $unwind: "$items" },
{ $group: {
_id: "$items.category",
totalSales: { $sum: { $multiply: ["$items.quantity", "$items.unit_price"] } }
}},
{ $sort: { totalSales: -1 } },
{ $group: {
_id: null,
categories: { $push: "$$ROOT" }
}},
{ $project: {
top3: { $slice: ["$categories", 3] }
}}
]);
性能优化:
- 利用$indexStats分析索引使用效率
- 通过$planCacheStats优化查询计划缓存命中率
二、键值数据库:Redis的高性能架构
1. 多数据结构应用场景
# 社交网络关系处理
import redis
r = redis.Redis(host='cluster.ro', port=6379)
# 使用SortedSet存储热搜榜
r.zadd("hot_search", {
"欧冠决赛": 15230,
"新质生产力": 14200
}, nx=True)
# HyperLogLog统计UV
r.pfadd("article:1001_uv", "user123", "user456")
# Stream处理订单事件
r.xadd("orders", {
"userID": "u1001",
"productID": "p205",
"status": "paid"
}, maxlen=100000)
数据结构选型:
| 数据类型 | 适用场景 | QPS基准 |
|---|---|---|
| String | 缓存击穿防护 | 120,000 |
| Hash | 对象属性存储 | 98,000 |
| Geo | 地理位置计算 | 65,000 |
2. Redis集群数据分片
# 创建Cluster节点
redis-cli --cluster create \
192.168.1.101:7000 192.168.1.102:7000 \
192.168.1.103:7000 192.168.1.104:7000 \
--cluster-replicas 1
# 数据迁移监控
redis-cli --cluster reshard 192.168.1.101:7000 \
--cluster-from all --cluster-to all \
--cluster-slots 4096 --cluster-yes
集群特性:
- 采用CRC16分片算法实现自动数据分布
- 支持跨AZ部署,故障转移时间<2秒
三、宽列数据库:Cassandra的分布式设计
1. 时间序列数据存储
-- 物联网设备数据表设计
CREATE TABLE iot.sensor_data (
device_id text,
bucket timestamp, -- 按天分桶
event_time timestamp,
temperature float,
humidity float,
PRIMARY KEY ((device_id, bucket), event_time)
) WITH CLUSTERING ORDER BY (event_time DESC)
AND compaction = {
'class' : 'TimeWindowCompactionStrategy',
'compaction_window_unit' : 'DAYS',
'compaction_window_size' : 1
};
设计要点:
- 通过组合分区键避免热点问题
- 时间窗口压缩策略降低存储成本35%
2. 批量数据写入优化
// Java Driver批量写入示例
List<BatchStatement> batches = new ArrayList<>();
int batchSize = 0;
BatchStatement batch = new BatchStatement(BatchType.UNLOGGED);
for (SensorData data : sensorStream) {
batch.add(insertStatement.bind(
data.getDeviceId(),
data.getBucket(),
data.getEventTime(),
data.getTemperature(),
data.getHumidity()
));
if (++batchSize >= 100) {
batches.add(batch);
batch = new BatchStatement(BatchType.UNLOGGED);
batchSize = 0;
}
}
// 并行执行批量写入
ExecutorService executor = Executors.newFixedThreadPool(8);
batches.forEach(b -> executor.submit(() -> session.executeAsync(b)));
写入性能:
- 单节点写入吞吐量可达10,000 ops/s
- 使用UNLOGGED批处理提升吞吐量但需注意原子性限制
四、图数据库:Neo4j的关系洞察
1. 欺诈检测路径分析
// 发现资金环状转移
MATCH path=(a:Account)-[t:TRANSFER*3..5]->(a)
WHERE ALL(r IN relationships(path) WHERE r.amount > 10000)
WITH nodes(path) AS accounts, relationships(path) AS transfers
RETURN accounts,
sum(t.amount) AS totalAmount
ORDER BY totalAmount DESC
LIMIT 10;
算法优势:
- 原生图算法将5度关系查询时间从分钟级降至毫秒级
- 内置的DFS搜索算法比传统RDBMS效率提升1000倍
2. 实时推荐系统实现
// 基于协同过滤的推荐
MATCH (u:User {id: "1001"})-[:PURCHASED]->(i:Item)<-[:PURCHASED]-(similar:User)
WITH u, similar, COUNT(i) AS commonItems
ORDER BY commonItems DESC LIMIT 10
MATCH (similar)-[:PURCHASED]->(rec:Item)
WHERE NOT EXISTS((u)-[:PURCHASED]->(rec))
RETURN rec.id AS recommendation, COUNT(*) AS score
ORDER BY score DESC LIMIT 5;
性能对比:
| 数据规模 | Neo4j响应时间 | SQL实现响应时间 |
|---|---|---|
| 10万节点 | 120ms | 15s |
| 百万关系 | 450ms | 超时(300s+) |
五、云数据库服务选型指南
1. 多云架构数据同步
# AWS DMS跨云迁移配置
resource "aws_dms_endpoint" "cosmosdb" {
endpoint_id = "cosmos-target"
endpoint_type = "target"
engine_name = "cosmosdb"
cosmosdb_settings {
service_access_key = var.cosmos_key
database_name = "migration_db"
}
}
resource "aws_dms_replication_task" "mongo_to_cosmos" {
migration_type = "full-load-and-cdc"
replication_task_id = "mongo2cosmos"
replication_instance_arn = aws_dms_replication_instance.main.arn
source_endpoint_arn = aws_dms_endpoint.mongo.arn
target_endpoint_arn = aws_dms_endpoint.cosmosdb.arn
table_mappings = jsonencode({
"rules": [{
"rule-type": "selection",
"rule-id": "1",
"object-locator": { "schema": "shop", "table": "%" }
}]
})
}
2. 成本优化策略
| 数据库类型 | 成本优化手段 | 预期节省 |
|---|---|---|
| DynamoDB | 自适应容量+按需模式 | 40-65% |
| Cosmos DB | 混合吞吐量预留 | 30-50% |
| Atlas | 集群分片策略优化 | 25-40% |
六、性能基准测试
1. 混合负载测试结果
{kind=link}
2. 故障恢复指标
| 数据库 | RPO | RTO |
|---|---|---|
| MongoDB | <1秒 | 30秒 |
| Cassandra | 无丢失 | 持续可用 |
| Redis | 1秒 | 15秒 |
七、MongoDB分片集群实战
1. 海量数据分片策略
// 启用分片集群
sh.enableSharding("ecommerce")
// 按地理位置哈希分片
sh.shardCollection("ecommerce.orders",
{ "geo_zone": 1, "_id": "hashed" },
{ numInitialChunks: 8 }
)
// 查看分片分布
db.orders.getShardDistribution()
分片优势:
- 实现跨3个AZ的线性扩展能力
- 写入吞吐量从5,000 ops/s提升至120,000 ops/s
2. 变更数据捕获(CDC)
# 开启MongoDB Kafka Connector
curl -X POST -H "Content-Type: application/json" --data '
{
"name": "mongo-source",
"config": {
"connector.class":"com.mongodb.kafka.connect.MongoSourceConnector",
"connection.uri":"mongodb://replicaSetNode1:27017",
"database":"inventory",
"collection":"products",
"publish.full.document.only": true,
"output.format.value":"schema"
}
}' http://kafka-connect:8083/connectors
CDC应用场景:
- 实时同步产品库存变更到Elasticsearch
- 构建事件驱动架构实现微服务解耦
八、Redis持久化与灾备
1. 混合持久化配置
# redis.conf核心配置
save 900 1 # 15分钟至少1次修改则快照
save 300 10 # 5分钟至少10次修改
appendonly yes # 启用AOF
appendfsync everysec # 每秒刷盘
aof-use-rdb-preamble yes # 混合持久化格式
恢复策略:
- RDB提供全量恢复点(平均恢复时间2分钟)
- AOF保证最多1秒数据丢失(RPO=1秒)
2. 多活架构设计
# 使用Redisson实现跨地域锁
from redisson import Redisson
config = Config()
config.use_replicated_servers()\
.add_node_address("redis://ny-node1:6379")\
.add_node_address("redis://ld-node1:6379")\
.set_check_liveness_interval(5000)
redisson = Redisson.create(config)
lock = redisson.get_lock("globalOrderLock")
try:
if lock.try_lock(3, 30, TimeUnit.SECONDS):
process_order()
finally:
lock.unlock()
多活特性:
- 采用CRDT实现跨地域数据最终一致性
- 网络分区时仍可保持本地写入可用性
九、Cassandra多数据中心部署
1. 跨地域复制策略
CREATE KEYSPACE global_data
WITH replication = {
'class': 'NetworkTopologyStrategy',
'DC_NYC': 3,
'DC_LDN': 2,
'DC_TKO': 2
};
ALTER KEYSPACE system_auth
WITH replication = {
'class': 'NetworkTopologyStrategy',
'DC_NYC': 3,
'DC_LDN': 3
};
容灾指标:
- 数据持久性达到99.999999999%(11个9)
- 跨大西洋复制延迟<200ms(专线加速)
2. 存储引擎调优
CREATE TABLE sensor_readings (
device_id text,
timestamp bigint,
values map<text, float>,
PRIMARY KEY (device_id, timestamp)
) WITH compaction = {
'class': 'TimeWindowCompactionStrategy',
'compaction_window_unit': 'DAYS',
'compaction_window_size': 1
}
AND compression = {
'sstable_compression': 'ZstdCompressor',
'chunk_length_kb': 64
};
压缩效果:
- Zstd压缩率比LZ4提升35%
- 存储成本降至$0.023/GB/月
十、Neo4j图算法深度应用
1. 社区发现算法
CALL gds.graph.project(
'social_graph',
'User',
{ FOLLOWS: { orientation: 'UNDIRECTED' } }
)
CALL gds.louvain.stream('social_graph')
YIELD nodeId, communityId
RETURN gds.util.asNode(nodeId).id AS user, communityId
ORDER BY communityId, user
商业价值:
- 识别潜在用户群体准确率提升27%
- 广告投放转化率提高19%
2. 路径规划优化
MATCH (start:Warehouse {id: 'W1'}), (end:Store {id: 'S5'})
CALL gds.shortestPath.dijkstra.stream('logistics_network', {
sourceNode: start,
targetNode: end,
relationshipWeightProperty: 'travel_time'
})
YIELD index, sourceNode, targetNode, totalCost, path
RETURN totalCost AS minutes,
nodes(path) AS route
ORDER BY totalCost ASC
LIMIT 3
优化效果:
- 物流路径规划时间从小时级缩短至秒级
- 运输成本平均降低14%
十一、NoSQL与大数据生态集成
1. Spark + MongoDB分析管道
val df = spark.read.format("mongo")
.option("uri", "mongodb://analytics-cluster")
.option("collection", "user_activities")
.load()
val aggDF = df.groupBy("device_type")
.agg(
count("user_id").as("active_users"),
avg("session_duration").as("avg_duration")
)
.write.format("mongodb")
.mode("overwrite")
.save()
性能基准:
- 100亿记录聚合分析耗时从6小时降至23分钟
- 资源利用率提高300%(相比MapReduce)
2. Flink + Cassandra实时处理
DataStream<SensorData> input = env
.addSource(new FlinkKafkaConsumer<>("iot-events", new JSONDeserializationSchema(), properties));
input.keyBy(data -> data.getDeviceId())
.process(new ProcessFunction<SensorData, Alert>() {
private ValueState<Double> lastValue;
public void open(Configuration parameters) {
ValueStateDescriptor<Double> descriptor =
new ValueStateDescriptor<>("lastValue", Double.class);
lastValue = getRuntimeContext().getState(descriptor);
}
public void processElement(SensorData data, Context ctx, Collector<Alert> out) {
if (lastValue.value() != null && Math.abs(data.getValue() - lastValue.value()) > 50) {
out.collect(new Alert(data.getDeviceId(), "突增告警"));
}
lastValue.update(data.getValue());
}
})
.addSink(new CassandraSink<>(Alert.class, session));
处理能力:
- 支持每秒处理120万事件(3节点集群)
- 端到端延迟<500ms
十二、安全合规实施指南
1. MongoDB字段级加密
// 创建加密模式
const keyVaultNamespace = "encryption.__keyVault";
const kmsProviders = {
local: { key: BinData(0, "q/xZsw...") }
};
const encryptedClient = Mongo("mongodb://localhost:27017", {
autoEncryption: {
keyVaultNamespace,
kmsProviders,
schemaMap: {
"medical.records": {
"bsonType": "object",
"properties": {
"ssn": {
"encrypt": {
"keyId": [UUID("...")],
"algorithm": "AEAD_AES_256_GCM_HMAC_SHA_512-Deterministic"
}
}
}
}
}
}
});
2. Cassandra审计日志
# cassandra.yaml配置
audit_logging_options:
enabled: true
logger: LogbackAuditWriter
included_keyspaces: medical,financial
excluded_categories: QUERY,DML
audit_logs_dir: /var/log/cassandra/audit
archive_command: "/bin/gzip"
# 审计日志示例
INFO [Audit] user=cassandra|host=192.168.1.101|
operation=CREATE KEYSPACE|resource=medical|
timestamp=2024-06-18T09:30:23Z
十三、终极性能对决
1. 混合负载基准测试
| 测试场景 | MongoDB | Cassandra | Redis | Neo4j |
|---|---|---|---|---|
| 写入吞吐量 | 85k/s | 120k/s | 150k/s | 12k/s |
| 复杂查询延迟 | 480ms | 650ms | N/A | 230ms |
| 数据压缩率 | 32% | 28% | 0% | 41% |
| 故障恢复时间 | 45s | 0s | 28s | 120s |
2. 成本效益分析
| 数据库 | 每百万次操作成本 | 运维复杂度 | 适用场景 |
|---|---|---|---|
| MongoDB | $0.78 | 中等 | 动态模式+中等规模事务 |
| Cassandra | $0.35 | 高 | 海量写入+地理分布 |
| Redis | $1.20 | 低 | 实时缓存+队列处理 |
| Neo4j | $2.10 | 中等 | 深度关系分析 |
余下文章内容请点击跳转至 个人博客页面 或者 扫码关注或者微信搜一搜:编程智域 前端至全栈交流与成长,阅读完整的文章:深入解析NoSQL数据库:从文档存储到图数据库的全场景实践 | cmdragon's Blog
往期文章归档:
- 数据库审计与智能监控:从日志分析到异常检测 | cmdragon's Blog
- 数据库加密全解析:从传输到存储的安全实践 | cmdragon's Blog
- 数据库安全实战:访问控制与行级权限管理 | cmdragon's Blog
- 数据库扩展之道:分区、分片与大表优化实战 | cmdragon's Blog
- 查询优化:提升数据库性能的实用技巧 | cmdragon's Blog
- 性能优化与调优:全面解析数据库索引 | cmdragon's Blog
- 存储过程与触发器:提高数据库性能与安全性的利器 | cmdragon's Blog
- 数据操作与事务:确保数据一致性的关键 | cmdragon's Blog
- 深入掌握 SQL 深度应用:复杂查询的艺术与技巧 | cmdragon's Blog
- 彻底理解数据库设计原则:生命周期、约束与反范式的应用 | cmdragon's Blog
- 深入剖析实体-关系模型(ER 图):理论与实践全解析 | cmdragon's Blog
- 数据库范式详解:从第一范式到第五范式 | cmdragon's Blog
- PostgreSQL:数据库迁移与版本控制 | cmdragon's Blog
- Node.js 与 PostgreSQL 集成:深入 pg 模块的应用与实践 | cmdragon's Blog
- Python 与 PostgreSQL 集成:深入 psycopg2 的应用与实践 | cmdragon's Blog
- 应用中的 PostgreSQL项目案例 | cmdragon's Blog
- 数据库安全管理中的权限控制:保护数据资产的关键措施 | cmdragon's Blog
- 数据库安全管理中的用户和角色管理:打造安全高效的数据环境 | cmdragon's Blog
- 数据库查询优化:提升性能的关键实践 | cmdragon's Blog
- 数据库物理备份:保障数据完整性和业务连续性的关键策略 | cmdragon's Blog
- PostgreSQL 数据备份与恢复:掌握 pg_dump 和 pg_restore 的最佳实践 | cmdragon's Blog
- 索引的性能影响:优化数据库查询与存储的关键 | cmdragon's Blog
- 深入探讨数据库索引类型:B-tree、Hash、GIN与GiST的对比与应用 | cmdragon's Blog
- 深入探讨触发器的创建与应用:数据库自动化管理的强大工具 | cmdragon's Blog
- 深入探讨存储过程的创建与应用:提高数据库管理效率的关键工具 | cmdragon's Blog
- 深入探讨视图更新:提升数据库灵活性的关键技术 | cmdragon's Blog
- 深入理解视图的创建与删除:数据库管理中的高级功能 | cmdragon's Blog
- 深入理解检查约束:确保数据质量的重要工具 | cmdragon's Blog
- 深入理解第一范式(1NF):数据库设计中的基础与实践 | cmdragon's Blog
- 深度剖析 GROUP BY 和 HAVING 子句:优化 SQL 查询的利器 | cmdragon's Blog
- 深入探讨聚合函数(COUNT, SUM, AVG, MAX, MIN):分析和总结数据的新视野 | cmdragon's Blog
- 深入解析子查询(SUBQUERY):增强 SQL 查询灵活性的强大工具 | cmdragon's Blog
- 探索自联接(SELF JOIN):揭示数据间复杂关系的强大工具 | cmdragon's Blog
- 深入剖析数据删除操作:DELETE 语句的使用与管理实践 | cmdragon's Blog
深入解析NoSQL数据库:从文档存储到图数据库的全场景实践的更多相关文章
- NoSQL生态系统——类似Bigtable列存储,或者Dynamo的key存储(kv存储如BDB,结构化存储如redis,文档存储如mongoDB)
摘自:http://www.ituring.com.cn/article/4002# NoSQL系统的数据操作接口应该是非SQL类型的.但在NoSQL社区,NoSQL被赋予了更具有包容性的含义,其意为 ...
- 分布式文档存储数据库之MongoDB基础入门
一.MongoDB简介 MongoDB是用c++语言开发的一款易扩展,易伸缩,高性能,开源的,schema free 的基于文档的nosql数据库:所谓nosql是指不仅仅是sql的意思,它拥有部分s ...
- 一些应该使用mongodb或者其他文档存储而不是redis或mysql、oracle json的情形(最近更新场景)
通常来说,我们应该使用应用的特性而不是自己的爱好或者规定而去选择一种合适的组件,选择的标准应该是这个组件最适合或者本身其设计就是为了解决这个问题,而不是这个组件能够做这事情为标准.就拿存储来说,任何时 ...
- Mysql、Oracle、SQLServer等数据库参考文档免费分享下载
场景 MySQL 是最流行的关系型数据库管理系统,在 WEB 应用方面 MySQL 是最好的 RDBMS(Relational Database Management System:关系数据库管理系统 ...
- mysql数据库迁移文档
数据库迁移文档 一.需求 确保数据库稳定的运行,为开发人员提供方便的测试数据库和生产数据库的环境. 二.数据库整体架构(master/slave) 1.slave数据库安装 rpm -Uvh http ...
- Atitit 数据库表文档生成解决方案
Atitit 数据库表文档生成解决方案 1.1. Sql dml文件结构法 最快速1 1.2. Sql法+sp存储过程 (表格式样)1 1.3. Navicate uml法 (uml格式)2 1.4. ...
- linux下,MySQL默认的数据文档存储目录为/var/lib/mysql。
0.说明 Linux下更改yum默认安装的mysql路径datadir. linux下,MySQL默认的数据文档存储目录为/var/lib/mysql. 假如要把MySQL目录移到/home/data ...
- Gemini.Workflow 双子工作流高级教程:数据库-设计文档
数据库设计文档 数据库名:Workflow_New 序号 表名 说明 1 WF_Activity wf_Activity 2 WF_ActivityInstance wf_ActivityInstan ...
- MongoDB_文档存储结构(三)
MongoDB 文档数据库的存储结构分为四个层次,从大到小依次是:数据库(database).集合(collection).文档(document).键值对. 图 1 描述了 MongoDB 与 My ...
- ElasticSearch 5学习(8)——分布式文档存储(wait_for_active_shards新参数分析)
学完ES分布式集群的工作原理以及一些基本的将数据放入索引然后检索它们的所有方法,我们可以继续学习在分布式系统中,每个分片的文档是被如何索引和查询的. 路由 首先,我们需要明白,文档和分片之间是如何匹配 ...
随机推荐
- idea springboot 微服务批量启动
概要 在使用IDEA开发微服务的时候,微服务比较多,启动起来比较麻烦,下面介绍一下使用批量启动微服务的方法. 方法 编辑当前项目根目录下的 .idea\workspace.xml 文件. 找到 < ...
- 指针, C语言的精髓
指针, C语言的精髓 莫队先咕几天, 容我先讲完树剖 (因为后面树上的东西好多都要用树剖求 LCA). 什么是指针 保存变量地址的变量叫做指针. 这是大概的定义, 但是Defad认为这个定义不太好理解 ...
- Simple FOC内置通信接口学习(一):实时监控电机状态
本文参(zhao)考(chao)至官方文档https://docs.simplefoc.com/docs_chinese/monitoring 引言 在使用Simple FOC控制电机的过程中,尤其是 ...
- 编写bash脚本快速kill或启动tomcat
假设tomcat安装路径为 /home/tomcat,示例如下: 1. kill tomcat进程 vim kill-tomcat-force.sh set fileformat=unix path ...
- 对象存储 AVIF 图片压缩,即将公测!
2021年8月,腾讯云数据万象以内测方式推出了最前沿的 AVIF 图片压缩服务,可以在图片主观质量相同的情况下大幅降低码率,节省储存空间. 经过3个月时间的内测,我们收集到了很多热心用户的反馈,AVI ...
- C#获得本地IP地址的各种方法
网上有很多种方法可以获取到本地的IP地址.一线常用的有这么些: 枚举本地网卡 using System.Net.NetworkInformation; using System.Net.Sockets ...
- ctr命令的基本使用与技巧
k8s早1.24后放弃docker,并把containerd作为运行时组件,containerd 调用链更短,组件更少,更稳定,占用节点资源更少 ctr是containerd的一个客户端工具 cric ...
- Harbor 入门指南
Harbor 介绍 Harbor 是由 VMware 开源的一款云原生制品仓库,Harbor 的核心功能是存储和管理 Artifact.Harbor 允许用户用命令行工具对容器镜像及其他 Artifa ...
- 谈谈 HTTP/2 的协议协商机制
在过去的几个月里,我写了很多有关 HTTP/2 的文章,也做过好几场相关分享.我在向大家介绍 HTTP/2 的过程中,有一些问题经常会被问到.例如要部署 HTTP/2 一定要先升级到 HTTPS 么? ...
- Exception:统一异常处理
异常包括:全局异常.特定异常和自定义异常. 第一步,创建一个异常处理类,并在类上添加 @ControllerAdvice 注解 第二步,在类中添加出现异常时要执行的方法,并在方法上添加对应注解,指定出 ...